사전 요구 사항 설치
autotrain-advanced와 wandb를 설치합니다.
- 명령줄
- 노트북
pass@1 기준 SoTA 결과를 달성합니다.
데이터셋 준비
-
트레이닝 파일에는 트레이닝에 사용하는
text열이 반드시 포함되어야 합니다. 최상의 결과를 얻으려면text열의 데이터가### Human: Question?### Assistant: Answer.형식을 따라야 합니다. 좋은 예시는timdettmers/openassistant-guanaco에서 확인할 수 있습니다. 하지만 MetaMathQA 데이터셋에는query,response,type열이 포함되어 있습니다. 먼저 이 데이터셋을 전처리하세요.type열을 제거하고,query열과response열의 내용을### Human: Query?### Assistant: Response.형식의 새로운text열로 결합하세요. 트레이닝에는 이렇게 만든 데이터셋인rishiraj/guanaco-style-metamath을 사용합니다.
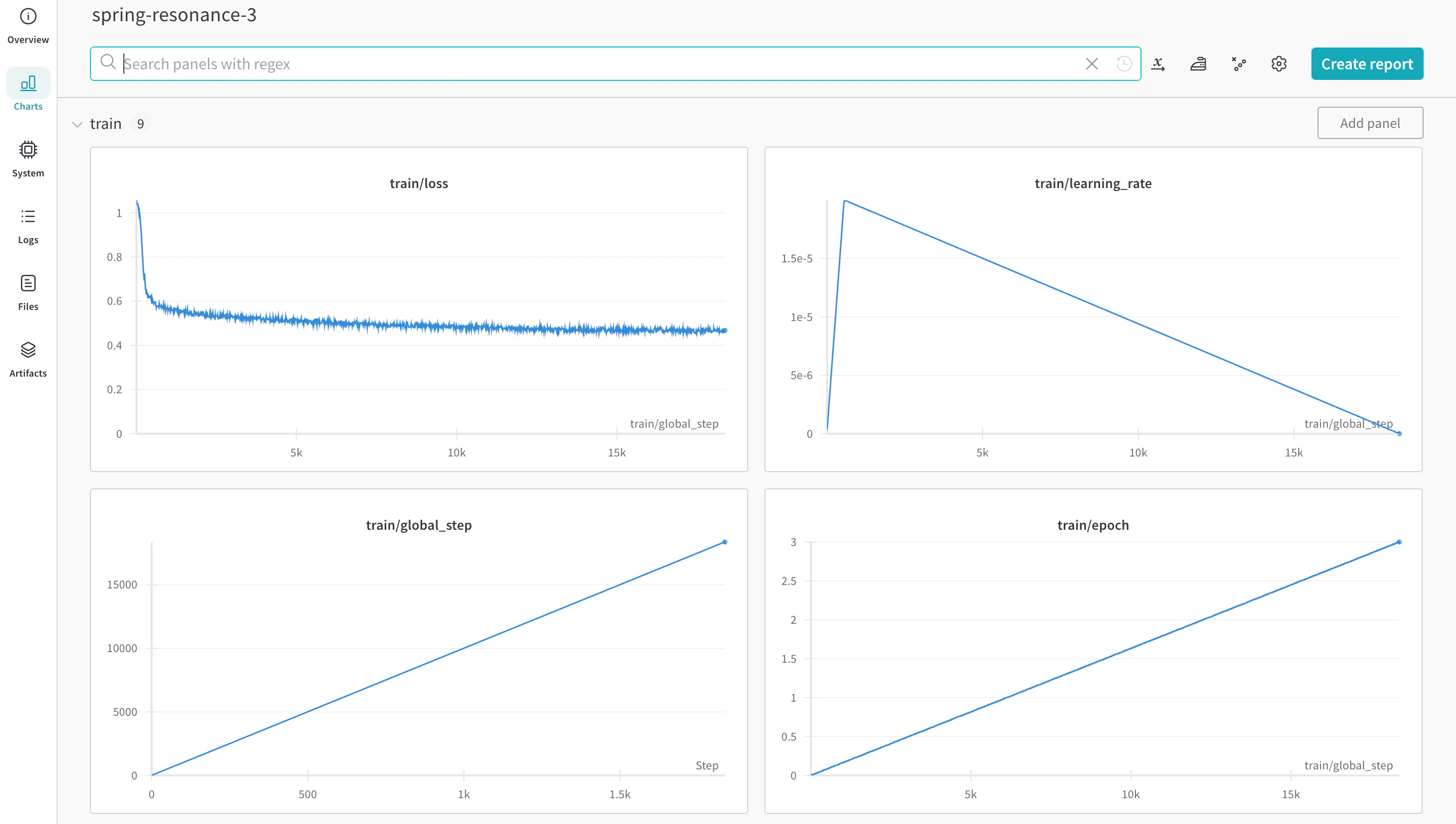
autotrain을 사용해 트레이닝하기
autotrain advanced를 사용해 트레이닝을 시작할 수 있습니다. --log 인수를 사용하거나 --log wandb를 사용해 결과를 W&B Run에 로깅하세요.
- 명령줄
- 노트북