はじめに
サインアップしてAPIキーを発行する
より手早く行うには、User Settings に直接アクセスしてAPIキーを作成してください。新しく作成したAPIキーはすぐにコピーし、パスワードマネージャーなどの安全な場所に保存してください。
- 右上にあるユーザープロフィールアイコンをクリックします。
- User Settings を選択し、API Keys セクションまでスクロールします。
wandb ライブラリをインストールしてログインする
wandb ライブラリをローカルにインストールしてログインするには、次の手順を実行します。
- コマンドライン
- Python
- Python notebook
-
WANDB_API_KEYの環境変数に APIキー を設定します。 -
wandbライブラリをインストールし、ログインします。
メトリクスをログする
プロットを作成
Step 1: wandb をインポートして、新しい run を初期化する
Step 2: プロットを表示する
個別のプロット
すべてのプロット
plot_classifier のような関数があります。
既存のMatplotlibプロット
plotly をインストールする必要があります。
サポート対象のプロット
学習曲線
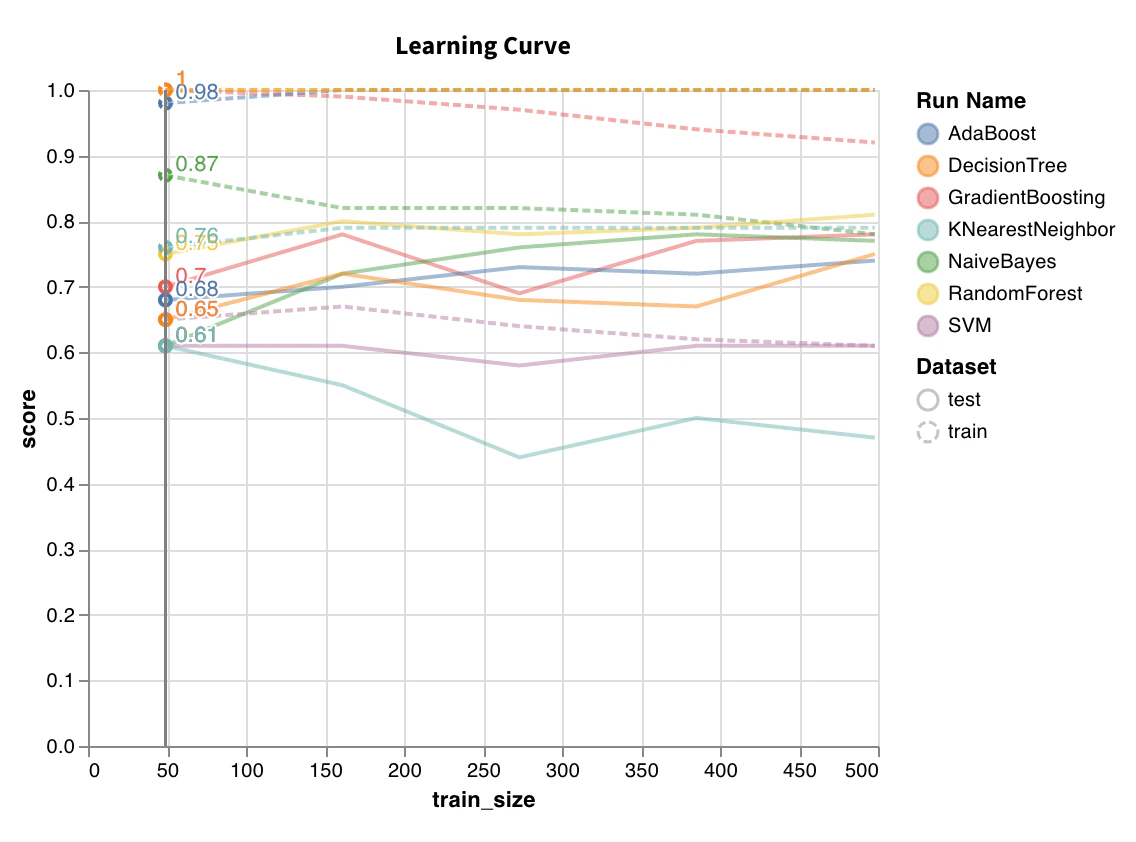
wandb.sklearn.plot_learning_curve(model, X, y)
- model (clf or reg): 学習済みの回帰モデルまたは分類器を受け取ります。
- X (arr): データセットの特徴量。
- y (arr): データセットのラベル。
ROC
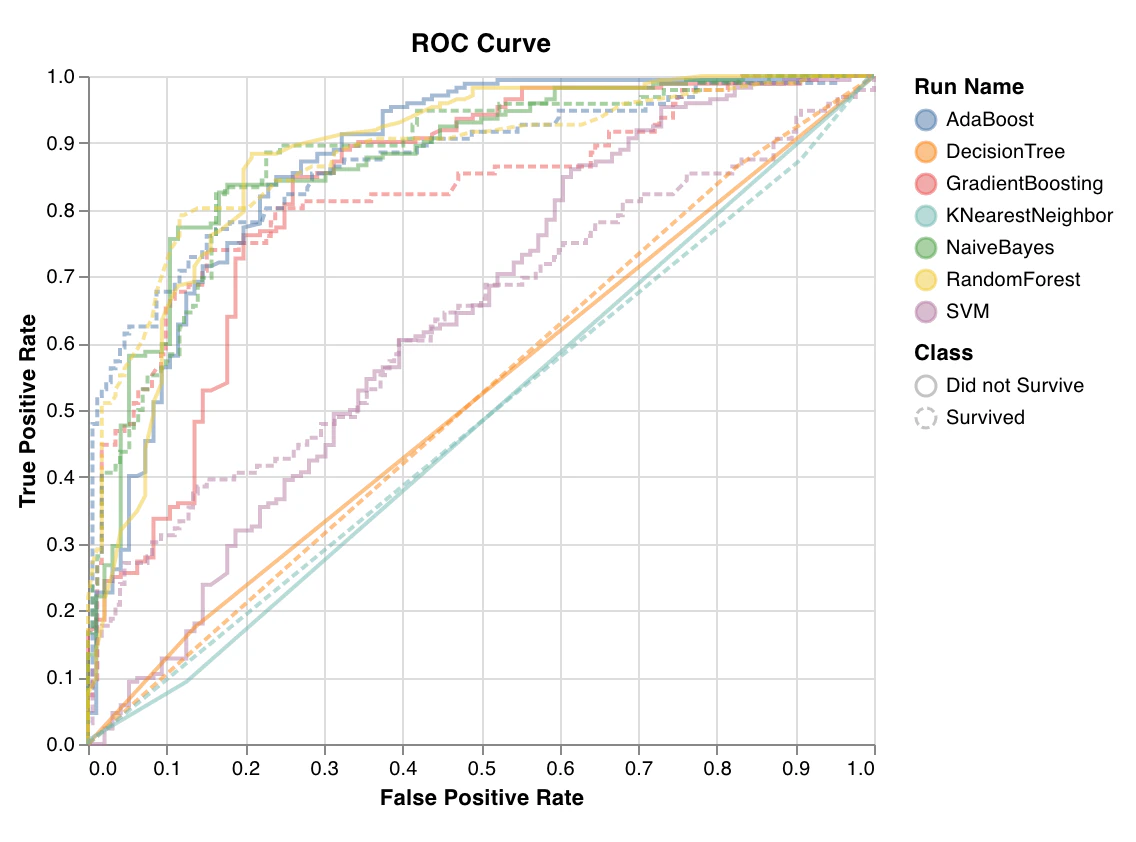
wandb.sklearn.plot_roc(y_true, y_probas, labels)
