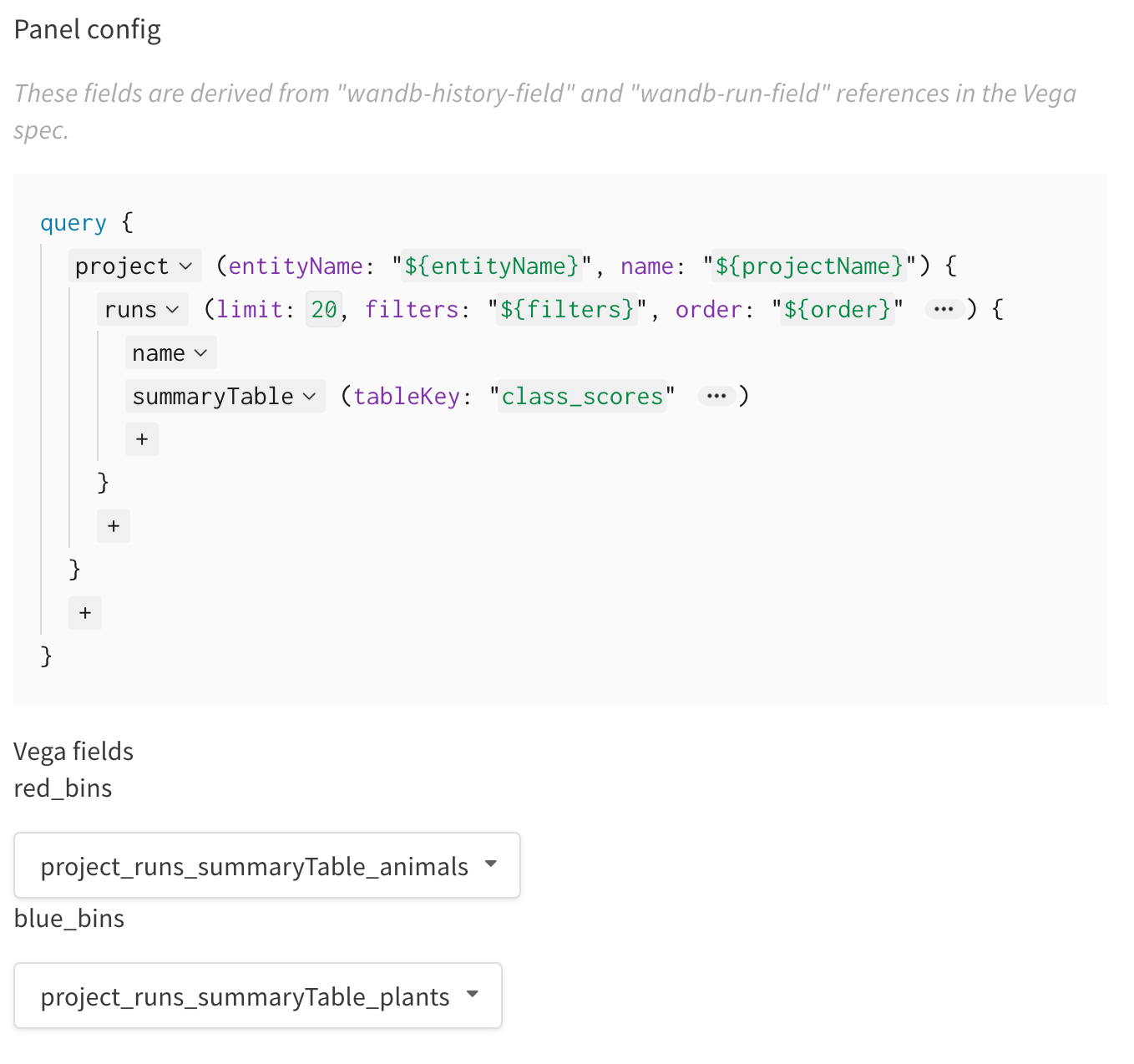
1. Enregistrez des données dans W&B
wandb.Table(). Nous vous recommandons d’enregistrer jusqu’à 10 000 points de données par clé enregistrée.
2. Créer une requête
+ pour ajouter un nouveau panneau, puis sélectionnez Graphique personnalisé. Vous pouvez suivre les étapes dans l’espace de travail de démonstration des graphiques personnalisés.

