Exemple de base : Tracing de Llama 3.1 8B avec Weave
- Vous définissez une fonction décorée avec
@weave.op()qui effectue une requête de Chat Completion - Vos traces sont enregistrées et associées à votre entité et à votre projet W&B
- La fonction est automatiquement tracée, avec journalisation des entrées, des sorties, de la latence et des métadonnées
- Le résultat s’affiche dans le terminal, et la trace apparaît dans votre onglet Traces sur https://wandb.ai
- Cliquez sur le lien affiché dans le terminal (par exemple :
https://wandb.ai/<your-team>/<your-project>/r/call/01977f8f-839d-7dda-b0c2-27292ef0e04g) - Ou accédez à https://wandb.ai et sélectionnez l’onglet Traces
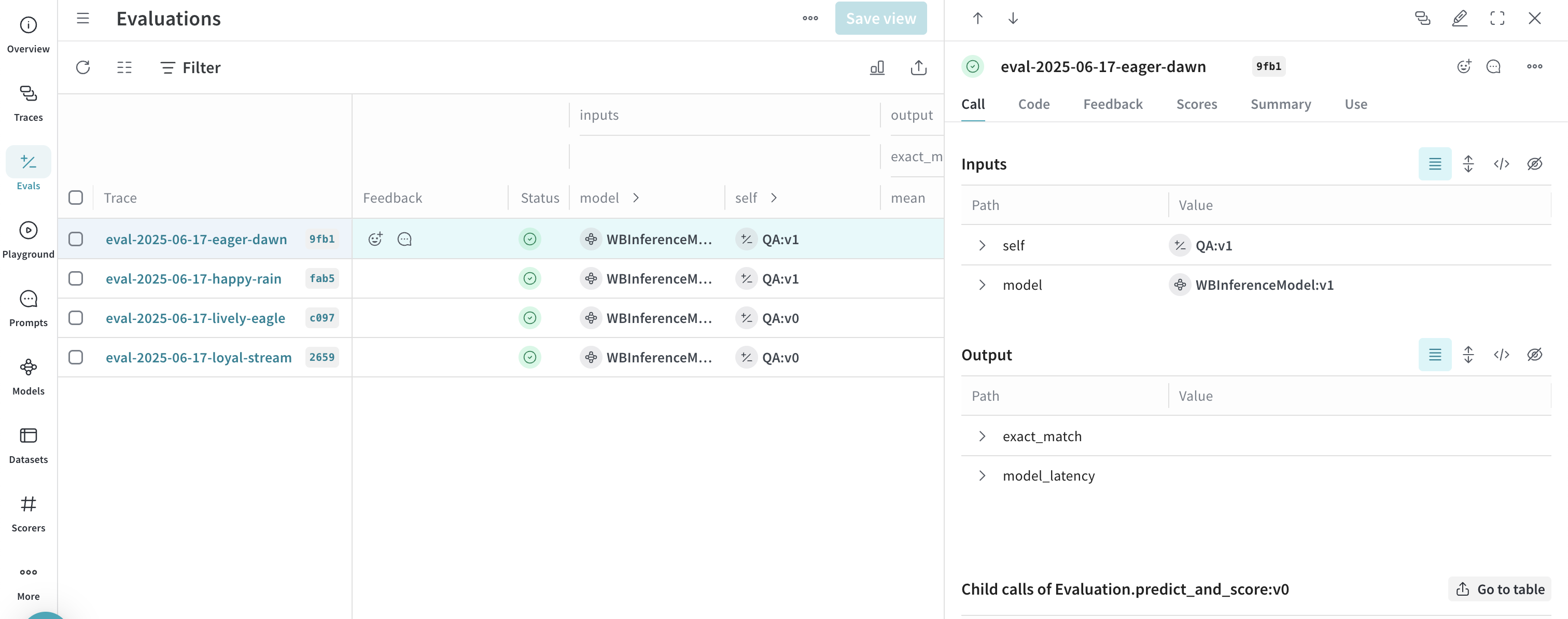
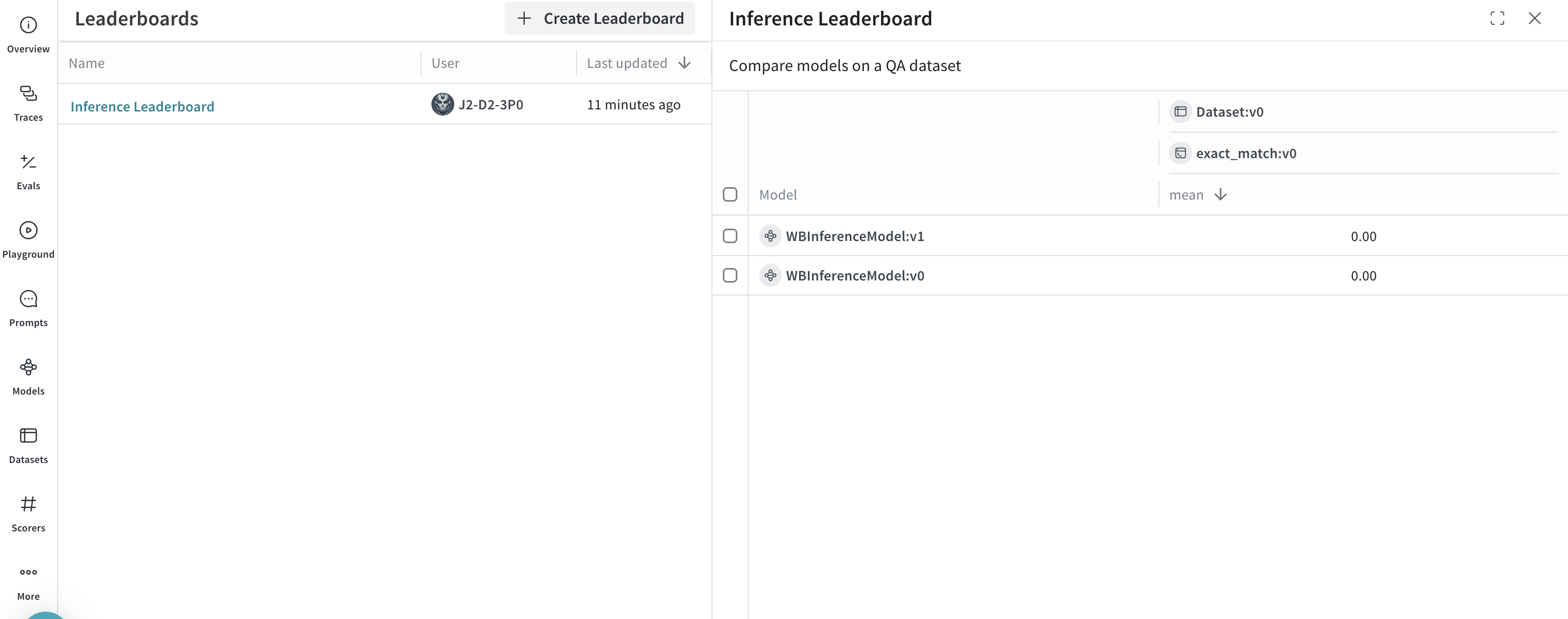
Exemple avancé : utiliser Weave Evaluations et les classements
- Sélectionnez l’onglet Traces pour consulter vos traces
- Sélectionnez l’onglet Evals pour consulter les évaluations de votre modèle
- Sélectionnez l’onglet Leaders pour consulter le classement généré
Étapes suivantes
- Explorez la référence de l’API pour découvrir toutes les méthodes disponibles
- Essayez des modèles dans l’UI