- y_true (arr): テストセットのラベル。
- y_probas (arr): テストセットの予測確率。
- labels (list): ターゲット変数 (y) のラベル名。
クラスの比率
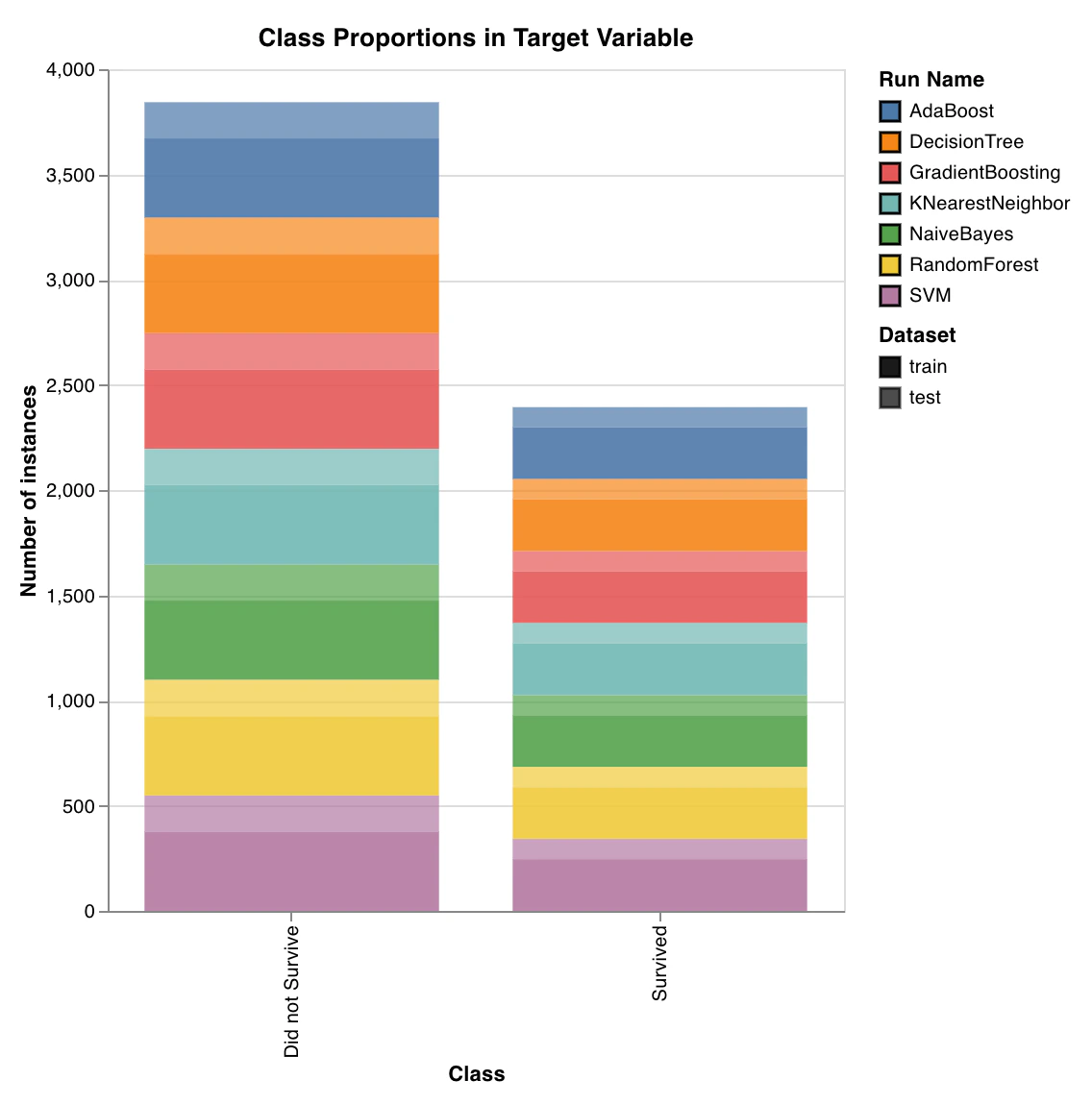
wandb.sklearn.plot_class_proportions(y_train, y_test, ['dog', 'cat', 'owl'])
- y_train (arr): トレーニングセットのラベル。
- y_test (arr): テストセットのラベル。
- labels (list): ターゲット変数 (y) のラベル名。
適合率-再現率曲線
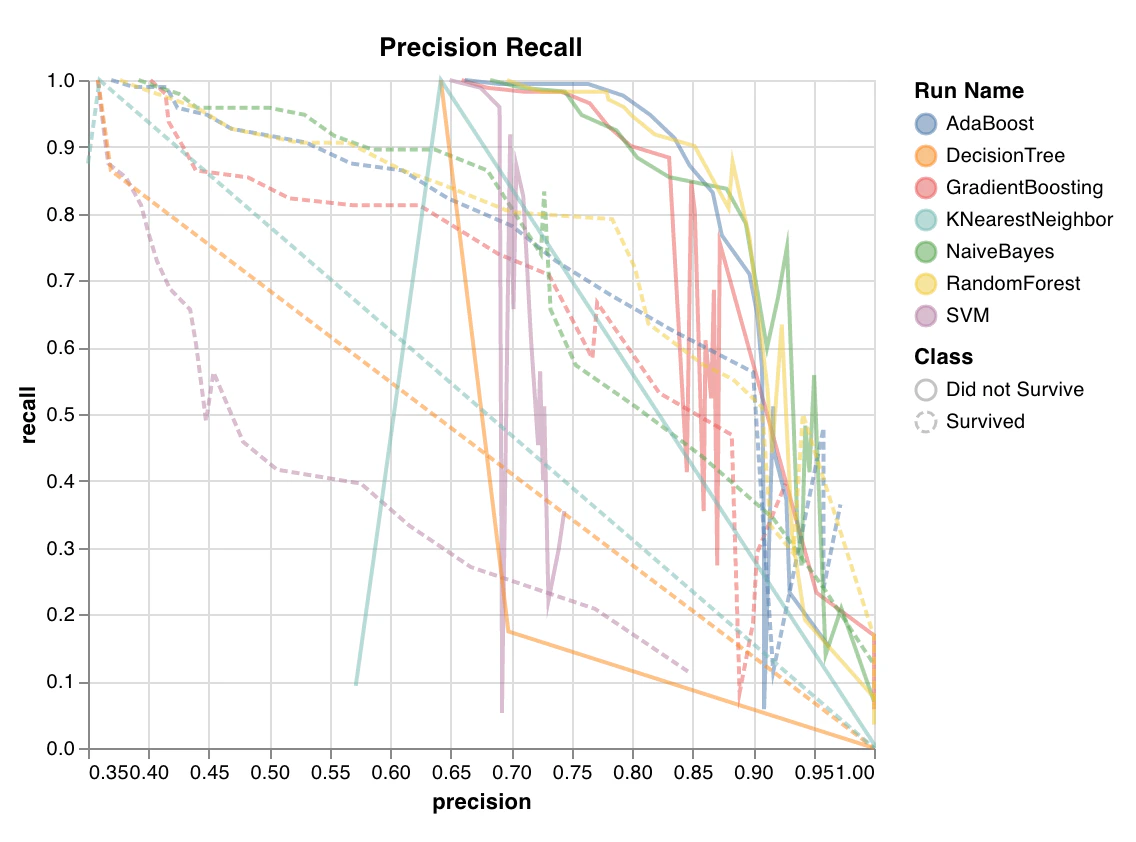
wandb.sklearn.plot_precision_recall(y_true, y_probas, labels)
