wandb==0.12.11 et nécessite kfp<2.0.0
Inscrivez-vous et créez une clé API
Pour une méthode plus directe, créez une clé API en accédant directement aux Paramètres utilisateur. Copiez immédiatement la clé API nouvellement créée et conservez-la dans un endroit sûr, par exemple dans un gestionnaire de mots de passe.
- Cliquez sur l’icône de votre profil utilisateur dans l’angle supérieur droit.
- Sélectionnez Paramètres utilisateur, puis faites défiler jusqu’à la section Clés API.
Installez la bibliothèque wandb et connectez-vous
wandb localement et vous connecter :
- Ligne de commande
- Python
- Python notebook
-
Définissez la variable d’environnement
WANDB_API_KEYavec votre clé API. -
Installez la bibliothèque
wandbet connectez-vous.
Décorez vos composants
@wandb_log et créez vos composants comme d’habitude. Cela journalisera automatiquement dans W&B les paramètres d’entrée/sortie et les artifacts chaque fois que vous exécutez votre pipeline.
Transmettre des variables d’environnement aux conteneurs
WANDB_KUBEFLOW_URL avec l’URL de base de votre instance Kubeflow Pipelines. Par exemple, https://kubeflow.mysite.com.
Accédez à vos données de manière programmatique
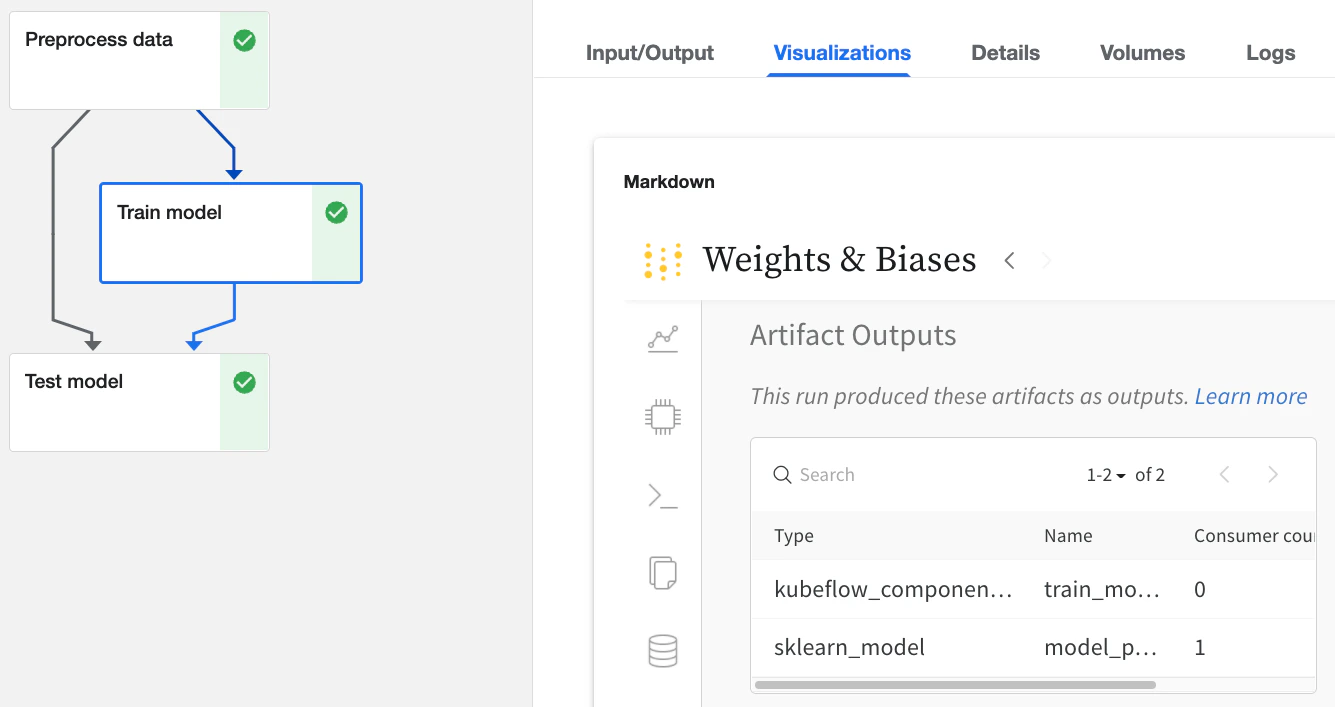
Via l’UI de Kubeflow Pipelines
- Consultez les détails des entrées et des sorties dans les onglets
Input/OutputetML Metadata. - Consultez l’application web W&B depuis l’onglet
Visualizations.
