Il s’agit d’un notebook interactif. Vous pouvez l’exécuter en local ou utiliser les liens ci-dessous :
Comment utiliser Weave avec des données PII
- Les expressions régulières pour identifier les données PII et les masquer.
- Presidio de Microsoft, un SDK de protection des données basé sur Python. Cet outil offre des fonctionnalités de masquage et de remplacement.
- Faker, une bibliothèque Python permettant de générer de fausses données, combinée à Presidio pour anonymiser les données PII.
weave.op et autopatch_settings pour intégrer le masquage et l’anonymisation des données PII au flux de travail. Pour plus d’informations, voir Personnaliser les entrées et sorties journalisées.
Pour commencer, procédez comme suit :
- Consultez la section Aperçu.
- Complétez les prérequis.
- Consultez les méthodes disponibles pour identifier, masquer et anonymiser les données PII.
- Appliquez les méthodes aux appels Weave.
Aperçu
weave.op, ainsi que des bonnes pratiques pour travailler avec des données PII dans Weave.
Personnaliser la journalisation des entrées et des sorties à l’aide de weave.op
weave.op().
Bonnes pratiques d’utilisation de Weave avec des données PII
Lors des tests
- Journalisez des données anonymisées pour vérifier la détection des PII
- Suivez les processus de gestion des PII avec Weave Traces
- Mesurez les performances de l’anonymisation sans exposer de véritables PII
En production
- Ne journalisez jamais de PII en clair
- Chiffrez les champs sensibles avant de les journaliser
Conseils en matière de chiffrement
- Utilisez un chiffrement réversible pour les données que vous devrez déchiffrer ultérieurement
- Utilisez un hachage à sens unique pour les ID uniques que vous n’avez pas besoin de rétablir
- Envisagez un chiffrement spécialisé pour les données que vous devez analyser tout en restant chiffrées
Prérequis
- Commencez par installer les packages requis.
- Créez des clés API ici :
- Initialisez votre projet Weave.
- Chargez le jeu de données de démonstration PII, qui contient 10 blocs de texte.
Aperçu des méthodes de masquage
- Expressions régulières pour identifier les données PII et les masquer.
- Microsoft Presidio, un SDK Python de protection des données qui offre des fonctionnalités de masquage et de remplacement.
- Faker, une bibliothèque Python permettant de générer de fausses données.
Méthode 1 : Filtrer à l’aide d’expressions régulières
Méthode 2 : Masquer à l’aide de Microsoft Presidio
Alex dans "My name is Alex" par <PERSON>.
Presidio prend en charge nativement les entités courantes. Dans l’exemple ci-dessous, nous masquons toutes les entités de type PHONE_NUMBER, PERSON, LOCATION, EMAIL_ADDRESS ou US_SSN. Le traitement Presidio est encapsulé dans une fonction.
Méthode 3 : anonymiser par remplacement à l’aide de Faker et Presidio
"My name is Raphael and I like to fish. My phone number is 212-555-5555"
Une fois les données traitées avec Presidio et Faker, elles peuvent ressembler à ceci :
"My name is Katherine Dixon and I like to fish. My phone number is 667.431.7379"
Pour utiliser efficacement Presidio et Faker ensemble, nous devons fournir des références à nos opérateurs personnalisés. Ces opérateurs indiqueront à Presidio quelles fonctions Faker utiliser pour remplacer les PII par des données factices.
Méthode 4 : Utiliser autopatch_settings
autopatch_settings pour configurer la gestion des PII directement lors de l’initialisation pour une ou plusieurs intégrations LLM prises en charge. Les avantages de cette méthode sont les suivants :
- La logique de gestion des PII est centralisée et définie à l’initialisation, ce qui réduit le besoin de logique personnalisée dispersée.
- Les flux de travail de traitement des PII peuvent être personnalisés ou entièrement désactivés pour des intégrations spécifiques.
autopatch_settings afin de configurer la gestion des PII, définissez postprocess_inputs et/ou postprocess_output dans op_settings pour l’une des intégrations LLM prises en charge.