- y_true (arr): テストセットのラベル。
- y_probas (arr): テストセットの予測確率。
- labels (list): ターゲット変数 (y) のラベル名。
特徴量重要度
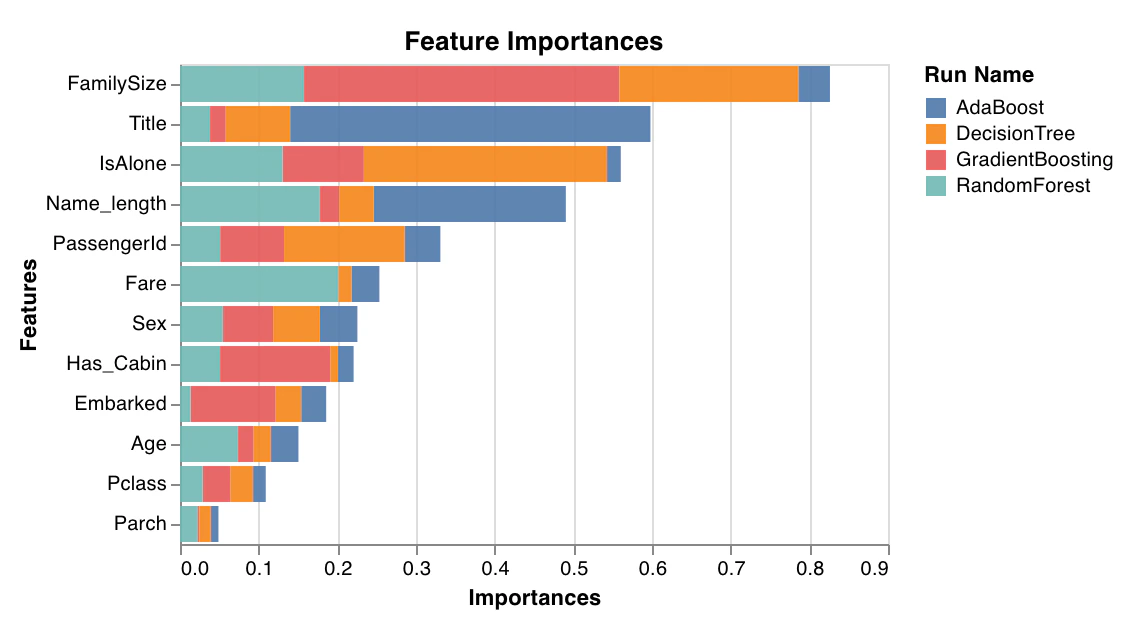
feature_importances_ 属性を持つ分類器 (決定木系モデルなど) でのみ動作します。
wandb.sklearn.plot_feature_importances(model, ['width', 'height, 'length'])
- model (clf): 学習済みの分類器を受け取ります。
- feature_names (list): 特徴量の名前です。特徴量のインデックスを対応する名前に置き換えることで、プロットが読みやすくなります。
キャリブレーション曲線
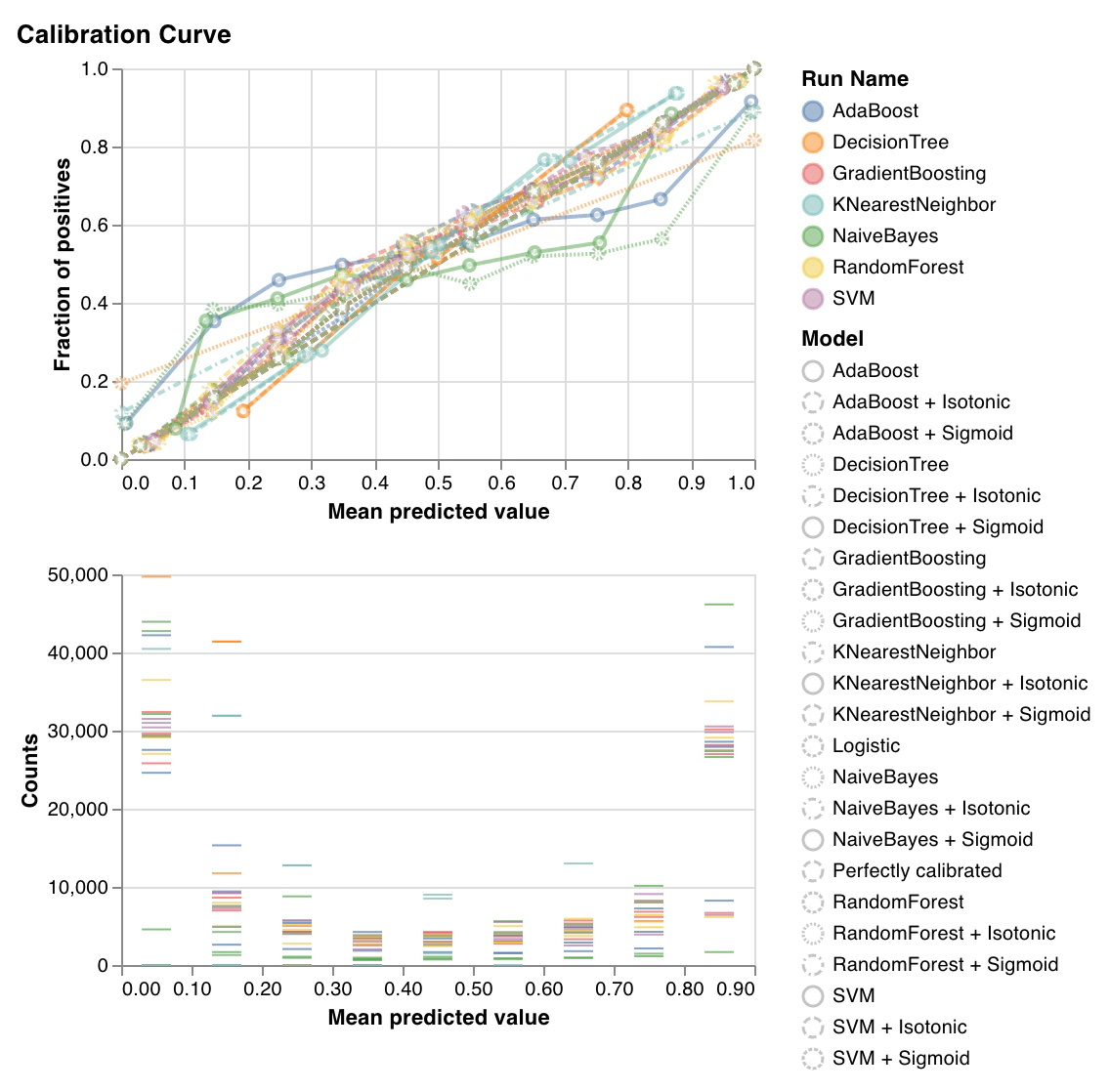
