이 노트북은 대화형 노트북입니다. 로컬에서 실행하거나 아래 링크로 열 수 있습니다:
3rd Party 시스템에서 Traces 가져오기
csv 또는 json 형식으로 제공되는 경우가 많습니다.
이 쿡북에서는 저수준 Weave Python API를 활용하여 CSV 파일에서 데이터를 추출하고, 이를 Weave로 가져와 인사이트를 얻고 엄격한 평가를 수행하는 방법을 살펴봅니다.
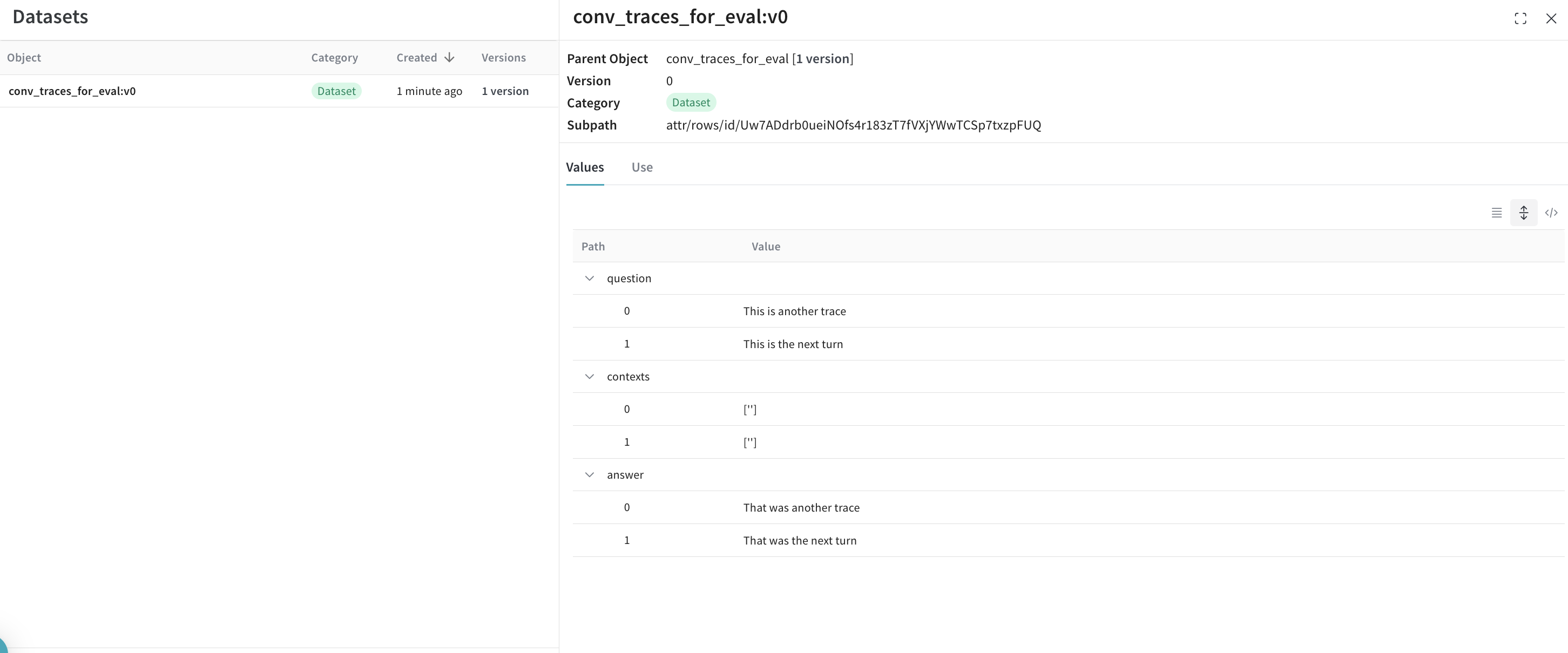
이 쿡북에서 가정하는 샘플 데이터셋은 다음과 같은 구조를 가지고 있습니다:
conversation_id를, 자식 식별자로는 turn_index를 사용합니다.
필요에 따라 변수 값을 수정하십시오.
