Weave でモデルを評価する
モデル評価の主な機能
- Scorers と judges: 正確性、関連性、一貫性などを評価するための、あらかじめ用意されたものとカスタムの評価メトリクス
- Evaluation データセット: 系統的な評価のための、正解ラベル付きの構造化テストセット
- モデルバージョニング: 異なるバージョンのモデルを追跡・比較
- 詳細なトレース: 完全な入出力トレースによるモデル挙動のデバッグ
- コストトラッキング: 評価全体にわたる API コストとトークン使用量の監視
はじめに:W&B Registry のモデルを評価する
Weave の評価を W&B Models と連携させる
- Registry からモデルを読み込む: W&B Models Registry に保存されているファインチューニング済みモデルをダウンロードする
- 評価パイプラインを作成する: カスタムスコアラーを使って包括的な評価を構築する
- 結果を W&B にログする: 評価メトリクスをモデルの run と関連付ける
- 評価済みモデルにバージョンを付ける: 改良したモデルを Registry に保存し直す
Weave の高度な機能
カスタムスコアラーとジャッジ
バッチ評価
次のステップ
テーブルでモデルを評価する
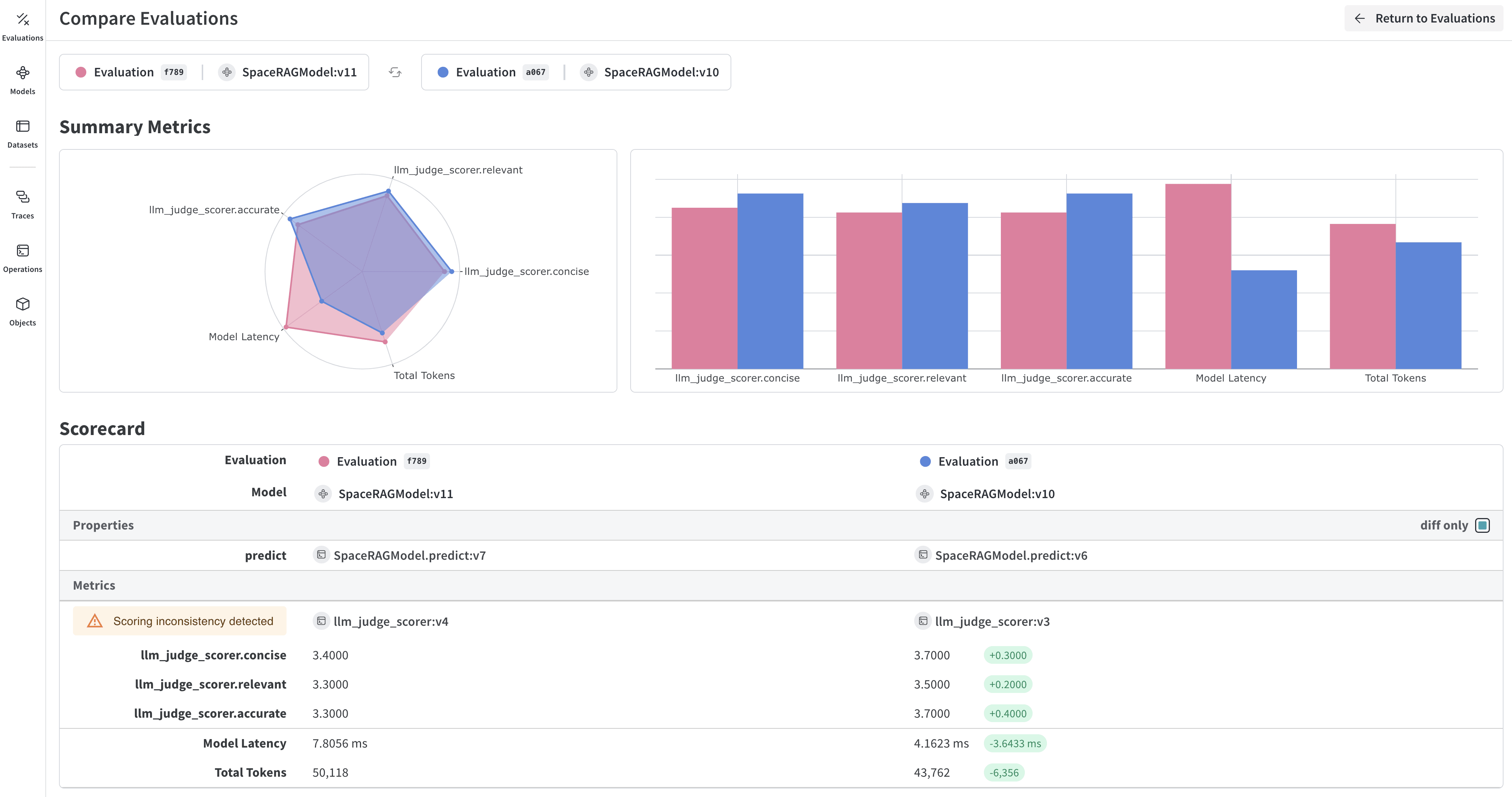
