Il s’agit d’un notebook interactif. Vous pouvez l’exécuter localement ou utiliser les liens ci-dessous :
Routage personnalisé des prompts LLM avec Not Diamond
Routage des prompts
Routage personnalisé
- Un ensemble de prompts LLM : les prompts doivent être des chaînes de caractères et être représentatifs de ceux utilisés dans notre application.
- Des réponses de LLM : les réponses des LLM candidats pour chaque entrée. Les LLM candidats peuvent inclure à la fois nos LLM pris en charge et vos propres modèles personnalisés.
- Des scores d’évaluation pour les réponses aux entrées des LLM candidats : les scores sont des nombres et peuvent correspondre à n’importe quelle métrique adaptée à vos besoins.
Préparation des données d’entraînement
EvaluationResults pour chaque modèle.
Entraîner un routeur personnalisé
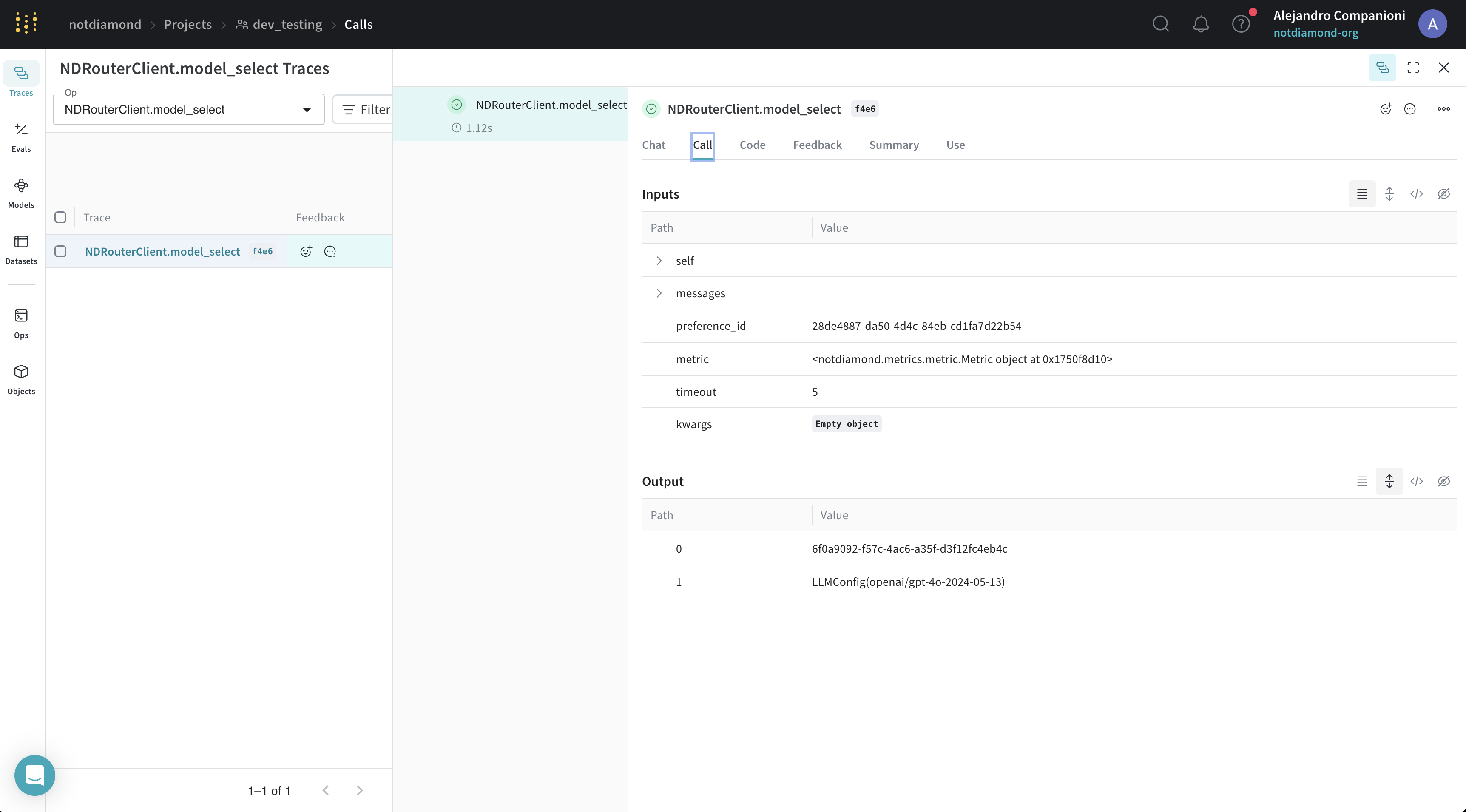
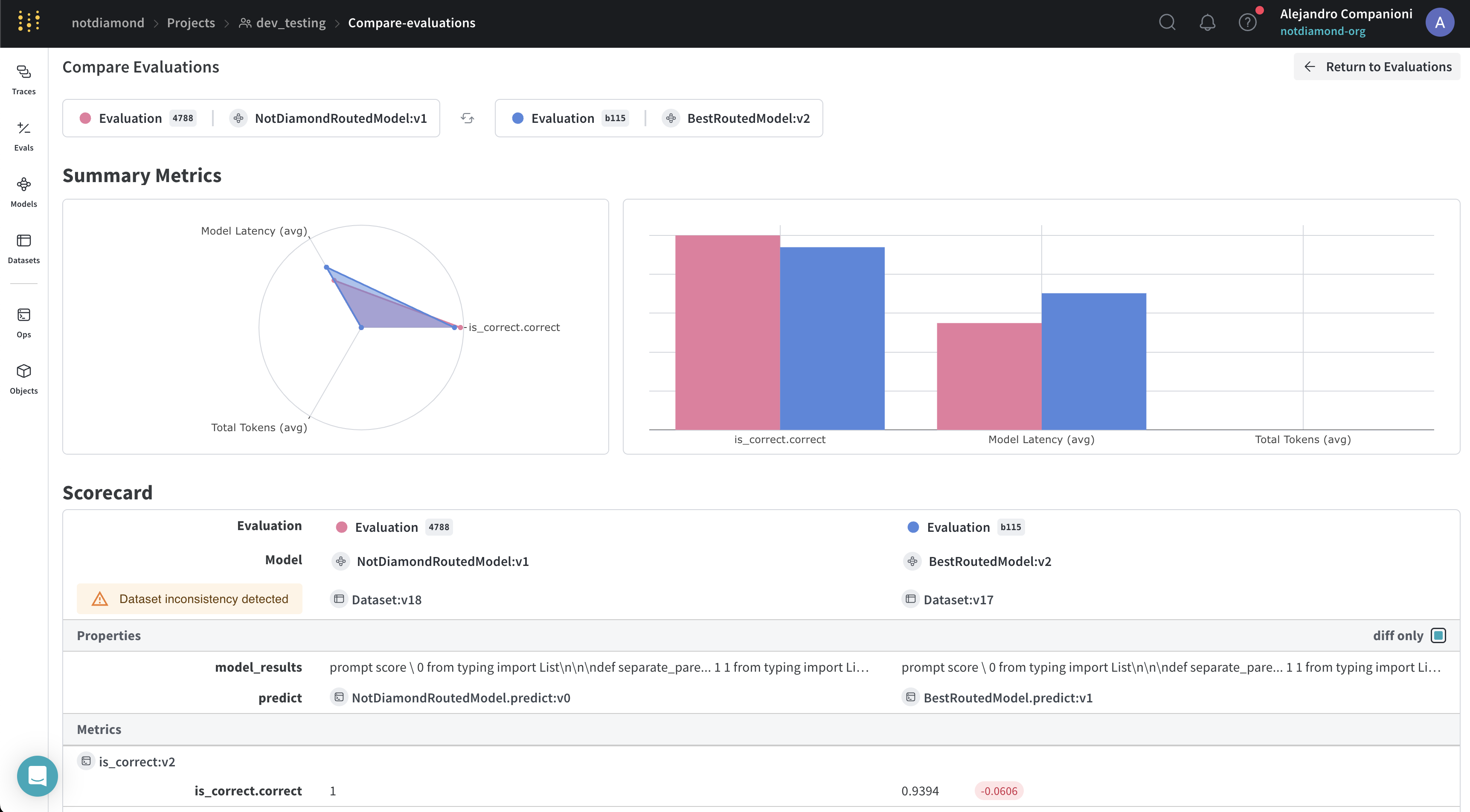
Évaluer votre routeur personnalisé
- performances sur les données d’entraînement, en soumettant les prompts d’entraînement, soit
- performances hors échantillon, en soumettant de nouveaux prompts ou des prompts de validation