코드 두 줄로 한 단계 더 진화한 로깅
시작하기
-
diffusers,transformers,accelerate, 그리고wandb를 설치합니다.-
명령줄:
-
노트북:
-
명령줄:
-
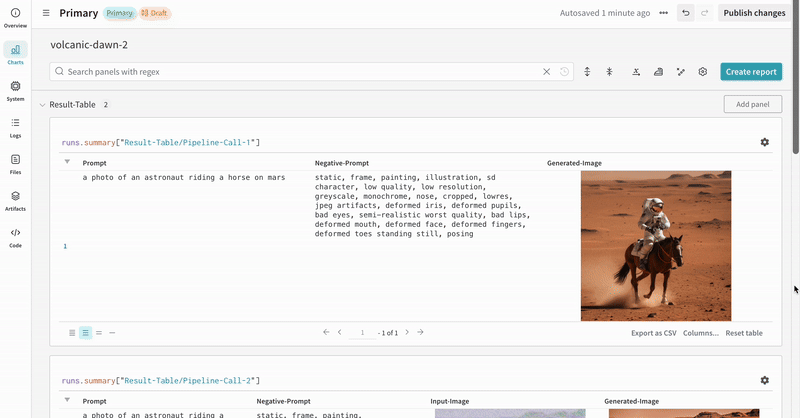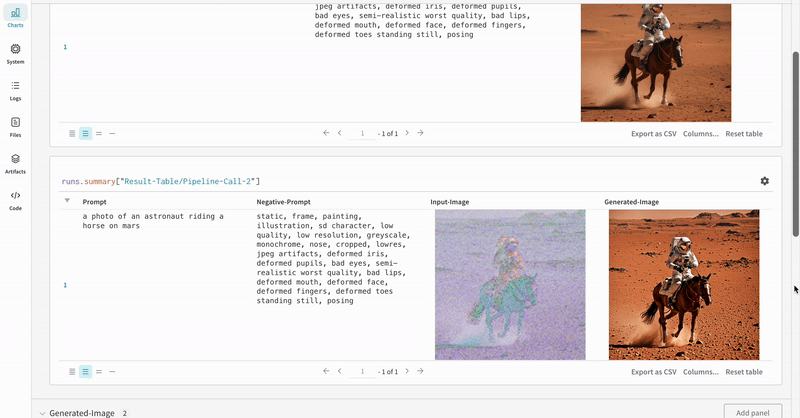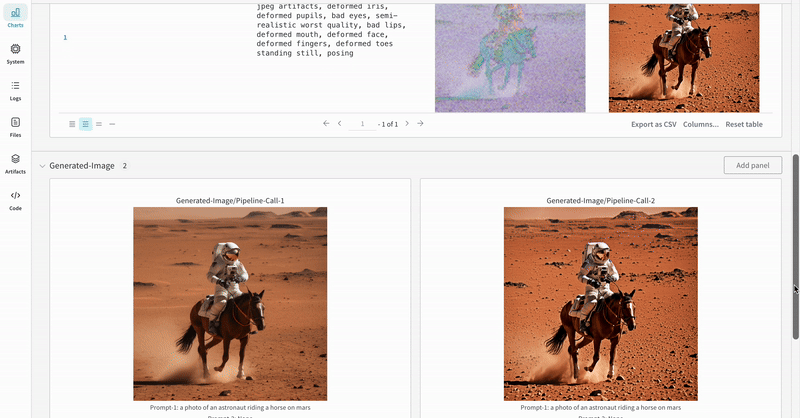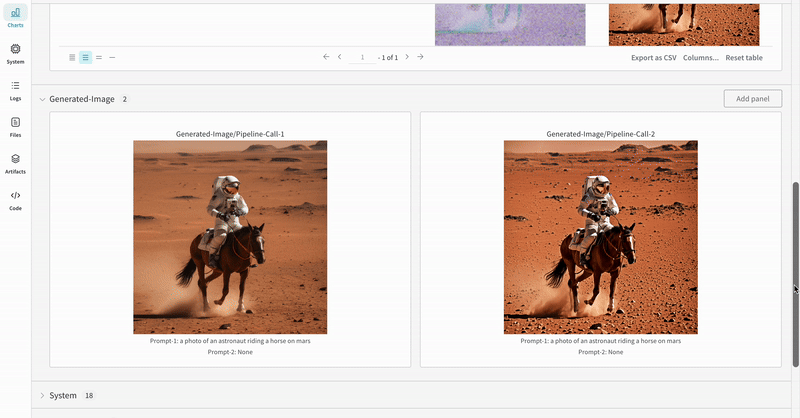