- モデル予測を比較する: 同じテストセットに対する異なるモデルの性能を、並べて比較表示する
- 予測の変化を追跡する: エポックをまたぐ学習過程やモデルバージョン間で、予測がどのように変化するかをモニタリングする
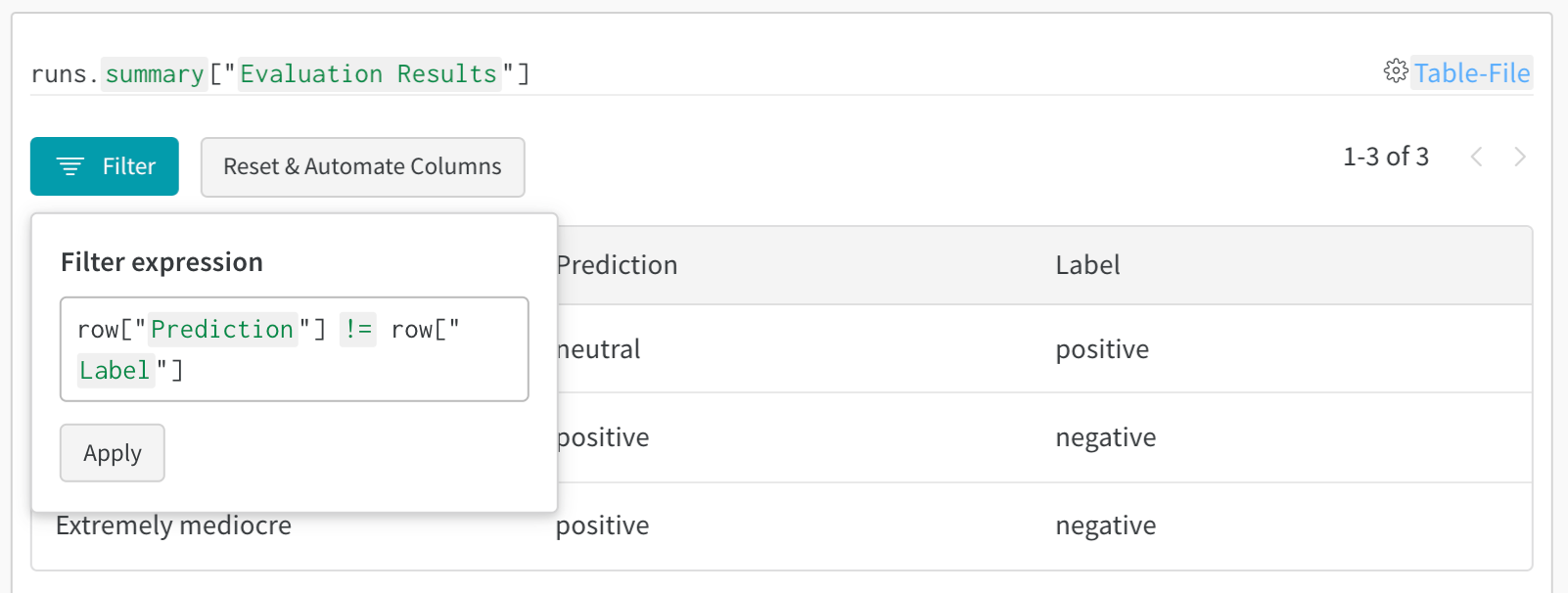
- エラーを分析する: よく誤分類されるサンプルやエラーパターンを見つけるために、フィルタやクエリを使う
- リッチメディアを可視化する: 画像、音声、テキストなどの各種メディアを、予測結果やメトリクスと並べて表示する
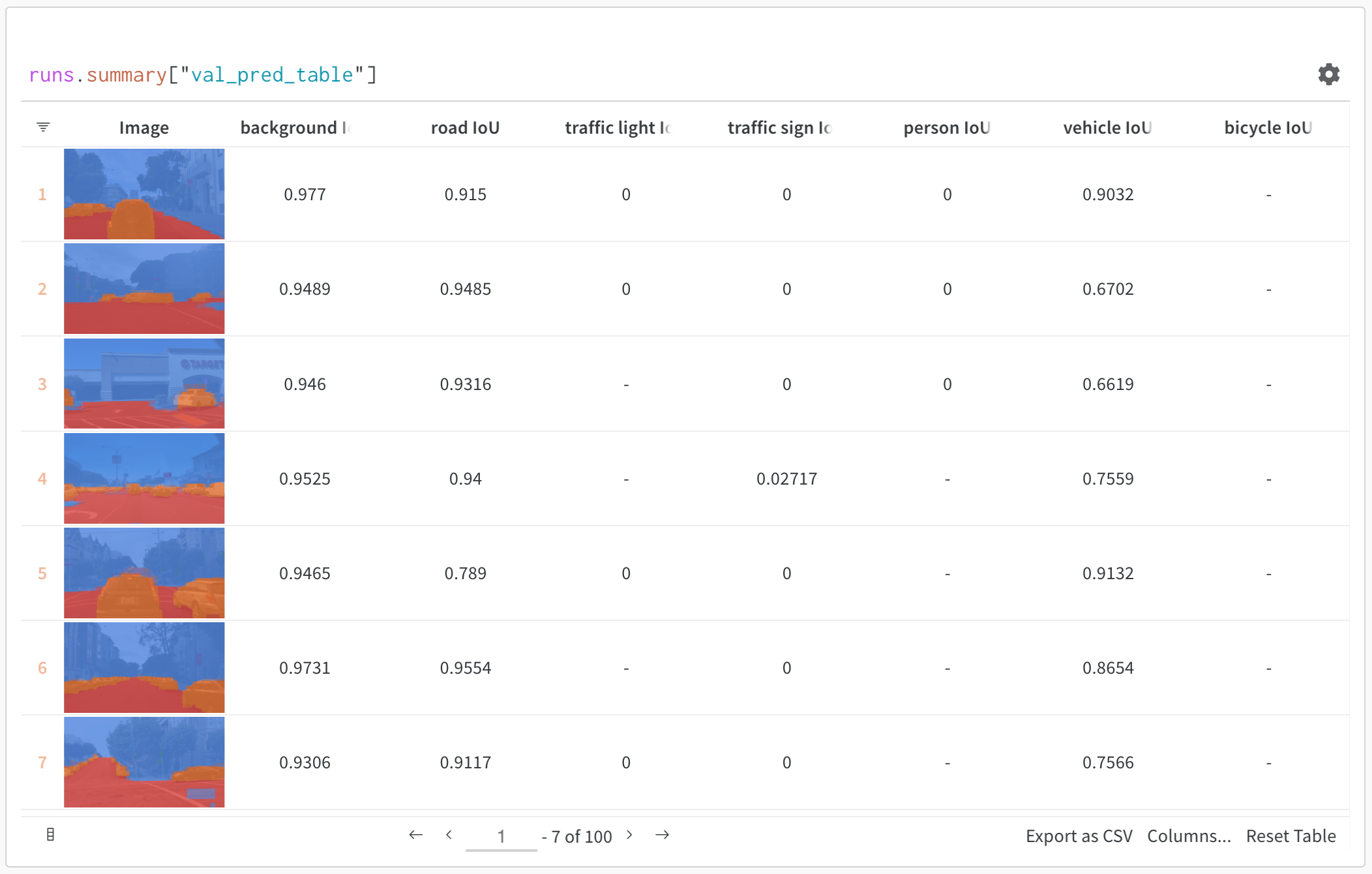
基本例: 評価結果をログとして記録する