Ajouter une requête
- Cliquez sur
summaryet sélectionnezhistoryTablepour configurer une nouvelle requête qui extrait des données de l’historique du run. - Saisissez la clé sous laquelle vous avez enregistré le
wandb.Table(). Dans le code snippet ci-dessus, c’étaitmy_custom_table. Dans le notebook d’exemple, les clés sontpr_curveetroc_curve.
Définir les champs Vega
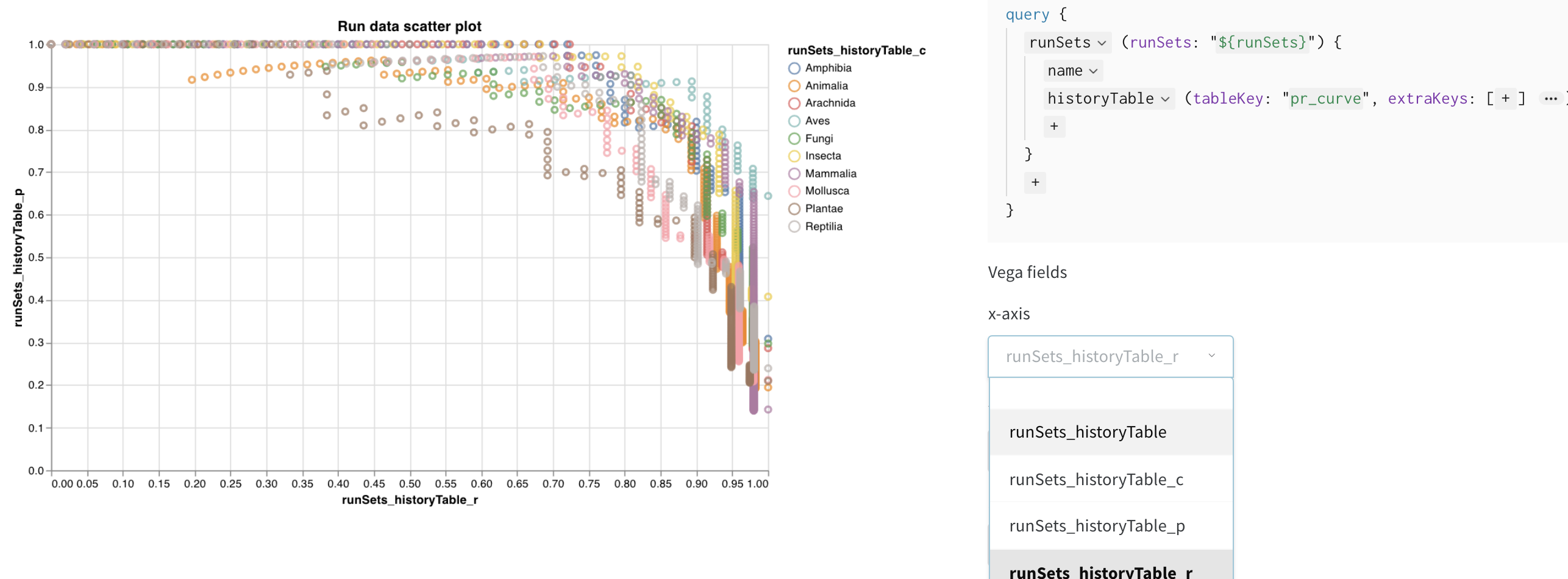
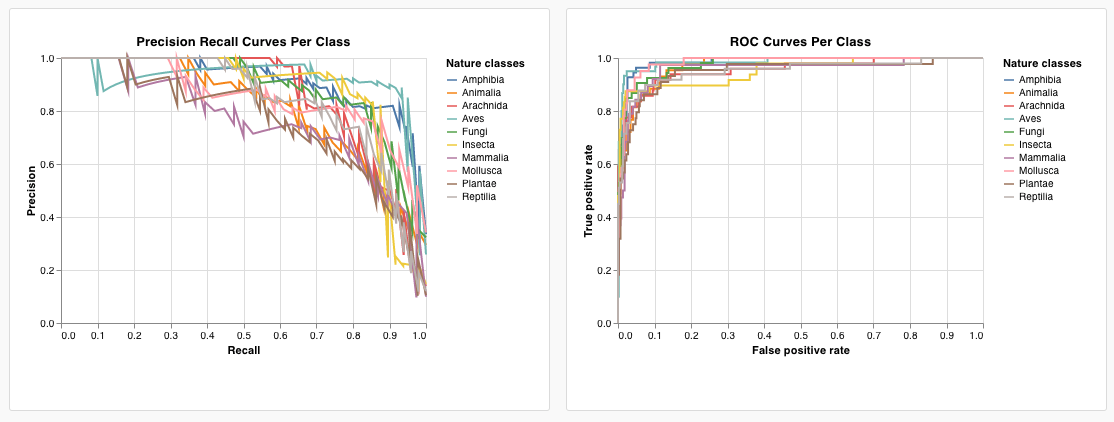
- axe x : runSets_historyTable_r (rappel)
- axe y : runSets_historyTable_p (précision)
- couleur : runSets_historyTable_c (étiquette de classe)
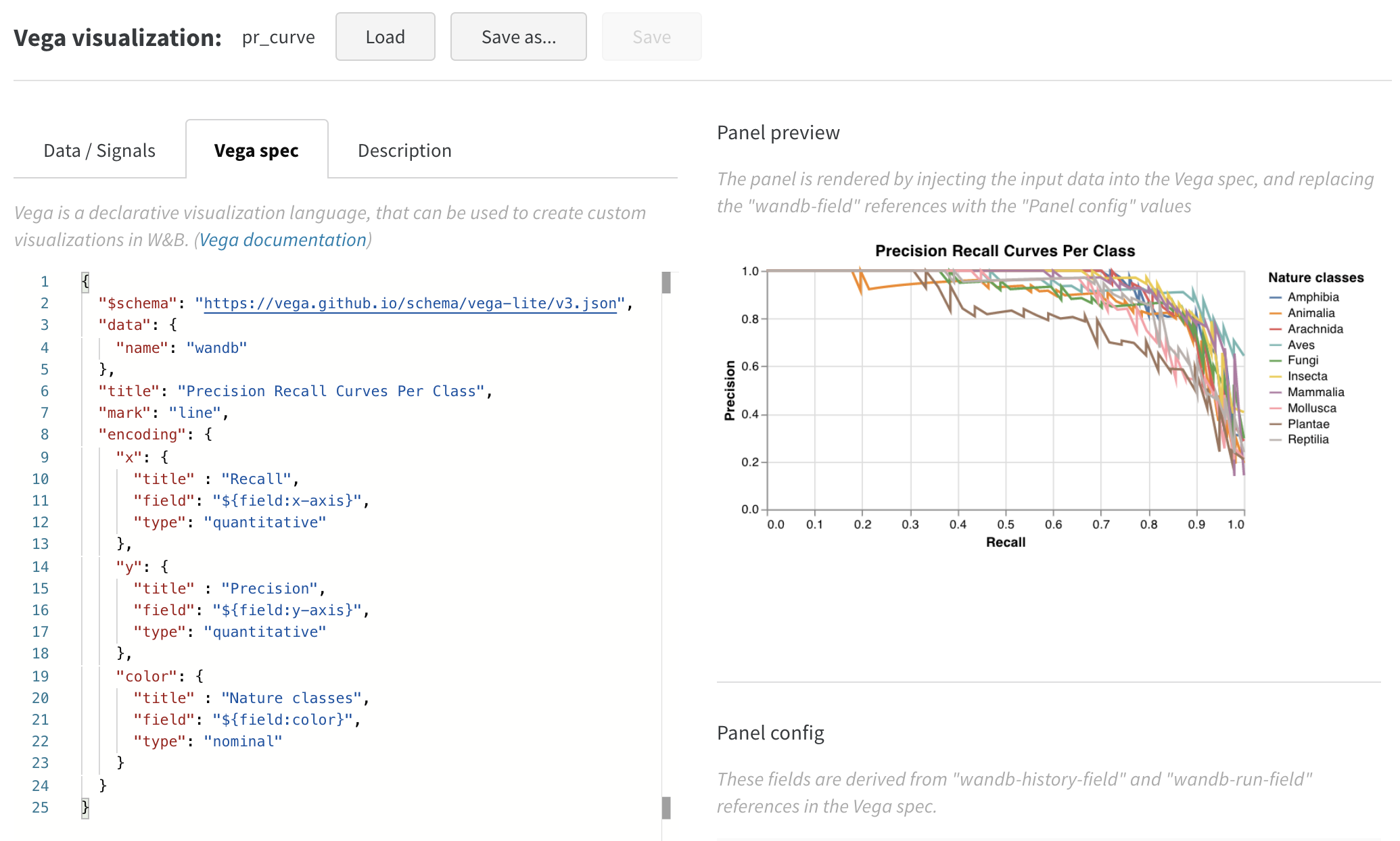