autolog를 사용하여 W&B run을 초기화하고, 지원되는 모든 파이프라인 호출의 입력과 출력을 자동으로 추적합니다.autolog()함수를 호출할 때init매개변수를 함께 사용할 수 있으며, 이 매개변수에는wandb.init()에 필요한 파라미터 사전을 전달할 수 있습니다.autolog()를 호출하면 W&B run이 초기화되고, 지원되는 모든 파이프라인 호출의 입력과 출력이 자동으로 추적됩니다.- 각 파이프라인 호출은 워크스페이스 내의 개별 테이블에 추적되며, 해당 파이프라인 호출과 관련된 config는 해당 run의 config에 있는 워크플로 목록에 추가됩니다.
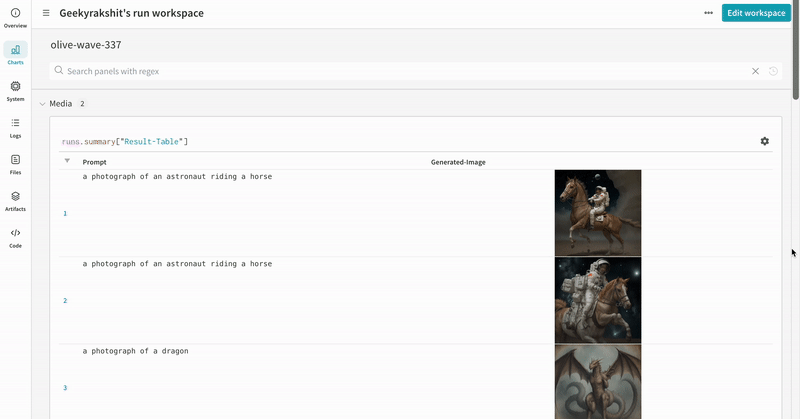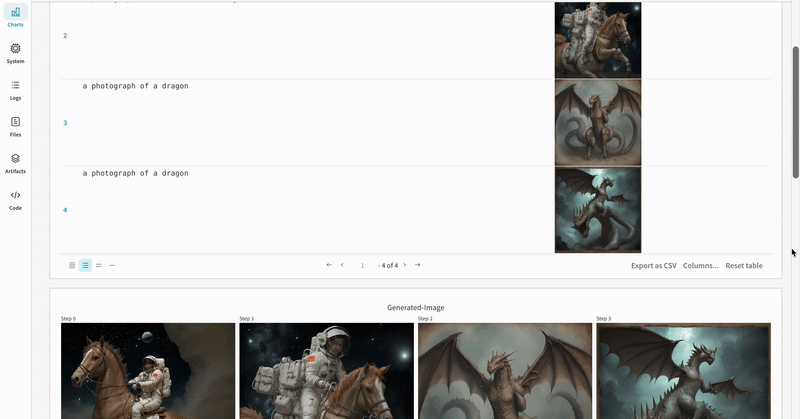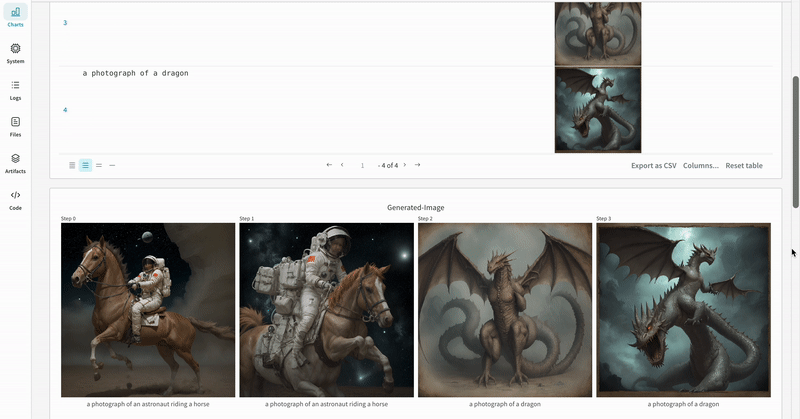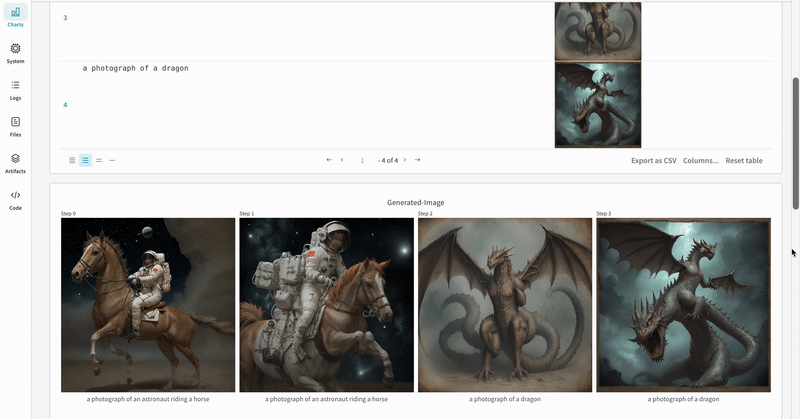