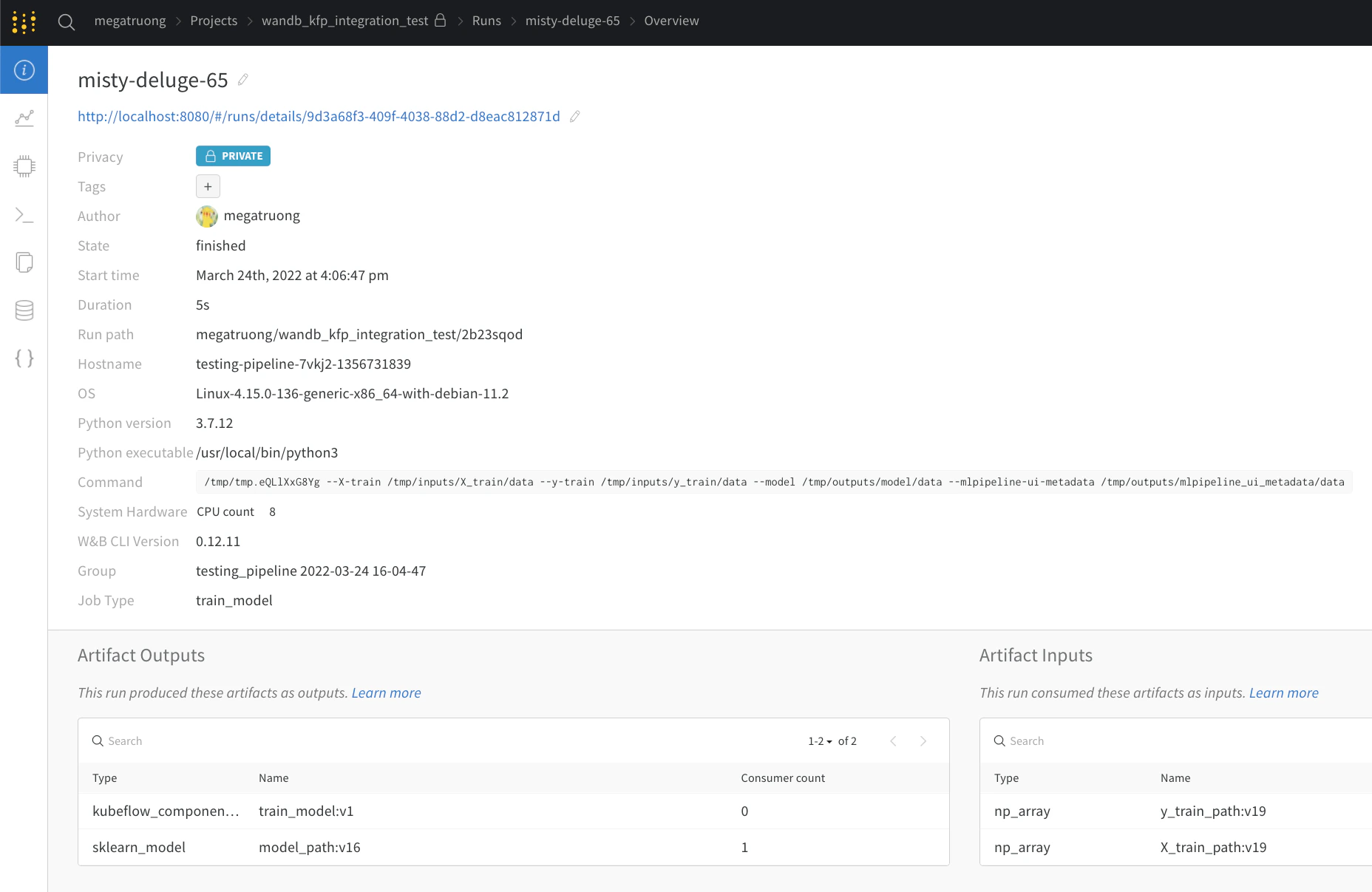
Via l’interface de l’application web
Visualizations dans Kubeflow Pipelines, mais avec davantage d’espace. En savoir plus sur l’interface de l’application web ici.