3. Personnaliser le graphique

- ajouter des titres pour le graphique, la légende, l’axe des x et l’axe des y (définissez « title » pour chaque champ)
- remplacer la valeur de « mark » de « point » par « line »
- supprimer le champ « size » inutilisé
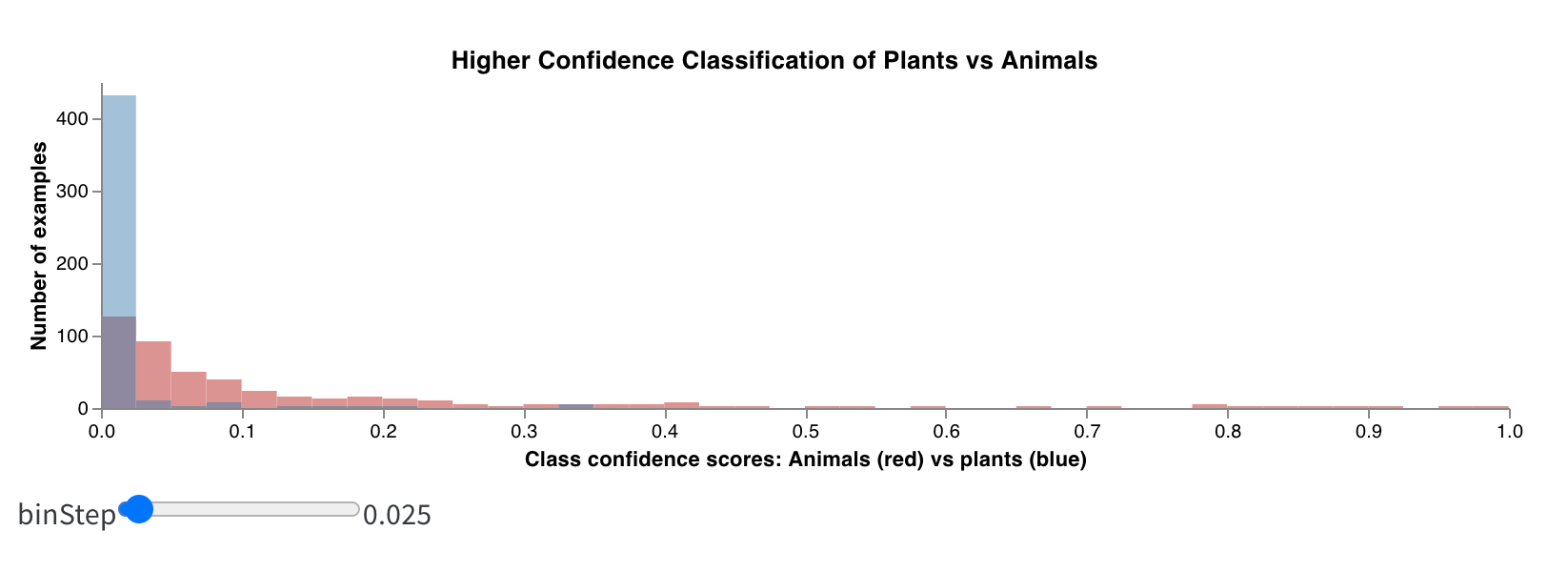
Bonus : histogrammes composites
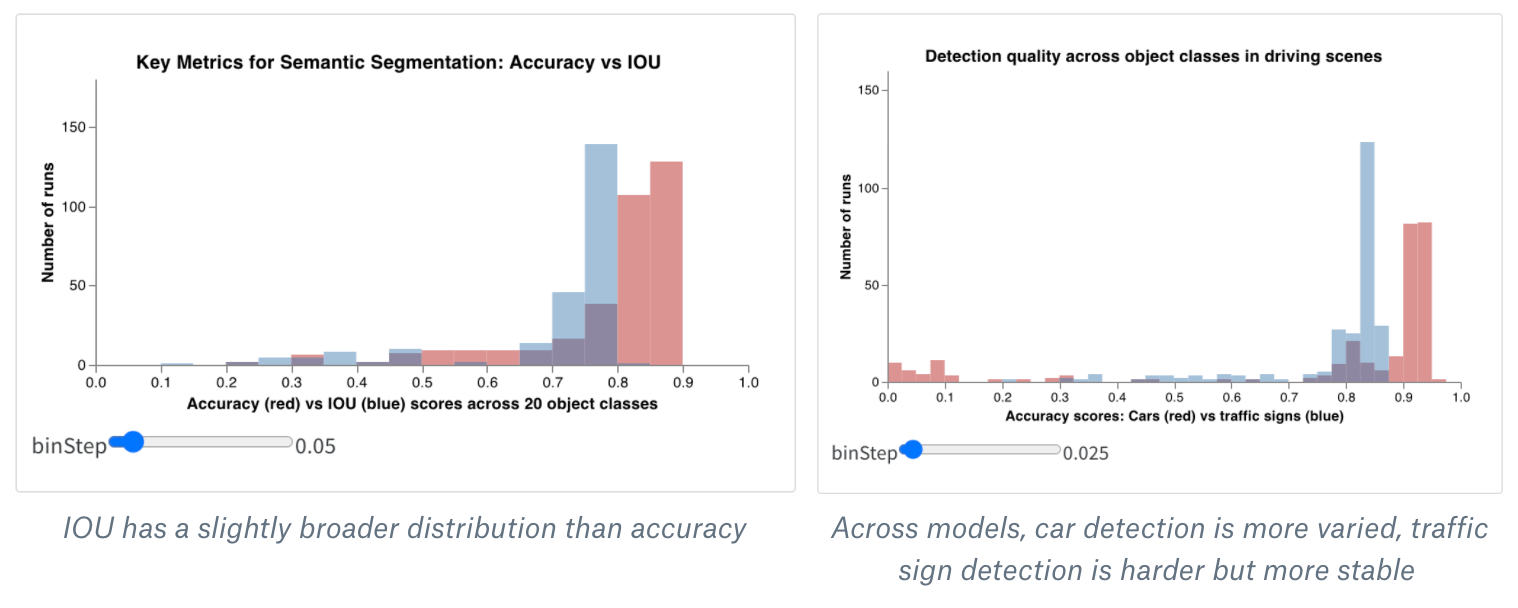
- Créez un nouveau panneau Graphique personnalisé dans votre Workspace ou rapport (en ajoutant une visualisation « Graphique personnalisé »). Cliquez sur le bouton « Edit » en haut à droite pour modifier la spécification Vega à partir de n’importe quel type de panneau intégré.
- Remplacez cette spécification Vega intégrée par mon code MVP pour un histogramme composite en Vega. Vous pouvez modifier directement dans cette spécification Vega, avec la syntaxe Vega, le titre principal, les titres des axes, le domaine d’entrée et tout autre détail (vous pouvez changer les couleurs ou même ajouter un troisième histogramme :)).
- Modifiez la requête à droite pour charger les bonnes données depuis vos logs wandb. Ajoutez le champ
summaryTableet définissez letableKeycorrespondant surclass_scorespour récupérer lewandb.Tableenregistré par votre run. Cela vous permettra d’alimenter les deux ensembles de bins de l’histogramme (red_binsetblue_bins) via les menus déroulants avec les colonnes duwandb.Tableenregistré sousclass_scores. Dans mon exemple, j’ai choisi les scores de prédiction de la classeanimalpour les bins rouges etplantpour les bins bleus. - Vous pouvez continuer à modifier la spécification Vega et la requête jusqu’à ce que le graphique affiché dans l’aperçu vous convienne. Une fois terminé, cliquez sur Save as en haut et donnez un nom à votre graphique personnalisé pour pouvoir le réutiliser. Cliquez ensuite sur Apply from panel library pour finaliser votre graphique.