wandb.sklearn.plot_calibration_curve(clf, X, y, 'RandomForestClassifier')
- model (clf): 学習済みの分類器を受け取ります。
- X (arr): トレーニングセットの特徴量。
- y (arr): トレーニングセットのラベル。
- model_name (str): モデル名。デフォルトは ‘Classifier’
混同行列
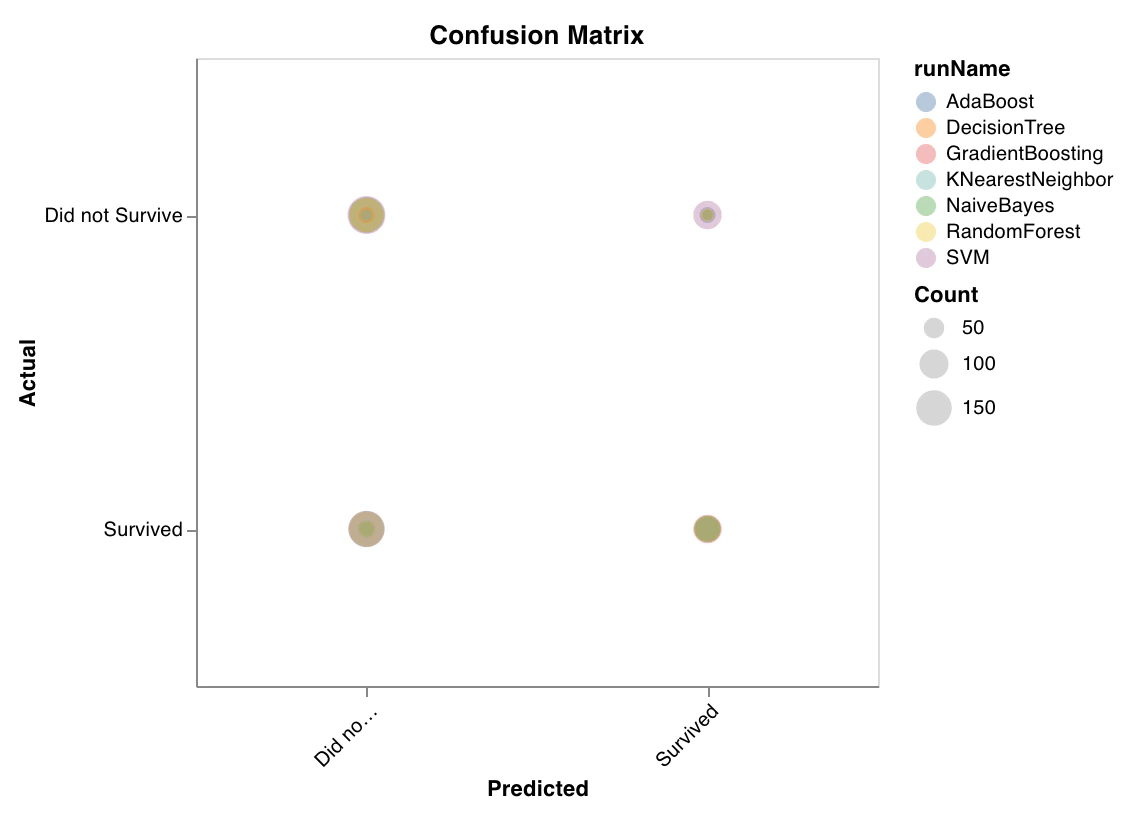
wandb.sklearn.plot_confusion_matrix(y_true, y_pred, labels)
- y_true (arr): テストセットのラベル。
- y_pred (arr): テストセットの予測ラベル。
- labels (list): ターゲット変数 (y) のラベル名。