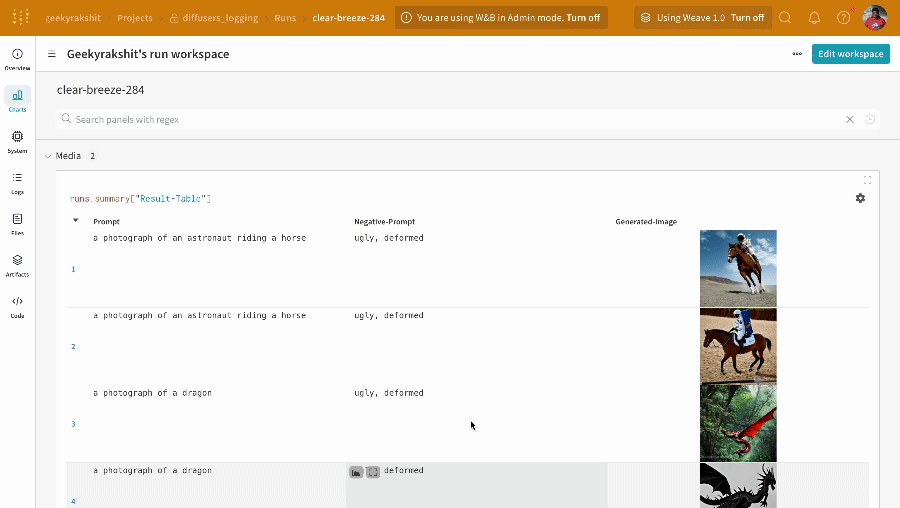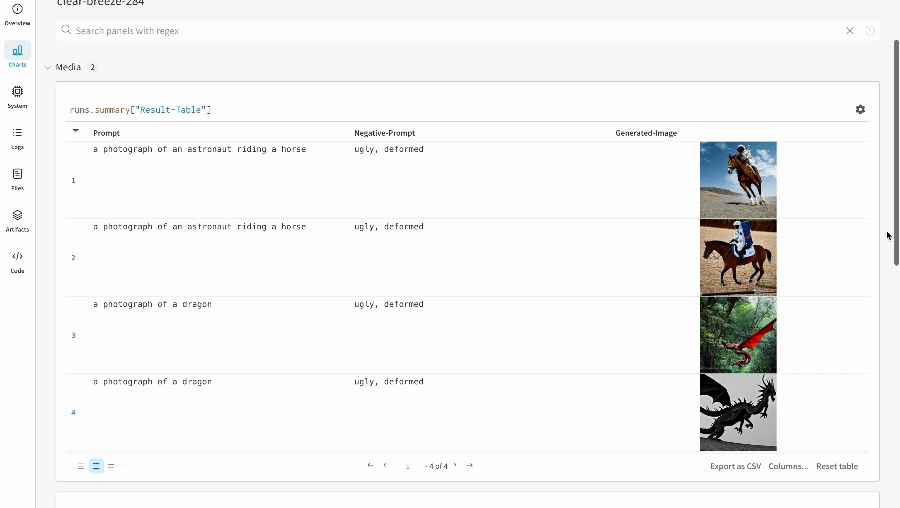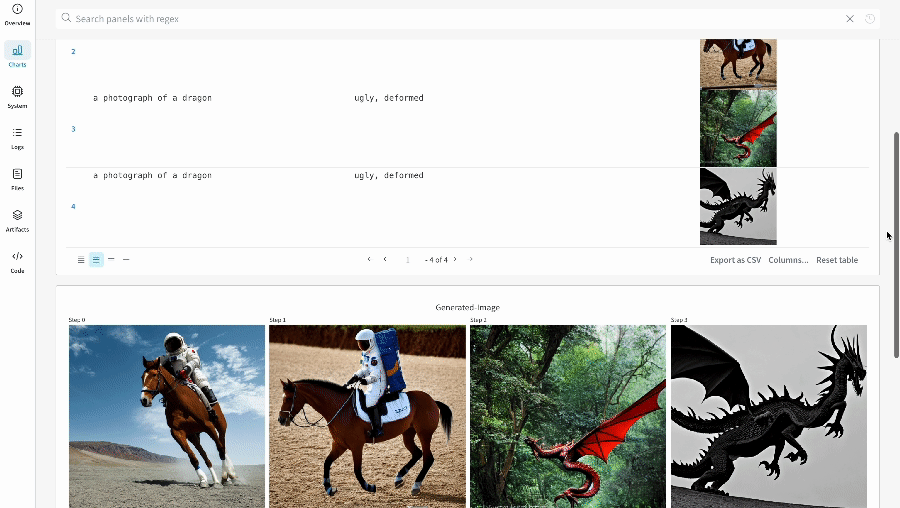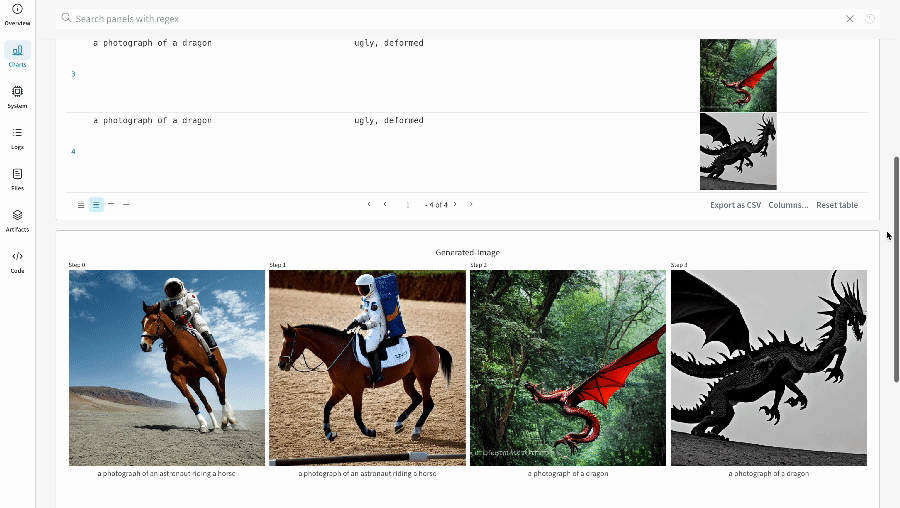
- 프롬프트, 네거티브 프롬프트, 생성된 미디어는
wandb.Table에 로깅됩니다. - 시드와 파이프라인 아키텍처를 포함해 실험과 관련된 나머지 모든 config는 해당 run의 config 섹션에 저장됩니다.