Appliquer les méthodes aux appels Weave
predict, dans laquelle l’API Anthropic sera appelée. Claude Sonnet d’Anthropic est utilisé pour effectuer une analyse de sentiment tout en traçant les appels LLM à l’aide de Traces. Claude Sonnet recevra un bloc de texte et renverra l’une des classifications de sentiment suivantes : positive, negative ou neutral. De plus, nous inclurons nos fonctions de post-traitement afin de garantir que nos données PII sont masquées ou anonymisées avant d’être envoyées au LLM.
Une fois ce code exécuté, vous recevrez des liens vers la page du projet Weave ainsi que vers la trace spécifique (appels LLM) que vous avez exécutée.
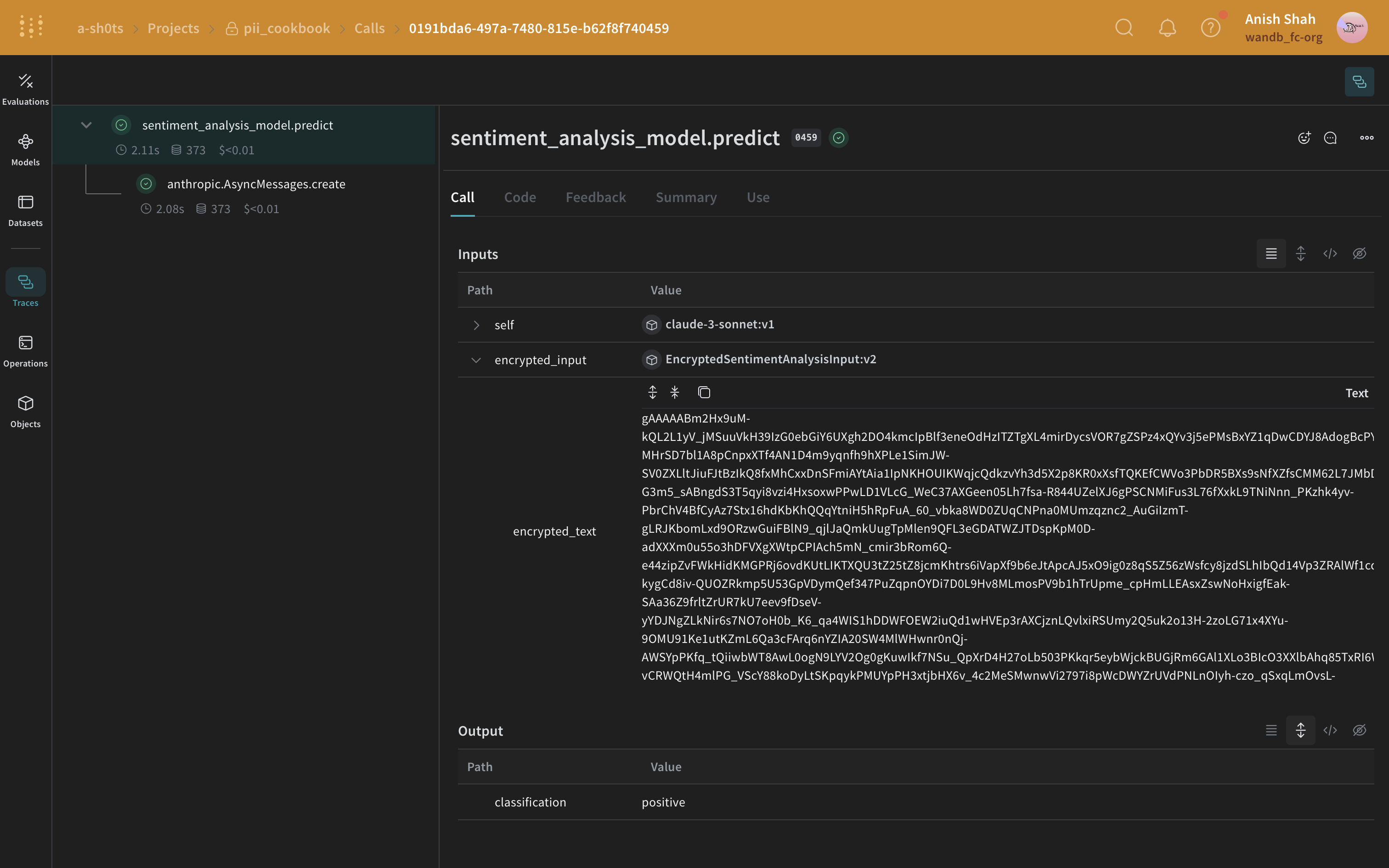
Méthode regex
Méthode de masquage avec Presidio
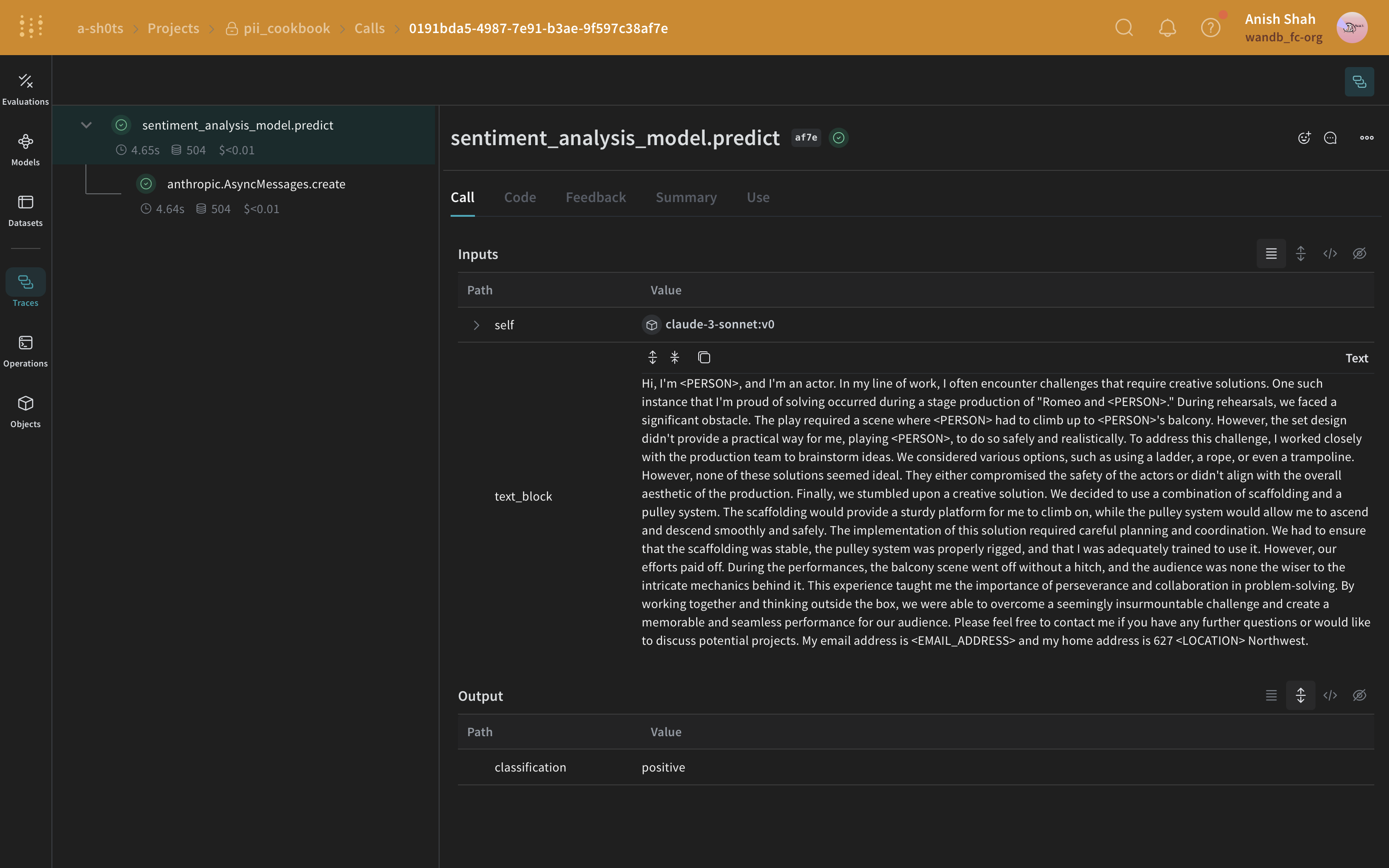
Méthode de remplacement avec Faker et Presidio
