기본 예시: Weave로 Llama 3.1 8B 트레이싱하기
- 채팅 컴플리션 요청을 수행하는
@weave.op()데코레이터가 적용된 함수를 정의합니다. - 트레이스는 기록되어 W&B entity와 프로젝트에 연결됩니다.
- 함수는 자동으로 트레이싱되며, 입력, 출력, 레이턴시, 메타데이터를 로깅합니다.
- 결과는 터미널에 출력되고, 트레이스는 https://wandb.ai의 Traces 탭에 나타납니다.
- 터미널에 출력된 링크를 클릭합니다. (예:
https://wandb.ai/<your-team>/<your-project>/r/call/01977f8f-839d-7dda-b0c2-27292ef0e04g) - 또는 https://wandb.ai로 이동한 다음 Traces 탭을 선택합니다.
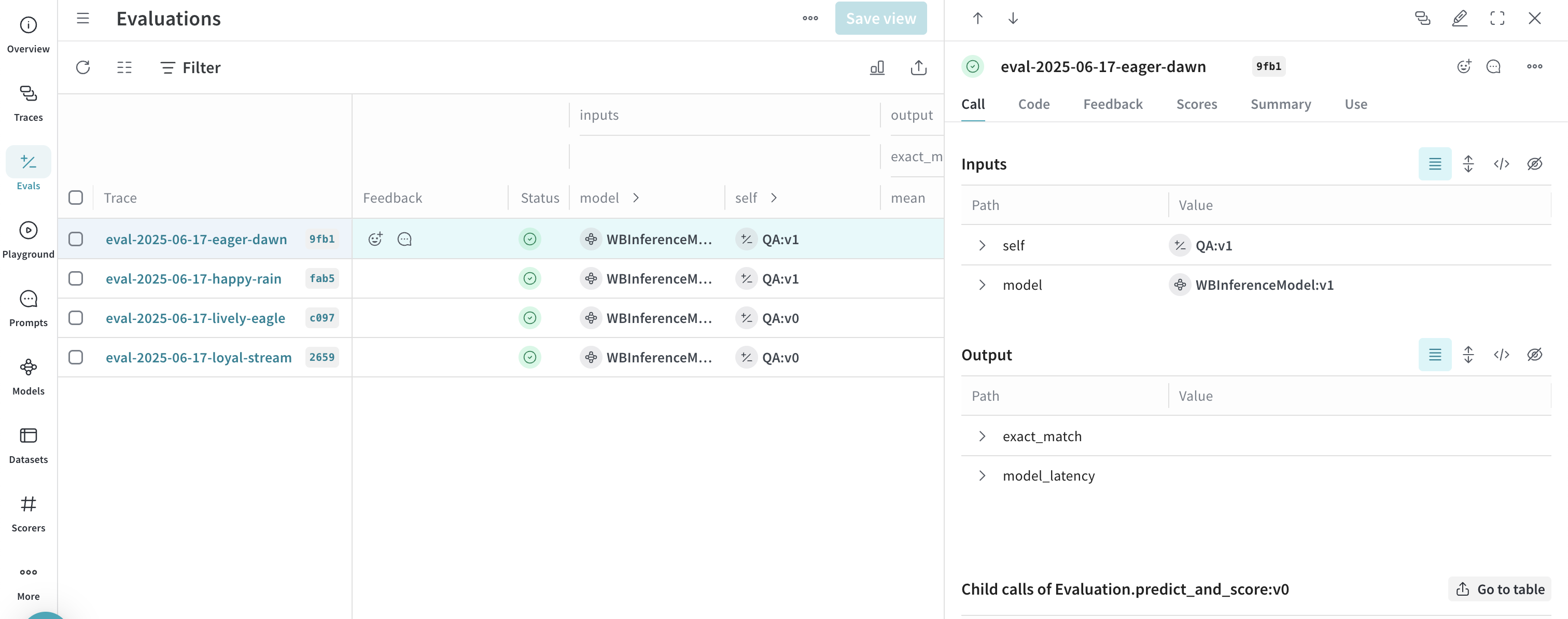
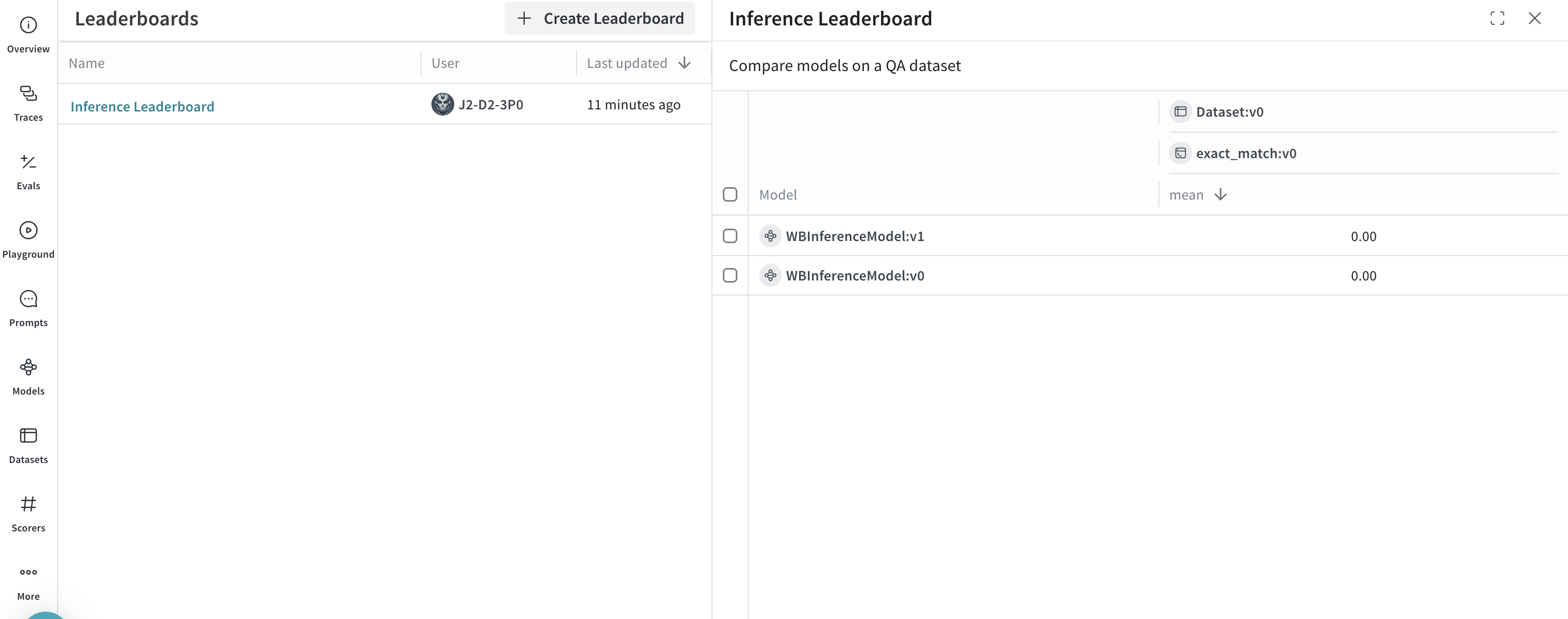
고급 예제: Weave Evaluations 및 Leaderboards 사용하기
- Traces 탭을 선택하여 트레이스를 확인합니다
- Evals 탭을 선택하여 모델 평가 결과를 확인합니다
- Leaders 탭을 선택하여 생성된 리더보드를 확인합니다