- 각 파이프라인 호출로 생성된 미디어는 해당 run의 media panels에도 로깅됩니다.
지원되는 파이프라인 호출 목록을 확인할 수 있습니다. 이 인테그레이션에 대한 새로운 기능을 요청하거나 관련 버그를 신고하려면, W&B GitHub Issues 페이지에 이슈를 생성하세요.
예제
자동 로깅(Autologging)
- 스크립트
- 노트북
-
단일 실험 결과:
-
여러 실험 결과:
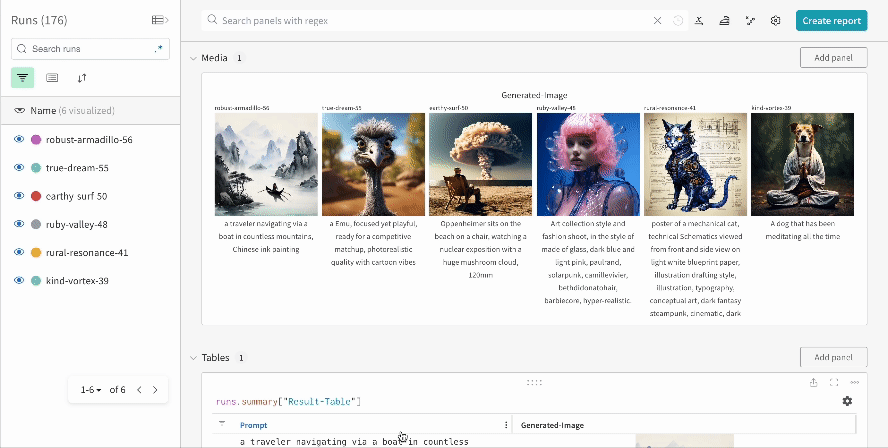