要約メトリクス
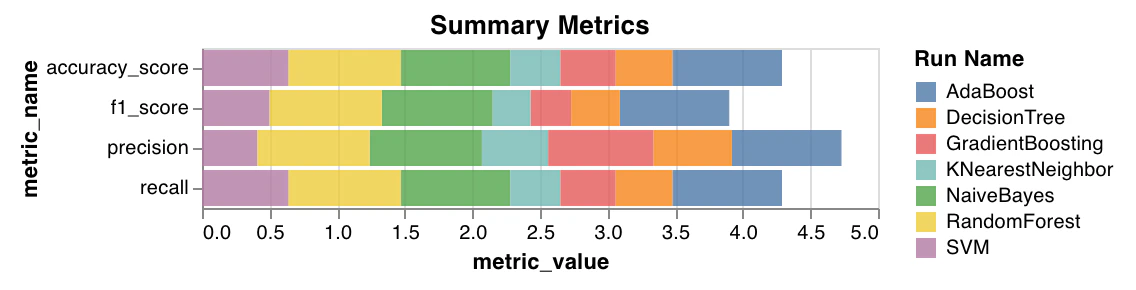
- 分類の要約メトリクスとして、
mse、mae、r2スコアなどを計算します。 - 回帰の要約メトリクスとして、
f1、accuracy、precision、recall などを計算します。
wandb.sklearn.plot_summary_metrics(model, X_train, y_train, X_test, y_test)
- model (clf or reg): 学習済みの回帰モデル または 分類器 を受け取ります。
- X (arr): トレーニングセットの特徴量。
- y (arr): トレーニングセットのラベル。
- X_test (arr): テストセットの特徴量。
- y_test (arr): テストセットのラベル。
エルボープロット
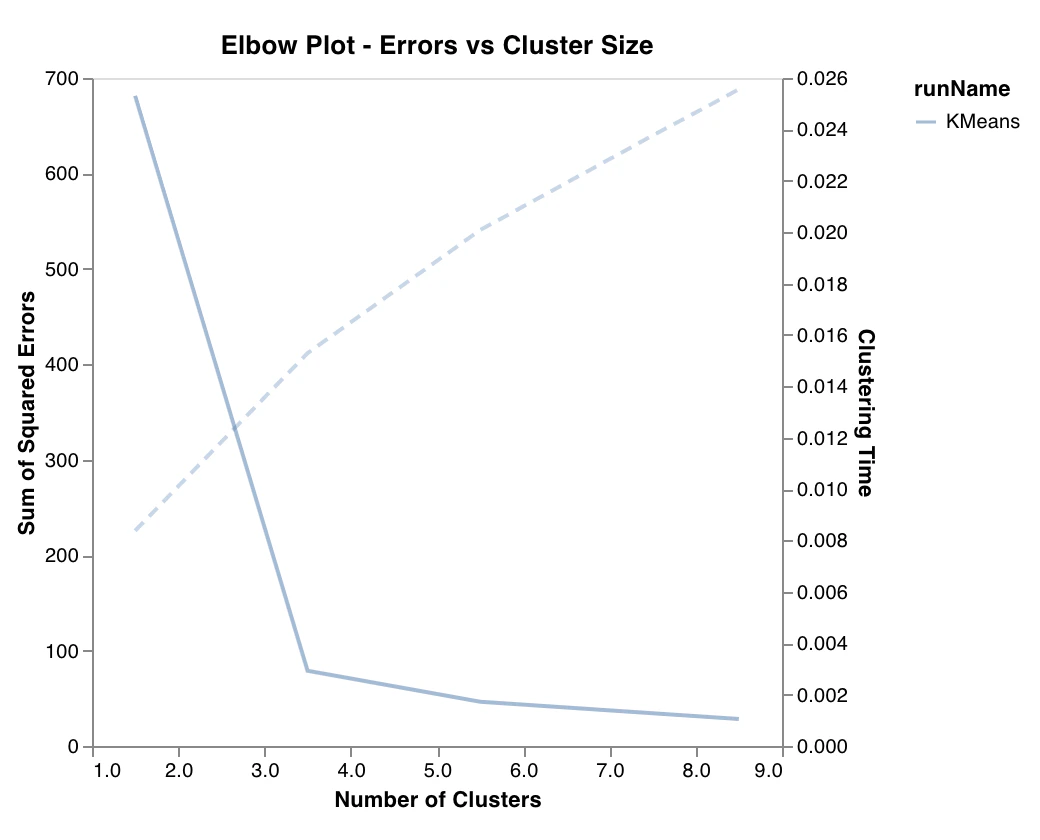
