LLM Evaluation Jobs는 W&B Multi-tenant Cloud에서 프리뷰 단계로 제공됩니다. 프리뷰 기간 동안 컴퓨팅 리소스는 무료로 제공됩니다. 자세히 알아보기
작동 방식
- W&B Models에서 평가 작업을 설정합니다. 리더보드를 생성할지 여부와 같은 벤치마크와 설정을 정의합니다.
- 평가 작업을 Launch에서 실행합니다.
- 결과와 리더보드를 확인하고 분석합니다.
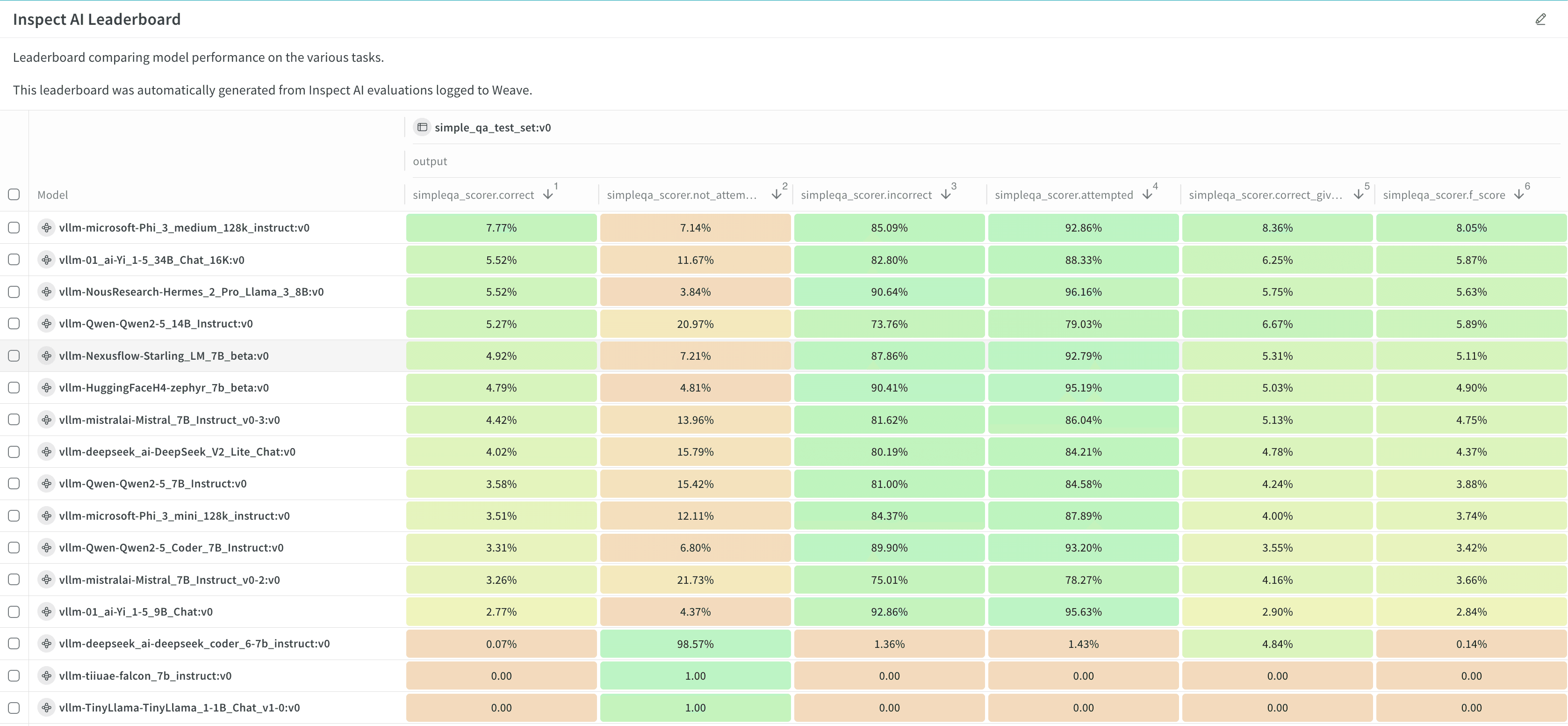
다음 단계
- Evaluation benchmark 카탈로그를 둘러보세요
- 모델 체크포인트를 평가하세요
- API로 호스팅된 모델을 평가하세요
자세한 정보
가격
작업 제한
- 평가에 사용할 수 있는 모델의 최대 크기는 컨텍스트를 포함해 86 GB입니다.
- 각 작업은 GPU를 최대 2개까지 사용할 수 있습니다.
요구 사항
- 모델 체크포인트를 평가하려면 모델 가중치가 VLLM과 호환되는 아티팩트로 패키징되어 있어야 합니다. 자세한 내용과 예제 코드는 예시: 모델 준비하기를 참조하세요.
- OpenAI와 호환되는 모델을 평가하려면 해당 모델이 공개 URL에서 접근 가능해야 하며, 조직 또는 팀 관리자가 인증을 위한 API 키가 포함된 team secret을 설정해야 합니다.
- 일부 벤치마크는 점수 산정을 위해 OpenAI 모델을 사용합니다. 이러한 벤치마크를 실행하려면 조직 또는 팀 관리자가 필요한 API 키가 포함된 team secrets를 설정해야 합니다. 특정 벤치마크에 이 요구 사항이 있는지 확인하려면 Evaluation benchmark catalog를 참조하세요.
- 일부 벤치마크는 Hugging Face의 게이트된(gated) 데이터셋에 대한 접근을 필요로 합니다. 이러한 벤치마크를 실행하려면 조직 또는 팀 관리자가 Hugging Face에서 해당 게이트된 데이터셋에 대한 접근을 요청하고, Hugging Face 사용자 액세스 토큰을 생성한 뒤 이를 team secret으로 설정해야 합니다. 특정 벤치마크에 이 요구 사항이 있는지 확인하려면 Evaluation benchmark catalog를 참조하세요.