Premiers pas
uv (comme le recommandent les auteurs de la bibliothèque). Utilisez l’une des commandes suivantes pour installer la bibliothèque :
Tracer les rollouts et évaluer
Affiner un modèle avec le suivi des expériences et le Tracing
verifiers inclut des exemples prêts à l’emploi pour vous aider à démarrer.
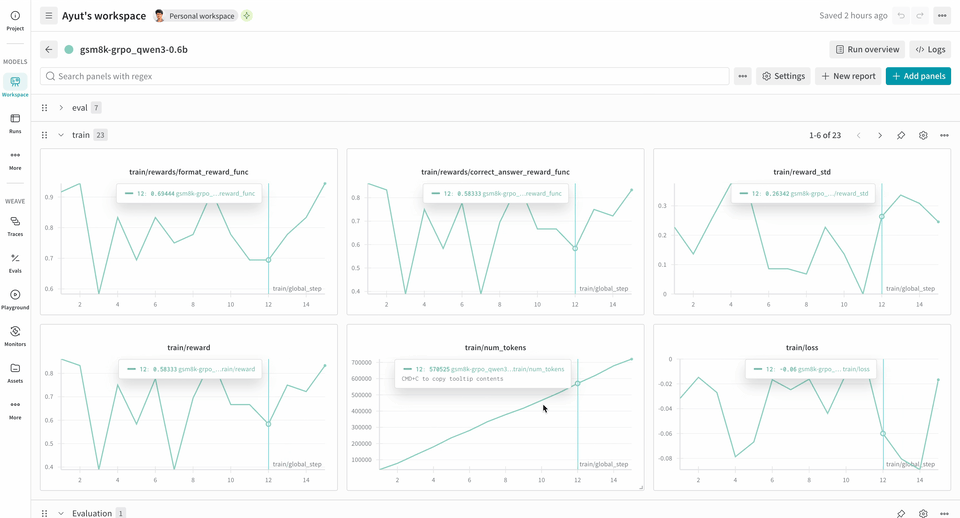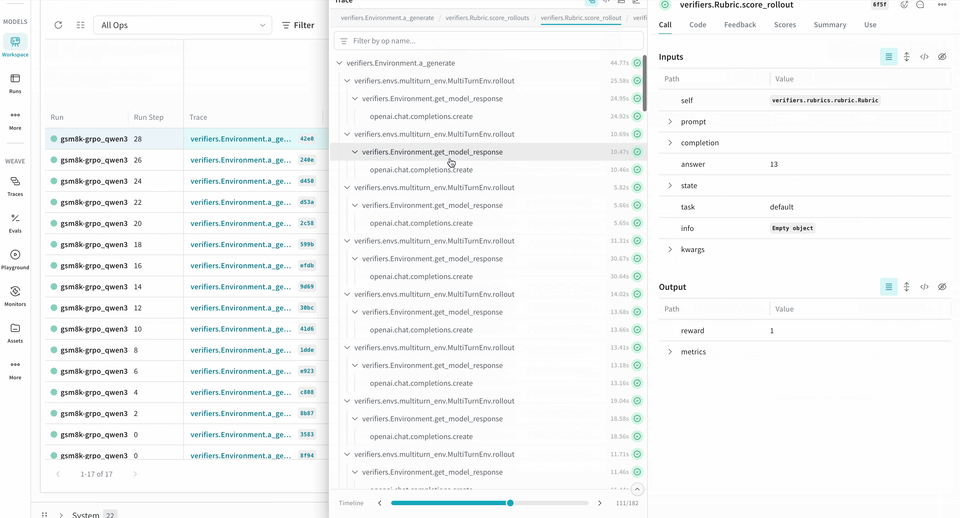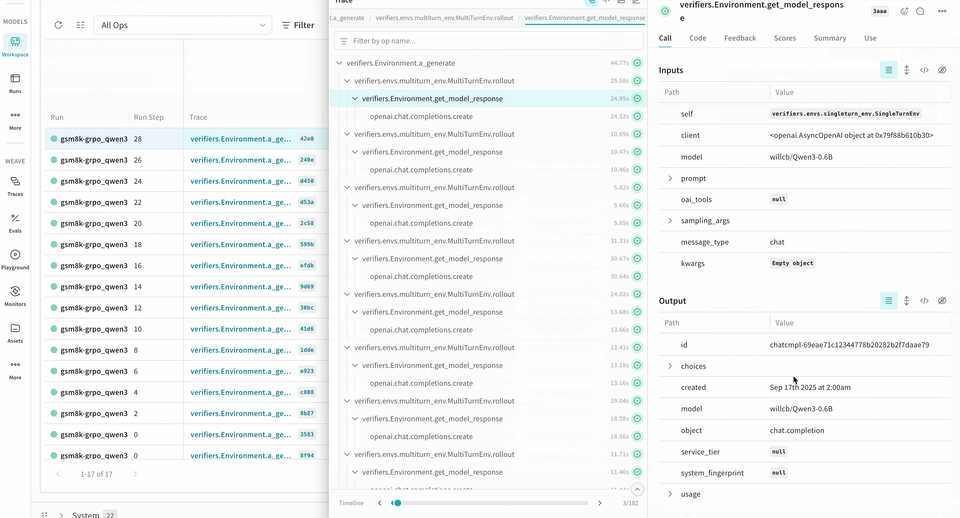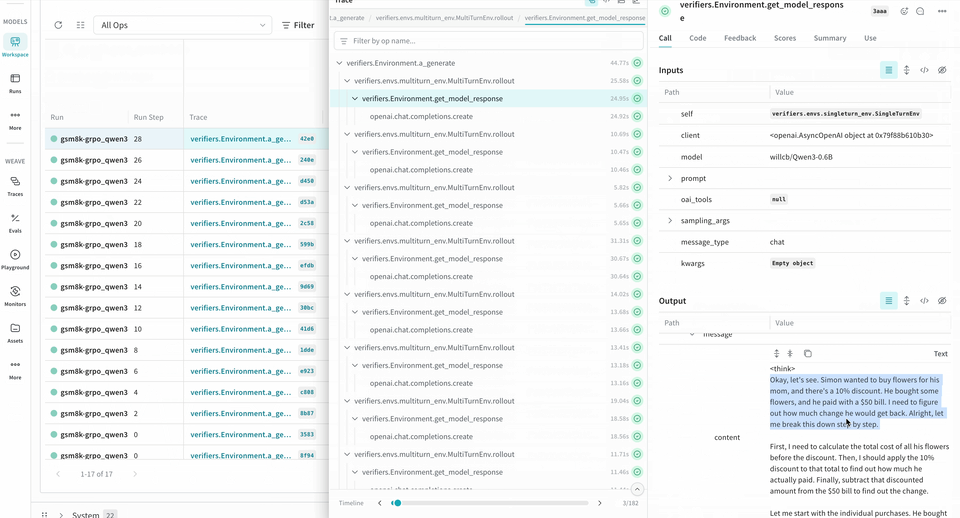
L’exemple suivant de pipeline d’entraînement RL exécute un serveur d’Inférence local et entraîne un modèle à l’aide du jeu de données GSM8K. Le modèle fournit des réponses aux problèmes de mathématiques, et la boucle d’entraînement attribue un score à la sortie puis met à jour le modèle en conséquence. W&B enregistre les métriques d’entraînement, comme la perte, la récompense et l’exactitude, tandis que Weave capture l’entrée, la sortie, le raisonnement et l’évaluation.
Pour utiliser ce pipeline :
- Installez le framework depuis la source. Les commandes suivantes installent la bibliothèque Verifiers depuis GitHub ainsi que les dépendances nécessaires :
- Installez un environnement prêt à l’emploi. La commande suivante installe l’environnement d’entraînement GSM8K préconfiguré :
- Entraînez votre modèle. Les commandes suivantes lancent respectivement le serveur d’inférence et la boucle d’entraînement. Dans cet exemple de flux de travail,
report_to=wandbest défini par défaut, vous n’avez donc pas besoin d’appelerwandb.initséparément. Vous serez invité à authentifier cette machine pour consigner des métriques sur W&B.
Nous avons testé avec succès cet exemple sur 2xH100 et défini les variables d’environnement suivantes pour améliorer la stabilité :Ces variables désactivent la mémoire unifiée CUDA (CuMem) pour les allocations de mémoire sur le périphérique.
logprobs pour les méthodes Environment.a_generate et Rubric.score_rollouts. Cela permet de limiter la taille des charges utiles tout en conservant les données d’origine intactes pour l’entraînement.