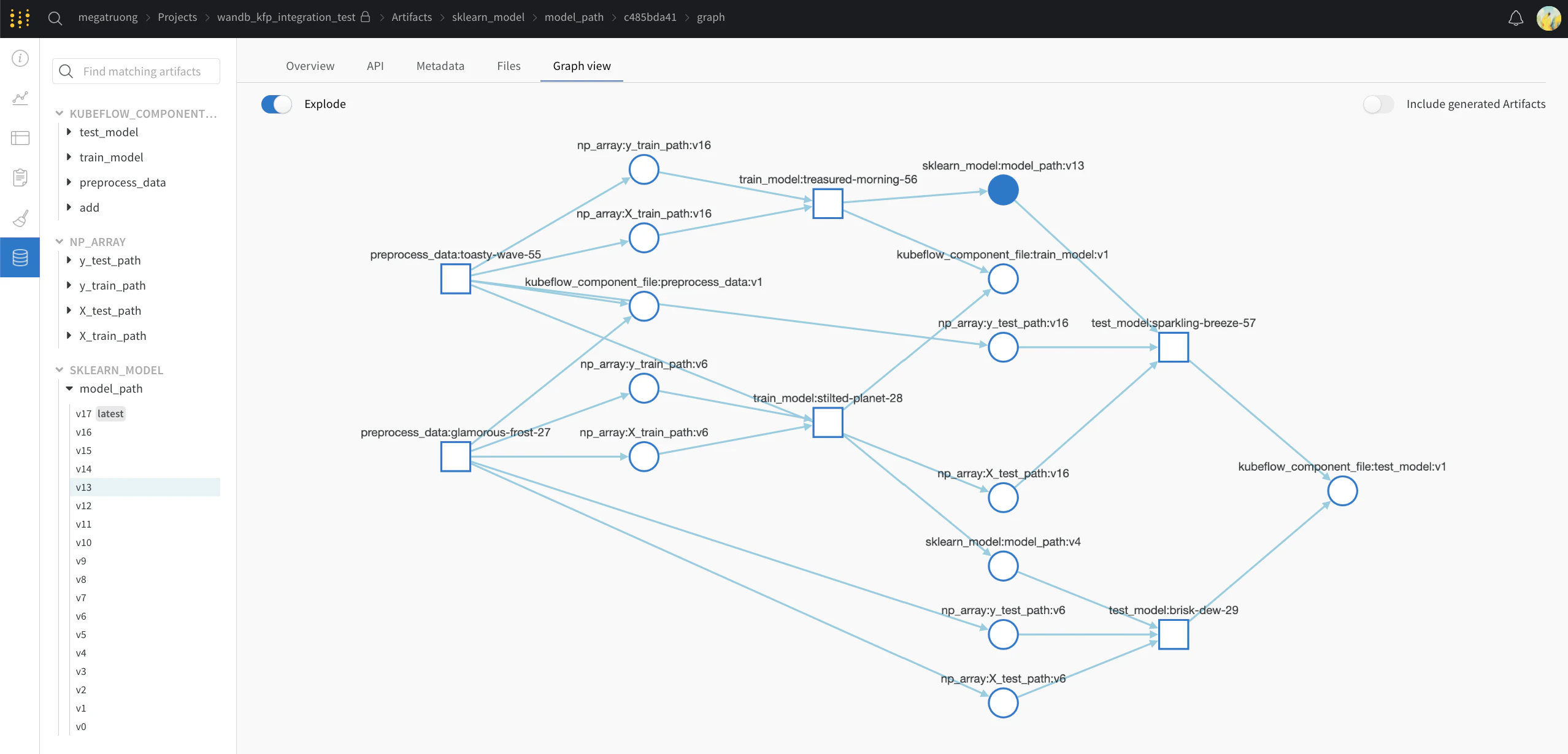
Via l’API publique (pour un accès programmatique)
- Pour un accès programmatique, voir notre API publique.
Correspondance des concepts entre Kubeflow Pipelines et W&B
| Kubeflow Pipelines | W&B | Emplacement dans W&B |
|---|---|---|
| Scalaire d’entrée | config | onglet Vue d’ensemble |
| Scalaire de sortie | summary | onglet Vue d’ensemble |
| Artifact d’entrée | Artifact d’entrée | onglet Artifacts |
| Artifact de sortie | Artifact de sortie | onglet Artifacts |
Journalisation granulaire
wandb.log et wandb.log_artifact dans le composant.
Avec des appels explicites à wandb.log_artifacts
@wandb_log suivra automatiquement les entrées et sorties pertinentes. Si vous souhaitez également journaliser le processus d’entraînement, vous pouvez l’ajouter explicitement comme suit :