Il s’agit d’un notebook interactif. Vous pouvez l’exécuter localement ou utiliser les liens ci-dessous : Optimiser les flux de travail LLM à l’aide de DSPy et Weave
Installation des dépendances
- DSPy pour construire le flux de travail LLM et l’optimiser.
- Weave pour suivre notre flux de travail LLM et évaluer nos stratégies de prompting.
- datasets pour accéder au jeu de données Big-Bench Hard sur le Hub HuggingFace.
!pip install -qU dspy-ai weave datasets
import os
from getpass import getpass
api_key = getpass("Enter you OpenAI API key: ")
os.environ["OPENAI_API_KEY"] = api_key
Activer le suivi avec Weave
weave.init au début de votre code vous permet de tracer automatiquement vos fonctions DSPy et de les explorer dans la Weave UI. Consultez la documentation de l’intégration Weave pour DSPy pour en savoir plus.
import weave
weave.init(project_name="dspy-bigbench-hard")
weave.Object pour gérer nos métadonnées.
class Metadata(weave.Object):
dataset_address: str = "maveriq/bigbenchhard"
big_bench_hard_task: str = "causal_judgement"
num_train_examples: int = 50
openai_model: str = "gpt-3.5-turbo"
openai_max_tokens: int = 2048
max_bootstrapped_demos: int = 8
max_labeled_demos: int = 8
metadata = Metadata()
Gestion des versions des objets : les objets Metadata font automatiquement l’objet d’une gestion des versions et sont tracés lorsque les fonctions qui les utilisent sont elles-mêmes tracées
Charger le jeu de données BIG-Bench Hard
weave.Evaluation pour évaluer notre stratégie de prompting.
import dspy
from datasets import load_dataset
@weave.op()
def get_dataset(metadata: Metadata):
# charger le jeu de données BIG-Bench Hard correspondant à la tâche depuis Huggingface Hug
dataset = load_dataset(metadata.dataset_address, metadata.big_bench_hard_task)[
"train"
]
# créer les jeux de données d'entraînement et de validation
rows = [{"question": data["input"], "answer": data["target"]} for data in dataset]
train_rows = rows[0 : metadata.num_train_examples]
val_rows = rows[metadata.num_train_examples :]
# créer les exemples d'entraînement et de validation composés d'objets `dspy.Example`
dspy_train_examples = [
dspy.Example(row).with_inputs("question") for row in train_rows
]
dspy_val_examples = [dspy.Example(row).with_inputs("question") for row in val_rows]
# publier les jeux de données sur Weave, ce qui permet de versionner les données et de les utiliser pour l'évaluation
weave.publish(
weave.Dataset(
name=f"bigbenchhard_{metadata.big_bench_hard_task}_train", rows=train_rows
)
)
weave.publish(
weave.Dataset(
name=f"bigbenchhard_{metadata.big_bench_hard_task}_val", rows=val_rows
)
)
return dspy_train_examples, dspy_val_examples
dspy_train_examples, dspy_val_examples = get_dataset(metadata)
dspy.OpenAI pour effectuer des appels LLM vers GPT3.5 Turbo.
system_prompt = """
You are an expert in the field of causal reasoning. You are to analyze the a given question carefully and answer in `Yes` or `No`.
You should also provide a detailed explanation justifying your answer.
"""
llm = dspy.OpenAI(model="gpt-3.5-turbo", system_prompt=system_prompt)
dspy.settings.configure(lm=llm)
Écrire la signature du raisonnement causal
from pydantic import BaseModel, Field
class Input(BaseModel):
query: str = Field(description="The question to be answered")
class Output(BaseModel):
answer: str = Field(description="The answer for the question")