환경 설정하기
WANDB_API_KEY를 환경 변수에 설정해서 wandb.login()으로 쉽게 로그인할 수 있도록 합니다(이 키는 Colab에 secret으로 제공되어야 합니다).
Colab에 업로드할 파일 이름을 name_of_file에 설정하고, 로그를 남길 W&B 프로젝트를 name_of_wandb_project에 설정합니다.
NOTE: name_of_wandb_project는 트레이스를 기록할 팀을 지정하기 위해 {team_name}/{project_name} 형식으로도 사용할 수 있습니다.
그다음 weave.init()을 호출해서 Weave 클라이언트를 가져옵니다.
데이터 로딩
conversation_id와 turn_index로 정렬합니다.
이렇게 하면 conversation_data 열에 배열 형태로 대화 턴이 포함된 두 개의 열을 가진 pandas 데이터프레임이 생성됩니다.
트레이스를 Weave에 로깅하기
- 각
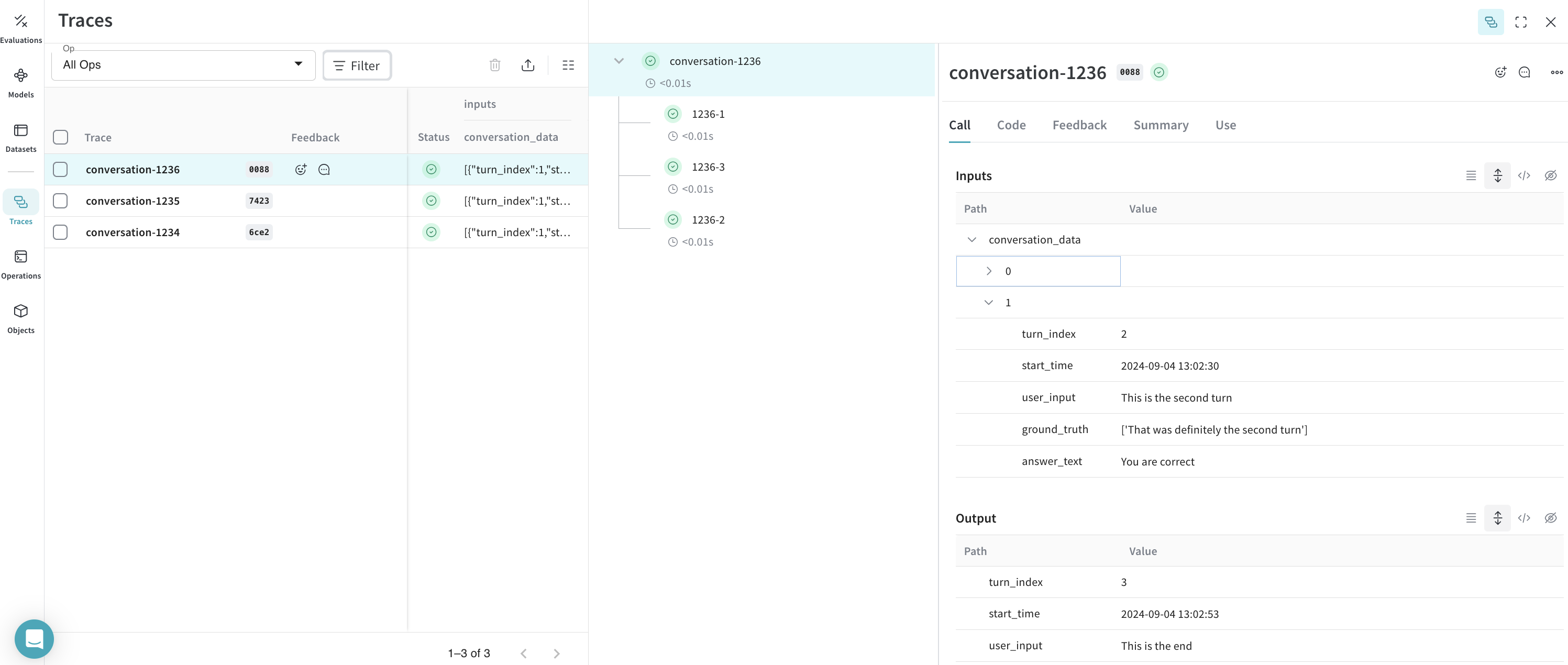
conversation_id마다 부모 call을 생성합니다. turn_index로 정렬된 턴 배열을 순회하며 자식 call을 생성합니다.