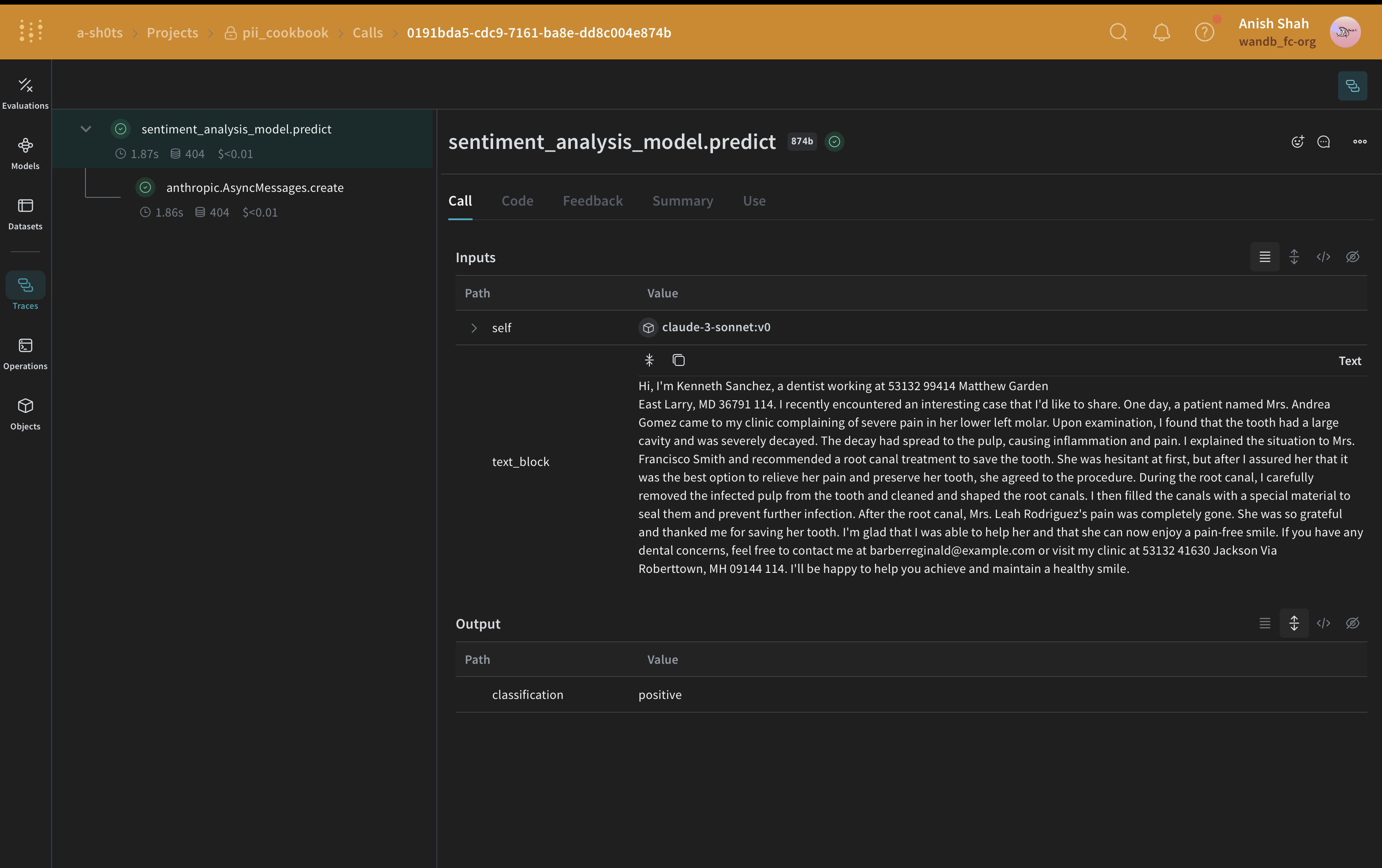
méthode autopatch_settings
postprocess_inputs pour anthropic à la fonction postprocess_inputs_regex() () lors de l’initialisation. La fonction postprocess_inputs_regex applique la méthode redact_with_regex définie dans Méthode 1 : filtrage par expression régulière. Désormais, redact_with_regex sera appliquée à toutes les entrées de n’importe quel modèle anthropic.
(Facultatif) Chiffrez vos données