テーブルの高度なワークフロー
複数のモデルを比較する
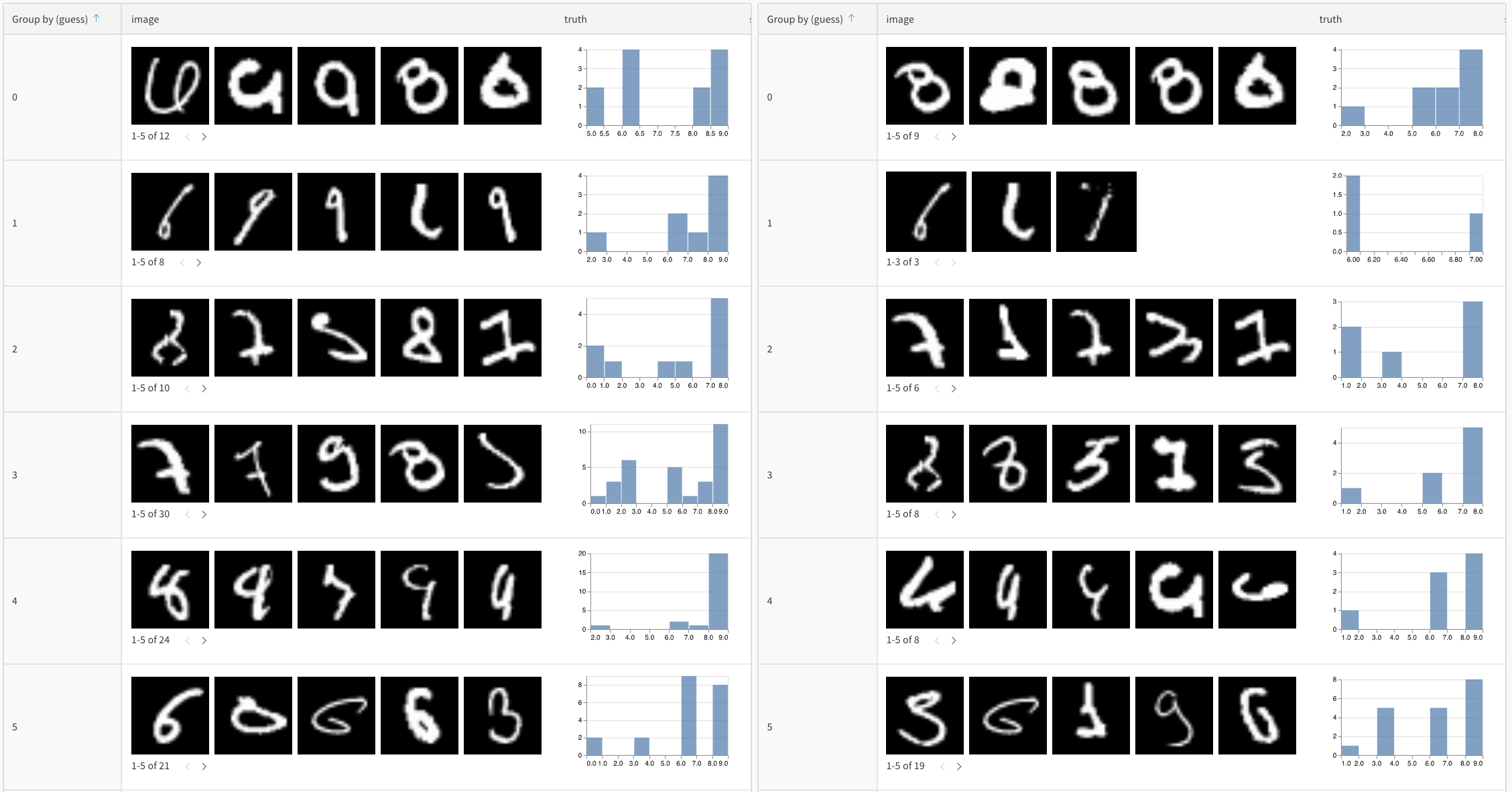
予測を経時的に追跡する
W&B UI でのインタラクティブな分析
- 結果をフィルター:列ヘッダーをクリックして、予測精度、信頼度のしきい値、特定のクラスで絞り込みます
- テーブルを比較:複数のテーブルバージョンを選択して、並べて比較できます
- データをクエリ:クエリバーを使って特定のパターンを検索します(例:
"correct" = false AND "confidence" > 0.8) - グループ化と集計:予測されたクラスごとにグループ化して、クラスごとの精度メトリクスを確認します