wandb.sklearn.plot_elbow_curve(model, X_train)
- model (clusterer): 学習済みのクラスタラーを受け取ります。
- X (arr): トレーニングセットの特徴量。
シルエットプロット
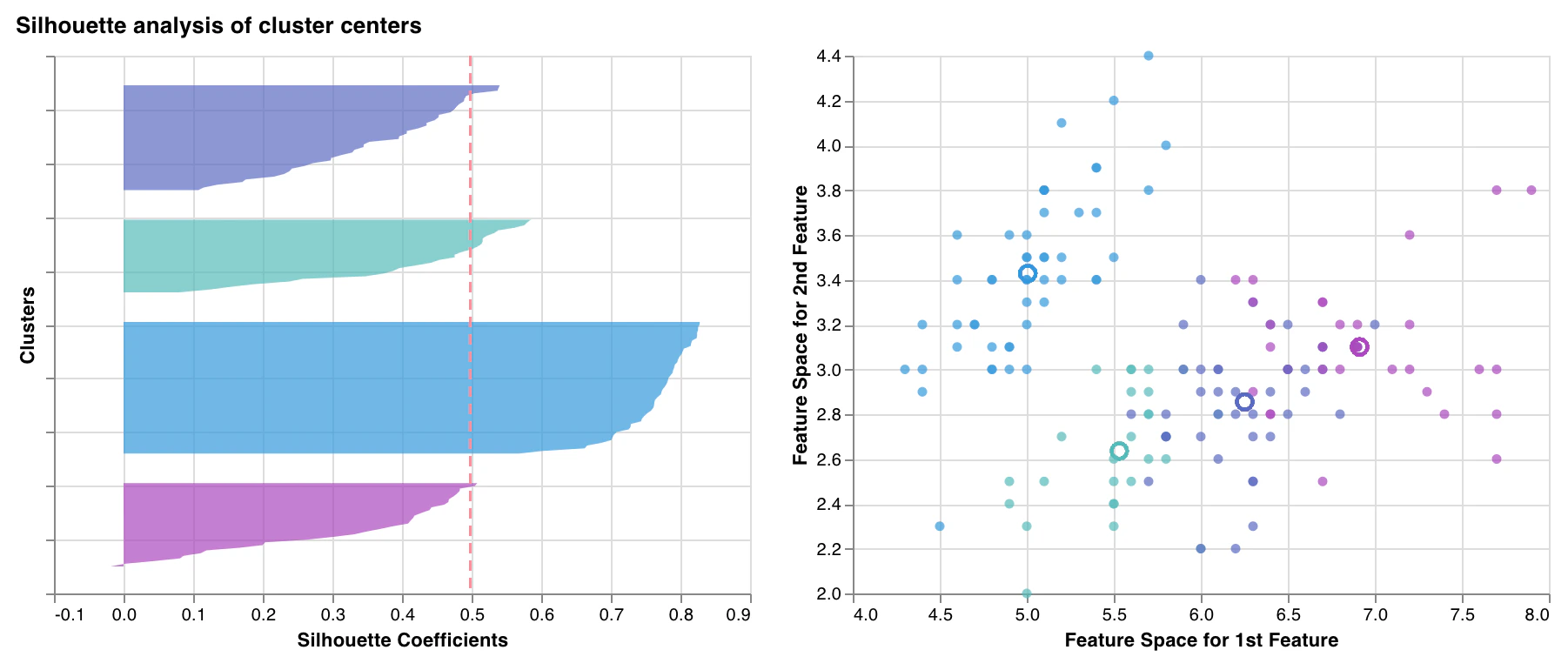
wandb.sklearn.plot_silhouette(model, X_train, ['spam', 'not spam'])
- model (clusterer): 学習済みのクラスタラーを受け取ります。
- X (arr): トレーニングセットの特徴量。
- cluster_labels (list): クラスターラベルの名前。クラスターのインデックスを対応する名前に置き換えることで、プロットが読みやすくなります。
外れ値候補プロット
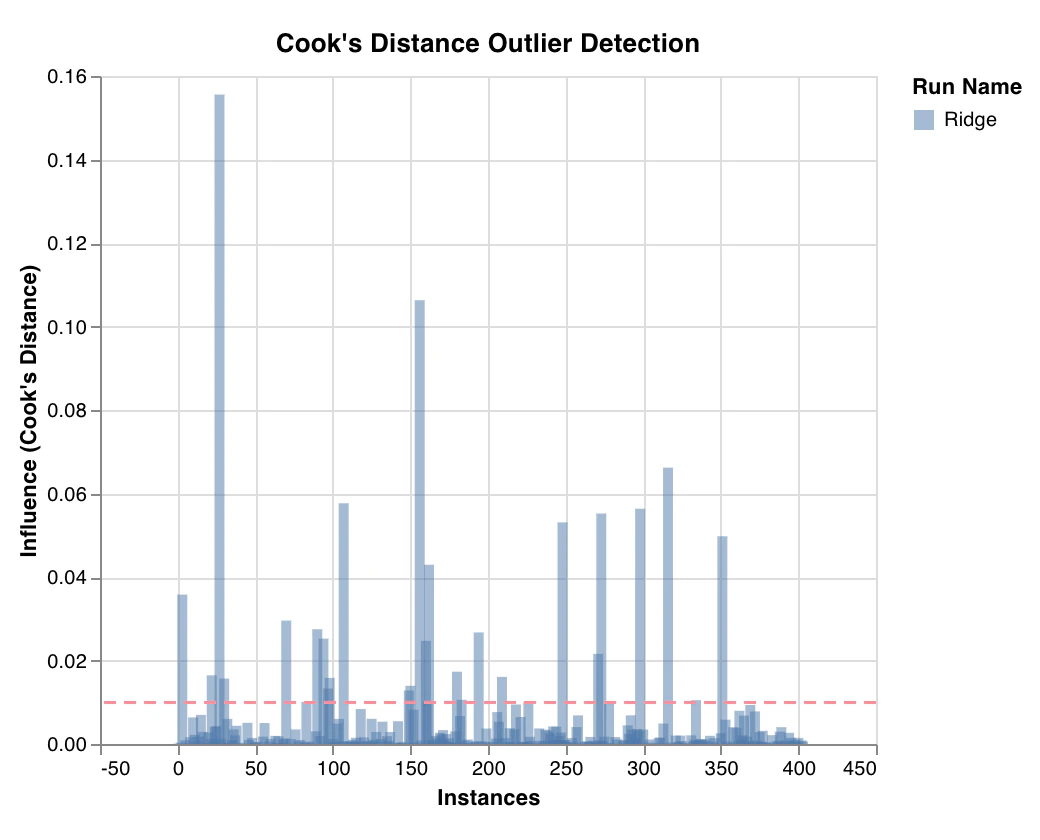
wandb.sklearn.plot_outlier_candidates(model, X, y)
- model (regressor): 学習済みの回帰モデルを受け取ります。
- X (arr): トレーニングセットの特徴量。
- y (arr): トレーニングセットのラベル。
残差プロット
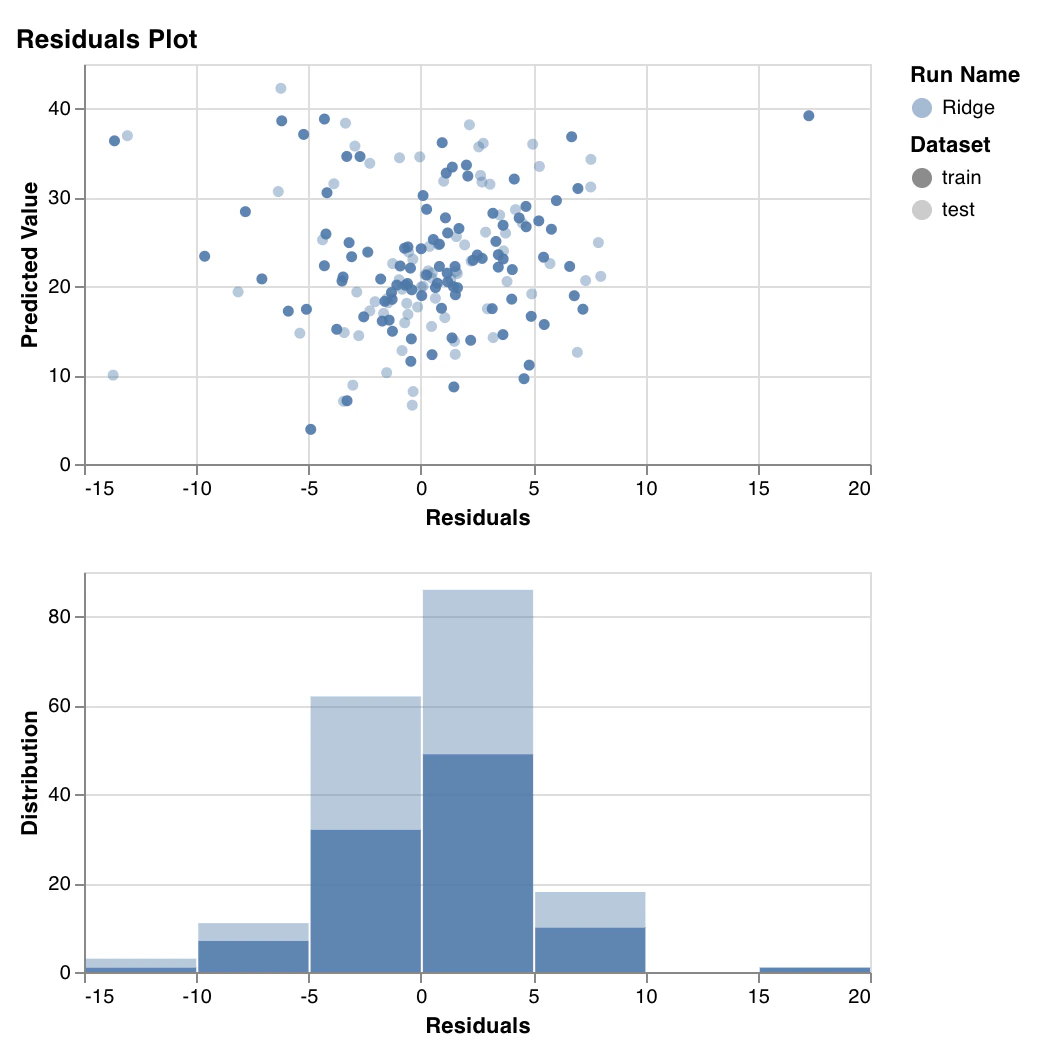
wandb.sklearn.plot_residuals(model, X, y)
- model (regressor): 学習済みの分類器を受け取ります。
- X (arr): トレーニングセットの特徴量。
- y (arr): トレーニングセットのラベル。 ご不明な点があれば、Slackコミュニティ でお気軽にご質問ください。
例
- Colabで実行: すぐに始められるシンプルなノートブックです。