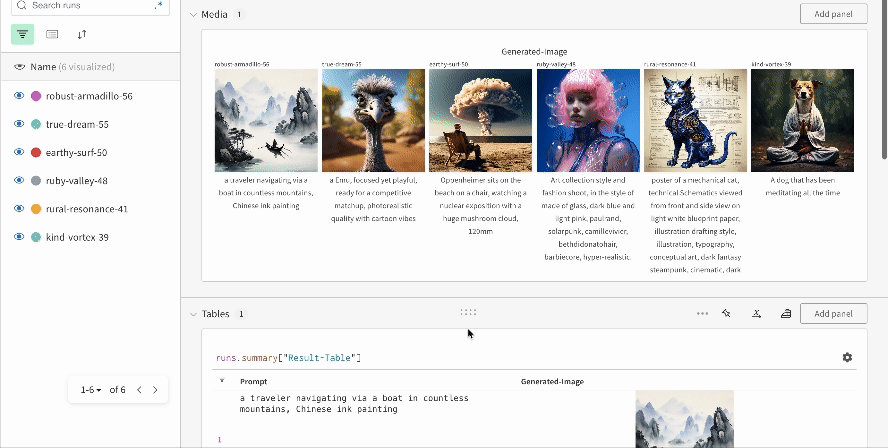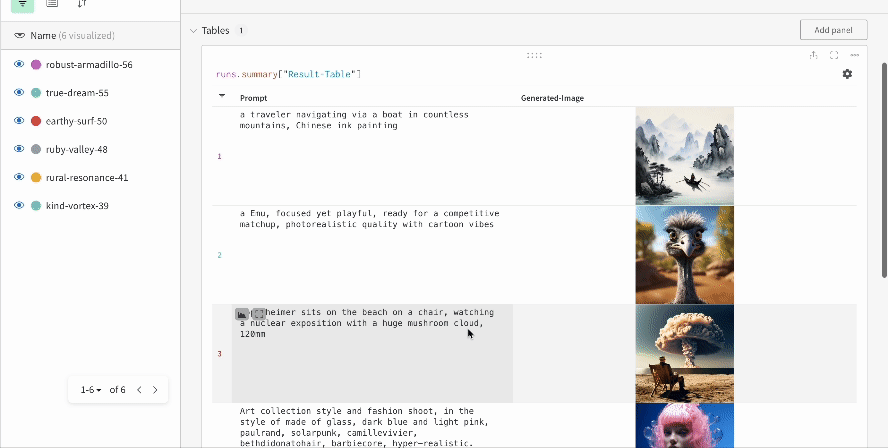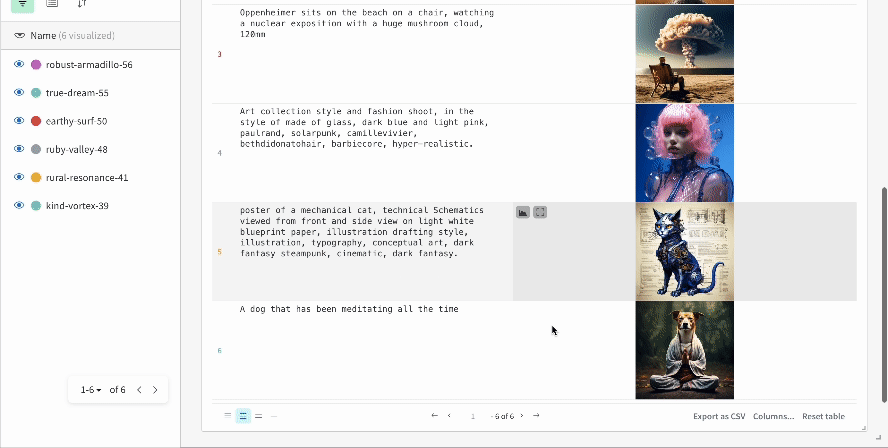
-
실험 설정(config):
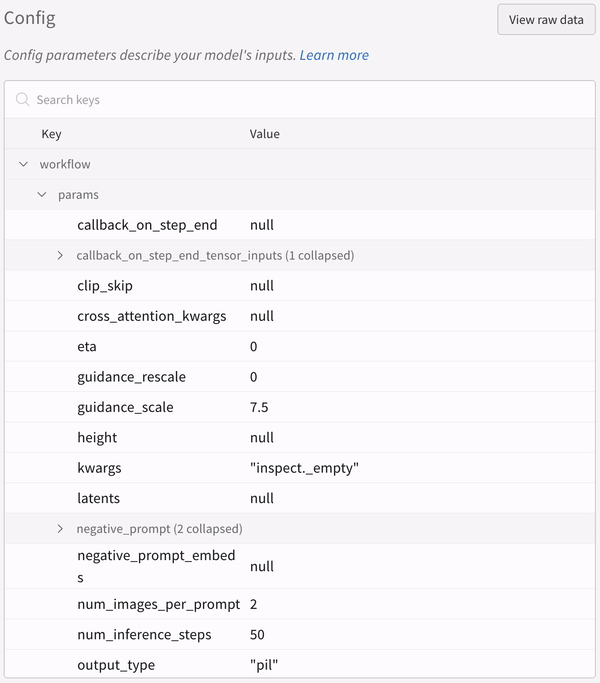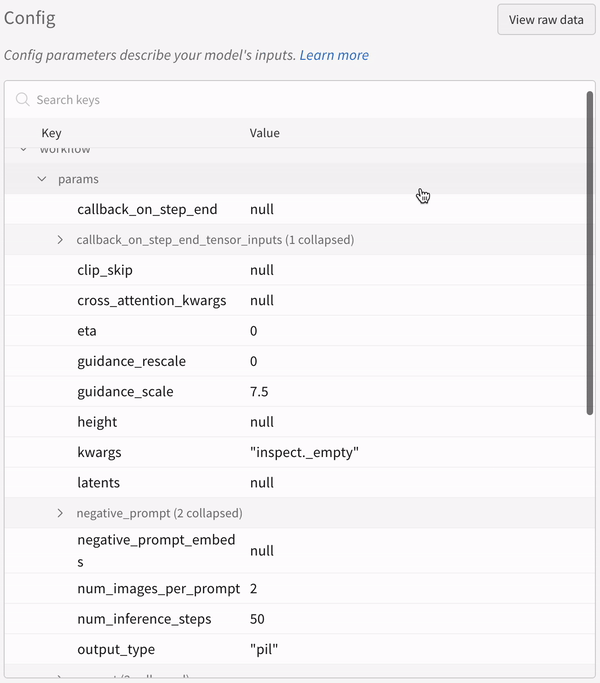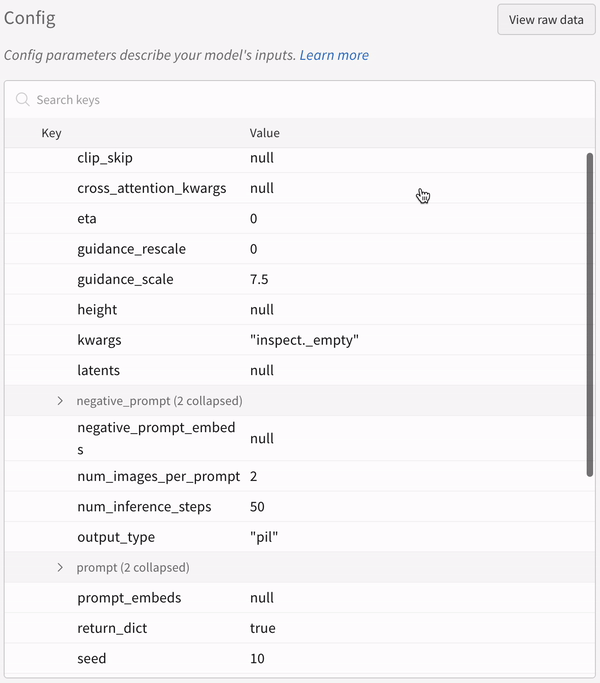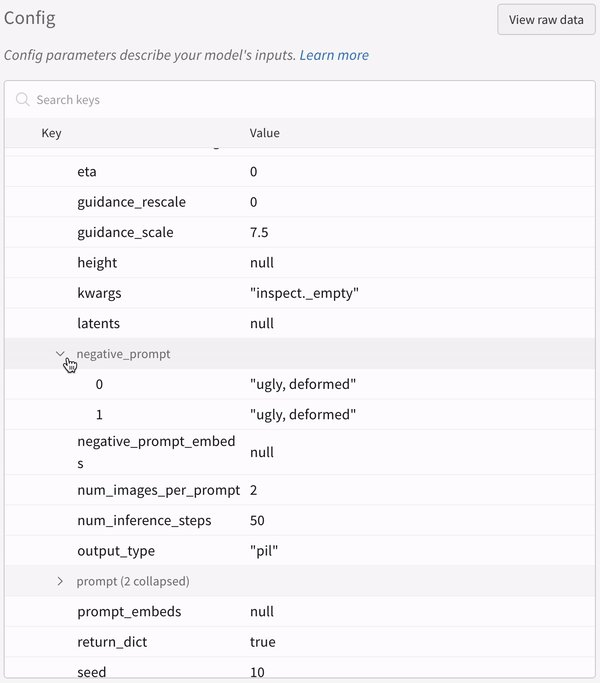
파이프라인을 호출한 뒤 IPython 노트북 환경에서 코드를 실행할 때는
wandb.Run.finish()를 명시적으로 호출해야 합니다. 파이썬 스크립트를 실행할 때는 이 호출이 필요하지 않습니다.다중 파이프라인 워크플로 추적
StableDiffusionXLPipeline이 생성한 latent 벡터가 해당 Refiner에 의해 정제됩니다.
- Python 스크립트
- 노트북
- Stable Diffusion XL + Refiner 실험 예시: