Il s’agit d’un notebook interactif. Vous pouvez l’exécuter localement ou utiliser les liens ci-dessous :
Importer des traces depuis des systèmes tiers
csv ou json.
Dans ce cookbook, nous explorons l’API Python de bas niveau de Weave pour extraire des données d’un fichier CSV et les importer dans Weave afin d’en tirer des enseignements et de réaliser des évaluations rigoureuses.
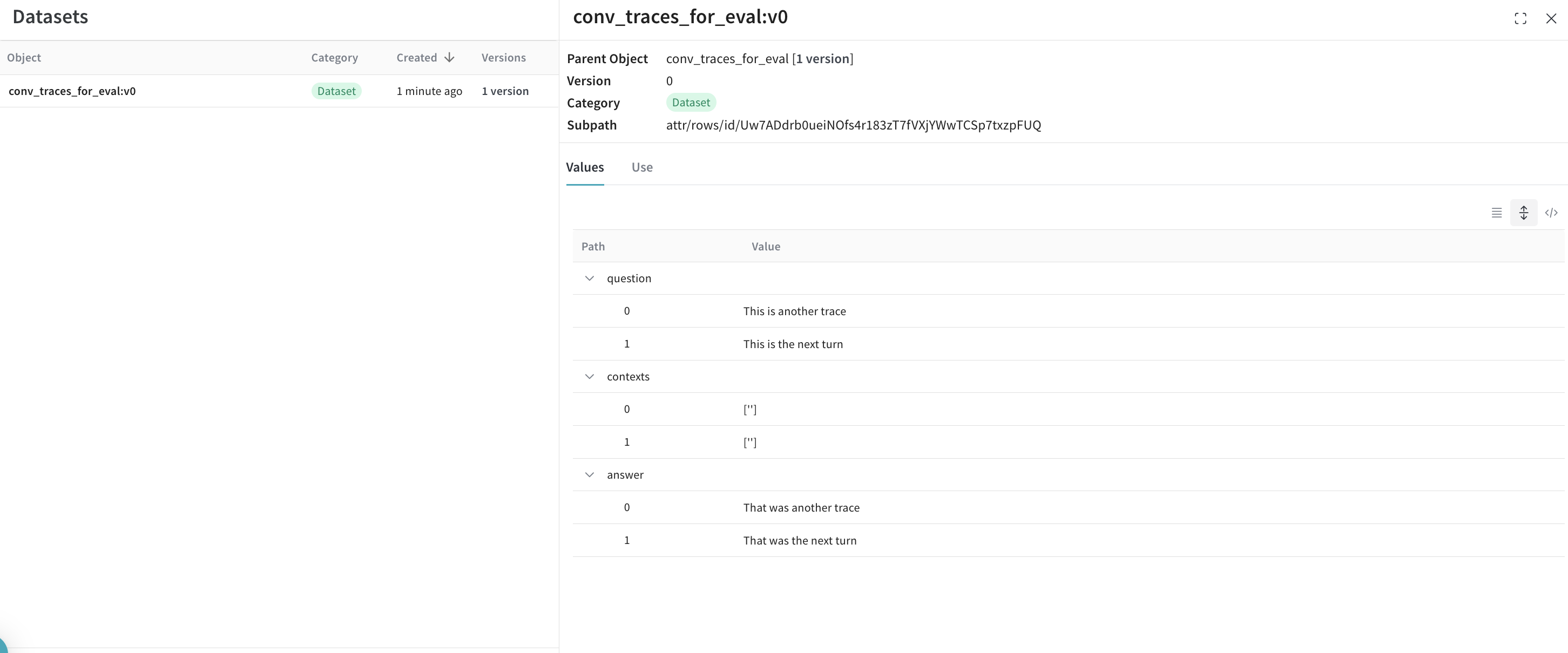
Le jeu de données d’exemple utilisé dans ce cookbook a la structure suivante :
conversation_id comme identifiant du parent, et turn_index comme identifiant de l’enfant afin de disposer d’une journalisation complète des conversations.
Veillez à modifier les variables selon vos besoins.
Configurer l’environnement
WANDB_API_KEY dans notre environnement afin de pouvoir nous connecter facilement avec wandb.login() (cela doit être fourni à colab en tant que secret).
Nous définissons le nom du fichier que nous importons dans colab dans name_of_file, puis le projet W&B dans lequel nous voulons enregistrer cela dans name_of_wandb_project.
REMARQUE : name_of_wandb_project peut aussi être au format {team_name}/{project_name} pour spécifier une équipe dans laquelle enregistrer les traces.
Nous récupérons ensuite un client Weave en appelant weave.init()
Chargement des données
conversation_id et turn_index afin que les éléments parents et enfants soient correctement ordonnés.
On obtient ainsi un dataframe Pandas à deux colonnes, avec nos tours de conversation sous forme de tableau dans conversation_data.
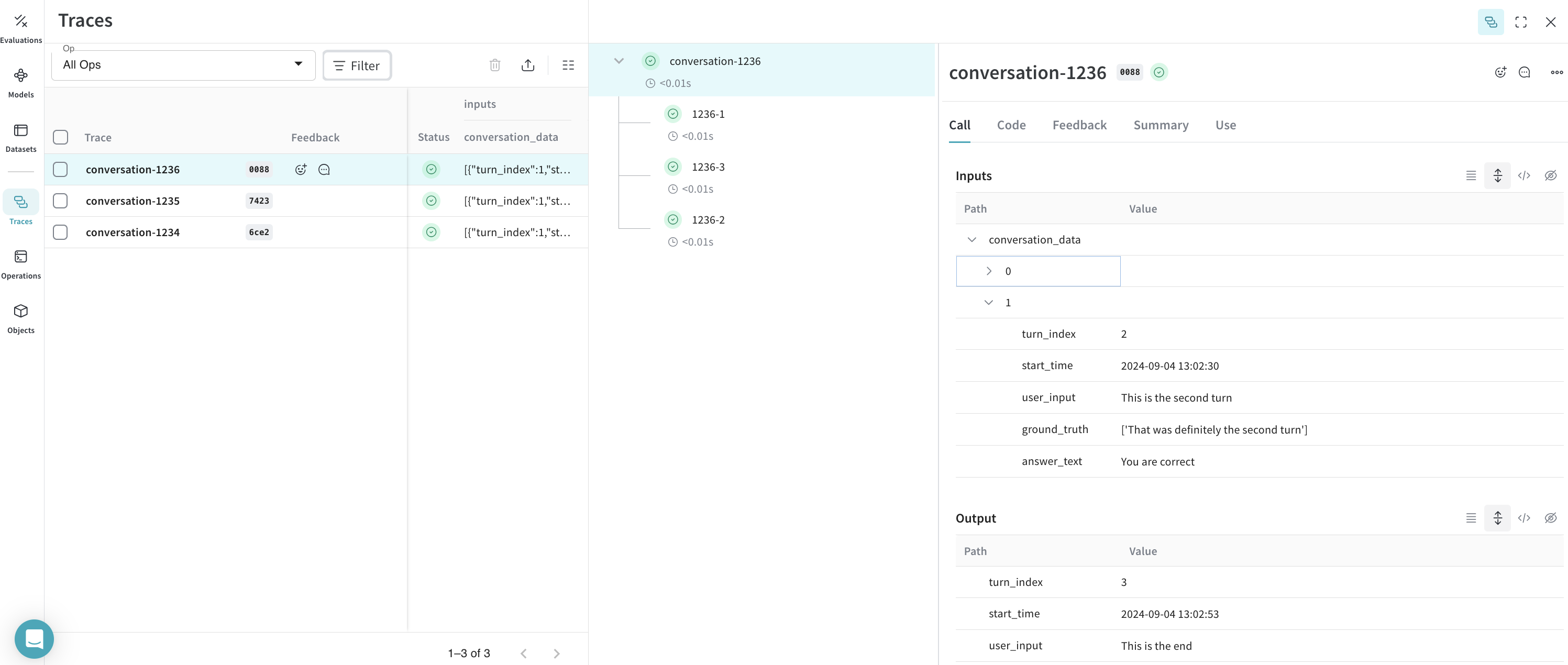
Journaliser les traces dans Weave
- Nous créons un appel parent pour chaque
conversation_id - Nous parcourons le tableau des tours pour créer des appels enfants, triés selon leur
turn_index
- Un appel Weave est équivalent à une trace Weave ; cet appel peut avoir un parent ou des enfants qui lui sont associés
- Un appel Weave peut également avoir d’autres éléments qui lui sont associés : Feedback, Metadata, etc. Ici, nous ne lui associons que des entrées et des sorties, mais vous pouvez vouloir ajouter ces éléments lors de l’importation si les données les fournissent.
- Un appel Weave est
createdpuisfinished, car ces événements sont conçus pour être suivis en temps réel. Comme il s’agit ici d’une importation a posteriori, nous créons et terminons l’appel une fois que nos objets sont définis et liés entre eux. - La valeur
opd’un appel correspond à la façon dont Weave catégorise des appels de même nature. Dans cet exemple, tous les appels parents sont de typeConversation, et tous les appels enfants sont de typeTurn. Vous pouvez modifier cela comme bon vous semble. - Un appel peut avoir des
inputset unoutput. Lesinputssont définis lors de la création et l’outputest défini lorsque l’appel est terminé.
Résultat : les traces sont enregistrées dans Weave
Bonus : exportez vos traces pour réaliser des évaluations rigoureuses !
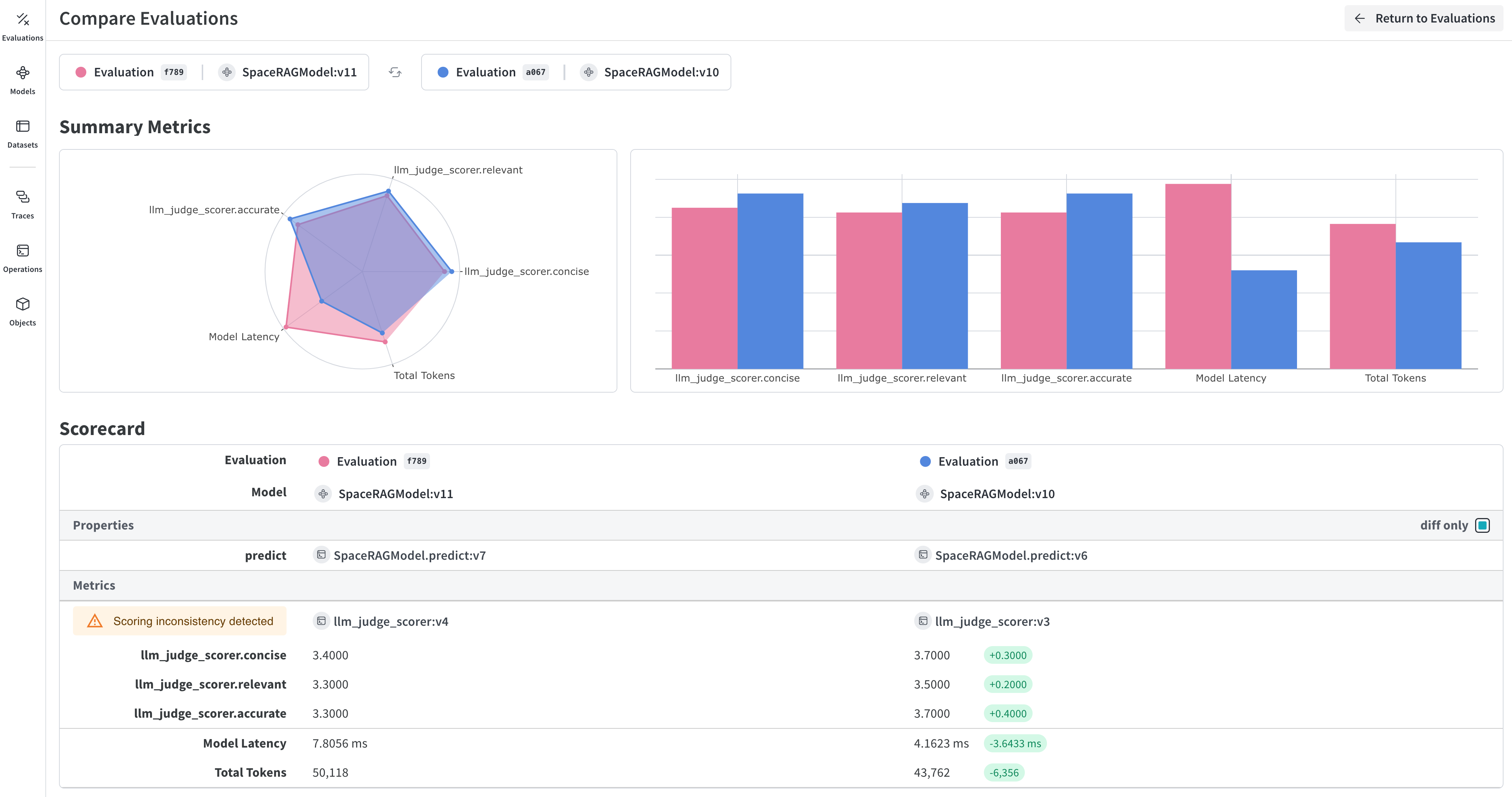
Résultat