- Weave call은 Weave trace와 동일하며, 이 call에는 부모나 자식이 연결될 수 있습니다.
- Weave call에는 Feedback, Metadata 등 다른 것들이 연결될 수 있습니다. 여기서는 입력과 출력만 연결하지만, 데이터가 제공된다면 import 시 이러한 것들도 추가로 연결할 수 있습니다.
- Weave call은 실시간으로 추적되도록
created및finished상태를 가집니다. 이번 경우처럼 사후(import 이후) 처리에서는, 객체들을 정의하고 서로 연결한 뒤 한 번에 생성과 완료를 처리합니다. - call의
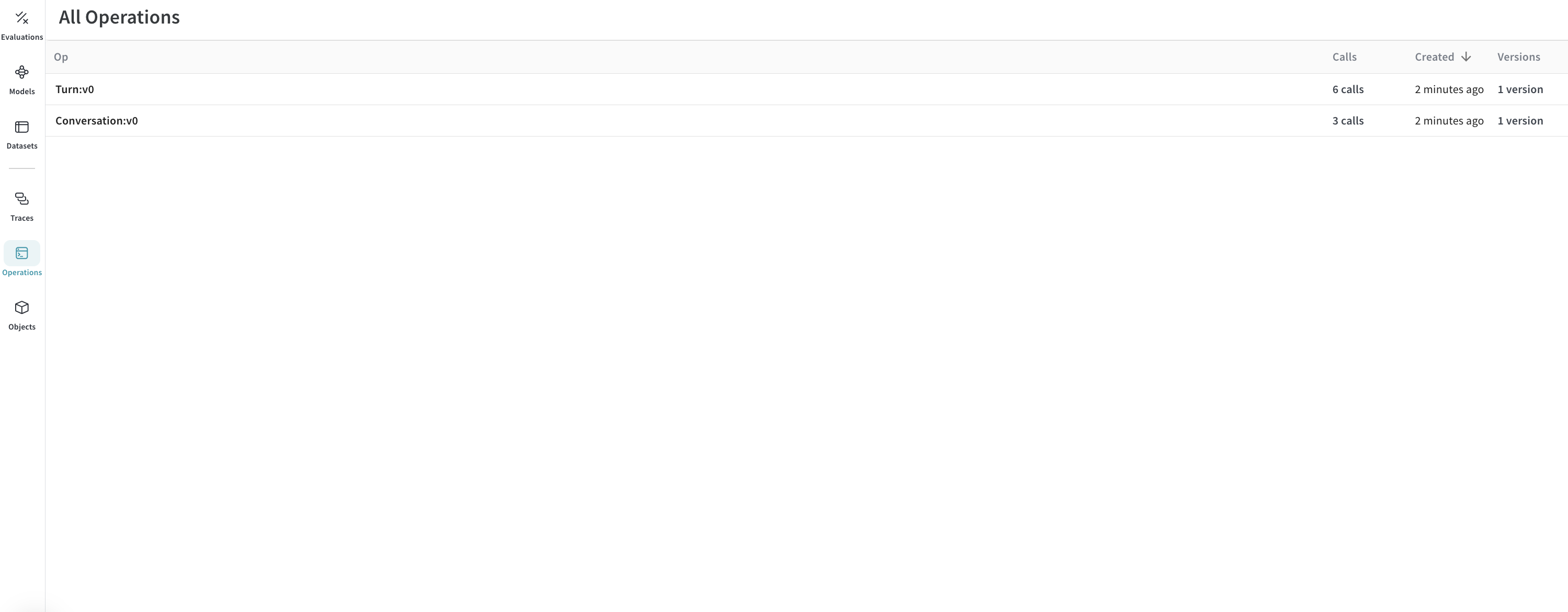
op값은 Weave가 동일한 구조의 call을 분류하는 방식입니다. 이 예시에서는 모든 부모 call은Conversation타입이고, 모든 자식 call은Turn타입입니다. 필요에 따라 이 값을 수정할 수 있습니다. - call에는
inputs와output이 있을 수 있습니다.inputs는 생성 시 정의되고,output은 call이 완료될 때 정의됩니다.