confidence: float = Field(
ge=0, le=1, description="The confidence score for the answer"
)
explanation: str = Field(description="The explanation for the answer")
class QuestionAnswerSignature(dspy.Signature):
input: Input = dspy.InputField()
output: Output = dspy.OutputField()
class CausalReasoningModule(dspy.Module):
def __init__(self):
self.prog = dspy.TypedPredictor(QuestionAnswerSignature)
@weave.op()
def forward(self, question) -> dict:
return self.prog(input=Input(query=question)).output.dict()
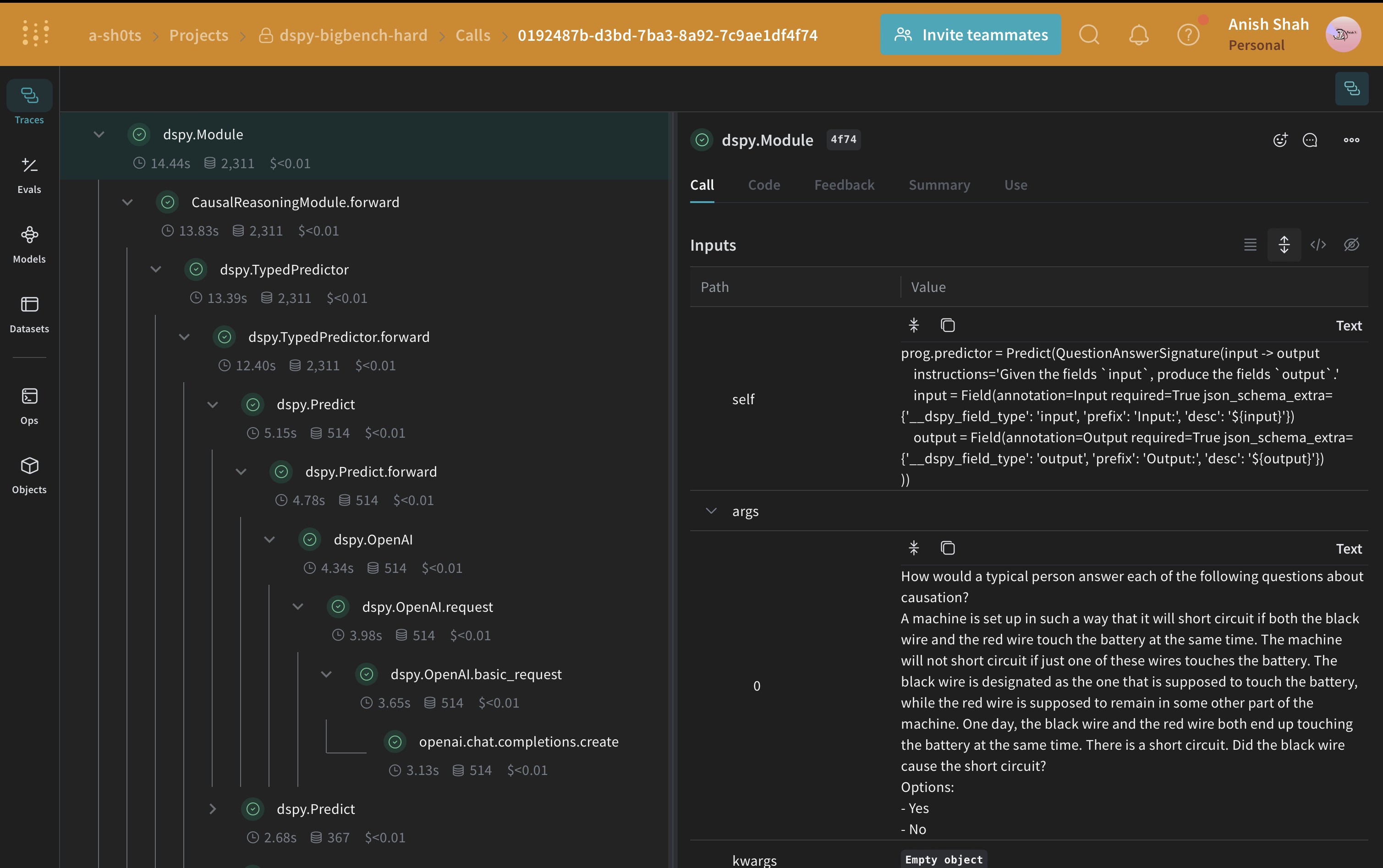
CausalReasoningModule, sur un exemple tiré du sous-ensemble de raisonnement causal de Big-Bench Hard.
import rich
baseline_module = CausalReasoningModule()
prediction = baseline_module(dspy_train_examples[0]["question"])
rich.print(prediction)
Évaluation de notre programme DSPy
weave.Evaluation, avec une métrique simple qui compare la réponse prédite à la réponse de référence. Weave prendra chaque exemple, le fera passer dans votre application et attribuera un score à la sortie à l’aide de plusieurs fonctions de scoring personnalisées. Vous obtiendrez ainsi une vue des performances de votre application, ainsi qu’une UI riche pour examiner en détail chaque sortie et son score.
Nous devons d’abord créer une fonction simple de scoring pour l’évaluation Weave, qui indique si la réponse produite par le module de référence correspond ou non à la réponse de référence. Les fonctions de scoring doivent avoir un argument nommé model_output, mais les autres arguments sont définis par l’utilisateur et proviennent des exemples du jeu de données. La fonction ne récupérera que les clés nécessaires à partir du nom des arguments dans le dictionnaire.
@weave.op()
def weave_evaluation_scorer(answer: str, output: Output) -> dict:
return {"match": int(answer.lower() == output["answer"].lower())}
validation_dataset = weave.ref(
f"bigbenchhard_{metadata.big_bench_hard_task}_val:v0"
).get()
evaluation = weave.Evaluation(
name="baseline_causal_reasoning_module",
dataset=validation_dataset,
scorers=[weave_evaluation_scorer],
)
await evaluation.evaluate(baseline_module.forward)
Si vous exécutez ce code depuis un script Python, vous pouvez utiliser le code suivant pour lancer l’évaluation :import asyncio
asyncio.run(evaluation.evaluate(baseline_module.forward))
Exécuter l’évaluation sur le jeu de données de raisonnement causal coûtera environ 0,24 $ en crédits OpenAI.
Optimisation de notre programme DSPy
from dspy.teleprompt import BootstrapFewShot
@weave.op()
def get_optimized_program(model: dspy.Module, metadata: Metadata) -> dspy.Module:
@weave.op()
def dspy_evaluation_metric(true, prediction, trace=None):
return prediction["answer"].lower() == true.answer.lower()
teleprompter = BootstrapFewShot(
metric=dspy_evaluation_metric,
max_bootstrapped_demos=metadata.max_bootstrapped_demos,
max_labeled_demos=metadata.max_labeled_demos,
)
return teleprompter.compile(model, trainset=dspy_train_examples)
optimized_module = get_optimized_program(baseline_module, metadata)
L’exécution de l’évaluation sur le jeu de données de raisonnement causal coûtera environ 0,04 $ en crédits OpenAI.
evaluation = weave.Evaluation(
name="optimized_causal_reasoning_module",
dataset=validation_dataset,
scorers=[weave_evaluation_scorer],
)
await evaluation.evaluate(optimized_module.forward)



