Il s’agit d’un notebook interactif. Vous pouvez l’exécuter en local ou utiliser les liens ci-dessous :
Prérequis
1. Créez et itérez des prompts avec Weave
2. Obtenir le jeu de données
base64, ce qui signifie que les données peuvent être utilisées par le LLM sans prétraitement.
3. Construire le pipeline NER
- Une fonction
encode_imagequi prend une image PIL du jeu de données et renvoie une chaîne représentant l’image encodée enbase64, pouvant être transmise au VLM - Une fonction
extract_named_entities_from_imagequi prend une image et un prompt système, et renvoie les entités extraites de cette image conformément au prompt système
named_entity_recognation qui :
- Envoie les données de l’image au pipeline NER
- Renvoie un JSON correctement formaté avec les résultats
décorateur @weave.op() pour suivre et tracer automatiquement l’exécution de la fonction dans l’interface W&B.
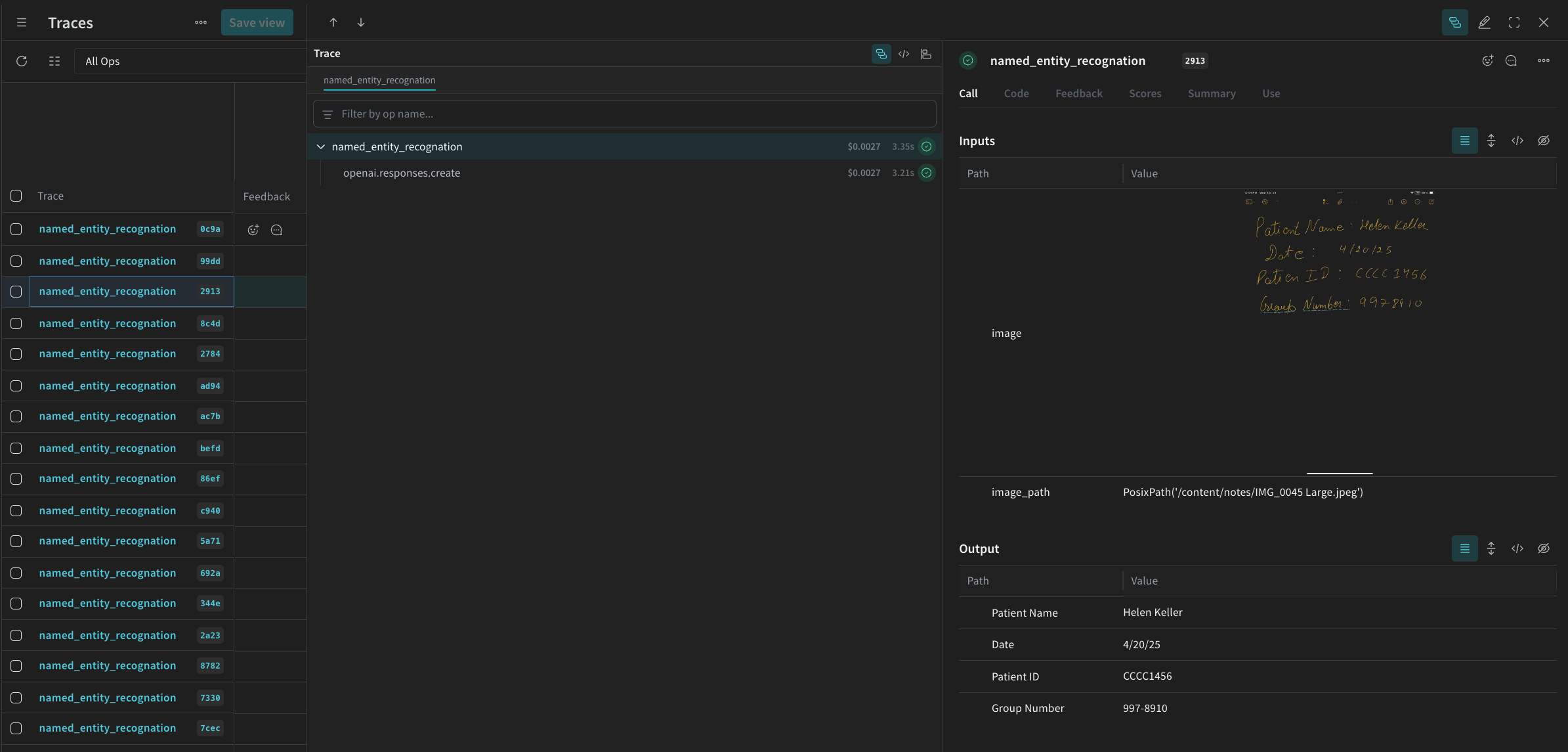
À chaque exécution de named_entity_recognation, les résultats complets de la trace sont visibles dans la Weave UI. Pour voir les traces, accédez à l’onglet Traces de votre projet Weave.
processing_results.json. Les résultats sont également consultables dans Weave UI.