결과: 트레이스가 Weave에 기록됩니다
보너스: 트레이스를 내보내 정교한 평가를 수행하세요!
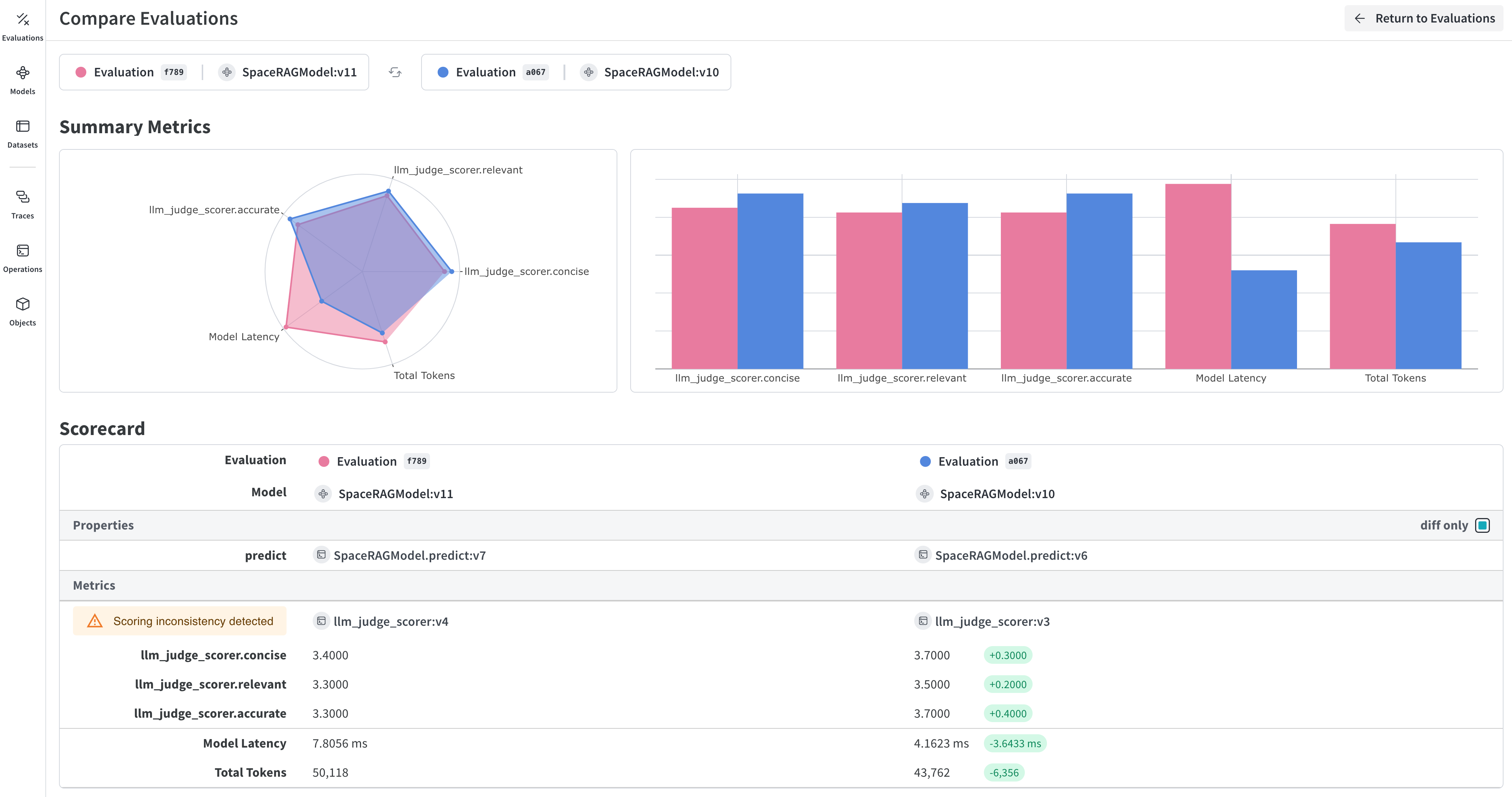
결과