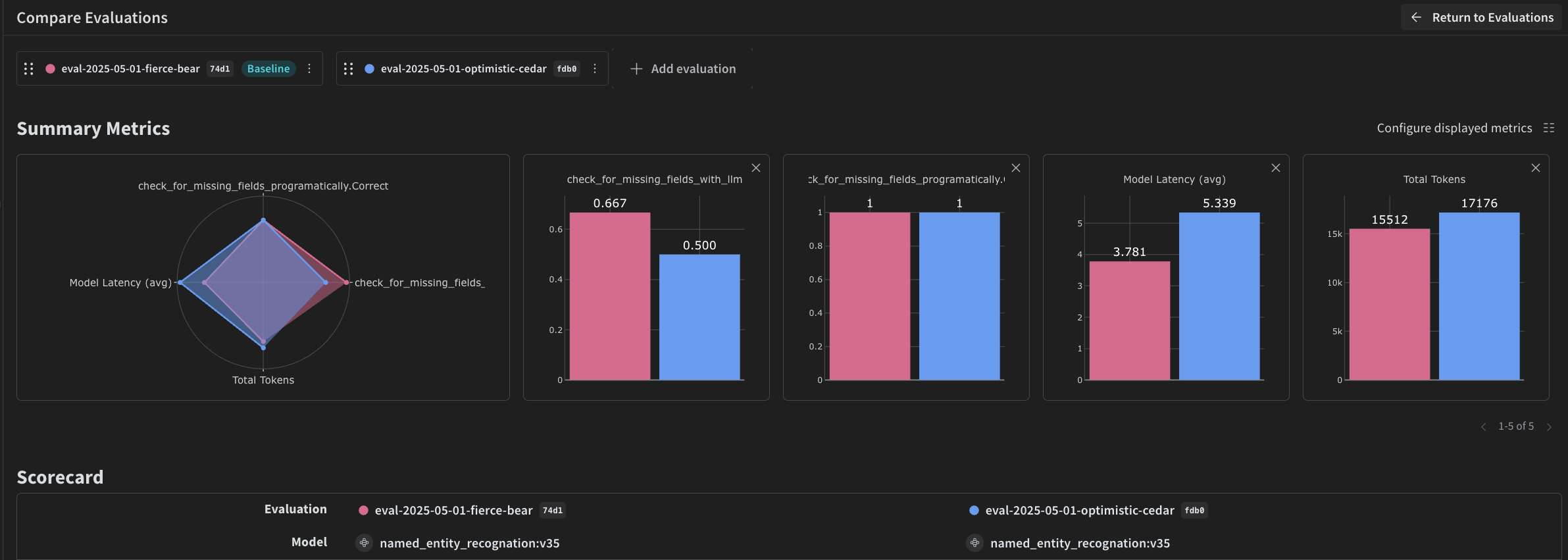
4. Évaluer le pipeline avec Weave
- Évaluateur programmatique
- Évaluateur LLM-as-a-judge
Scorer programmatique
check_for_missing_fields_programatically, prend la sortie du modèle (la sortie de la fonction named_entity_recognition) et identifie quelles keys sont manquantes ou vides dans les résultats.
Cette vérification est particulièrement utile pour repérer les échantillons où le modèle n’a extrait aucun champ.
LLM-as-a-judge scorer
check_for_missing_fields_with_llm, utilise un LLM pour effectuer le scoring (plus précisément le gpt-4o d’OpenAI). Comme indiqué dans le contenu de eval_prompt, check_for_missing_fields_with_llm renvoie une valeur Boolean. Si tous les champs correspondent aux informations de l’image et que le formatage est correct, le scorer renvoie true. Si un champ est manquant, vide, incorrect ou ne correspond pas aux informations attendues, le résultat est false, et le scorer renvoie également un message expliquant le problème.
5. Lancer l’Évaluation
dataset transmis et enregistrera les résultats dans la Weave UI.
Le code suivant lance l’évaluation et applique les deux évaluateurs à chaque sortie du pipeline NER. Les résultats sont visibles dans l’onglet Evals de la Weave UI.