前提条件をインストールする
autotrain-advanced と wandb をインストールします。
- コマンドライン
- ノートブック
pass@1 で SoTA の結果を達成します。
データセットを準備する
-
トレーニングファイルには、トレーニングで使用する
text列が含まれている必要があります。最適な結果を得るには、text列のデータを### Human: Question?### Assistant: Answer.形式に従わせる必要があります。優れた例として、timdettmers/openassistant-guanacoを参照してください。 ただし、MetaMathQA dataset にはquery、response、typeの各列が含まれています。まず、このデータセットを前処理します。type列を削除し、query列とresponse列の内容を結合して、### Human: Query?### Assistant: Response.形式の新しいtext列を作成してください。トレーニングには、こうして作成したデータセットrishiraj/guanaco-style-metamathを使用します。
autotrain を使用してトレーニングする
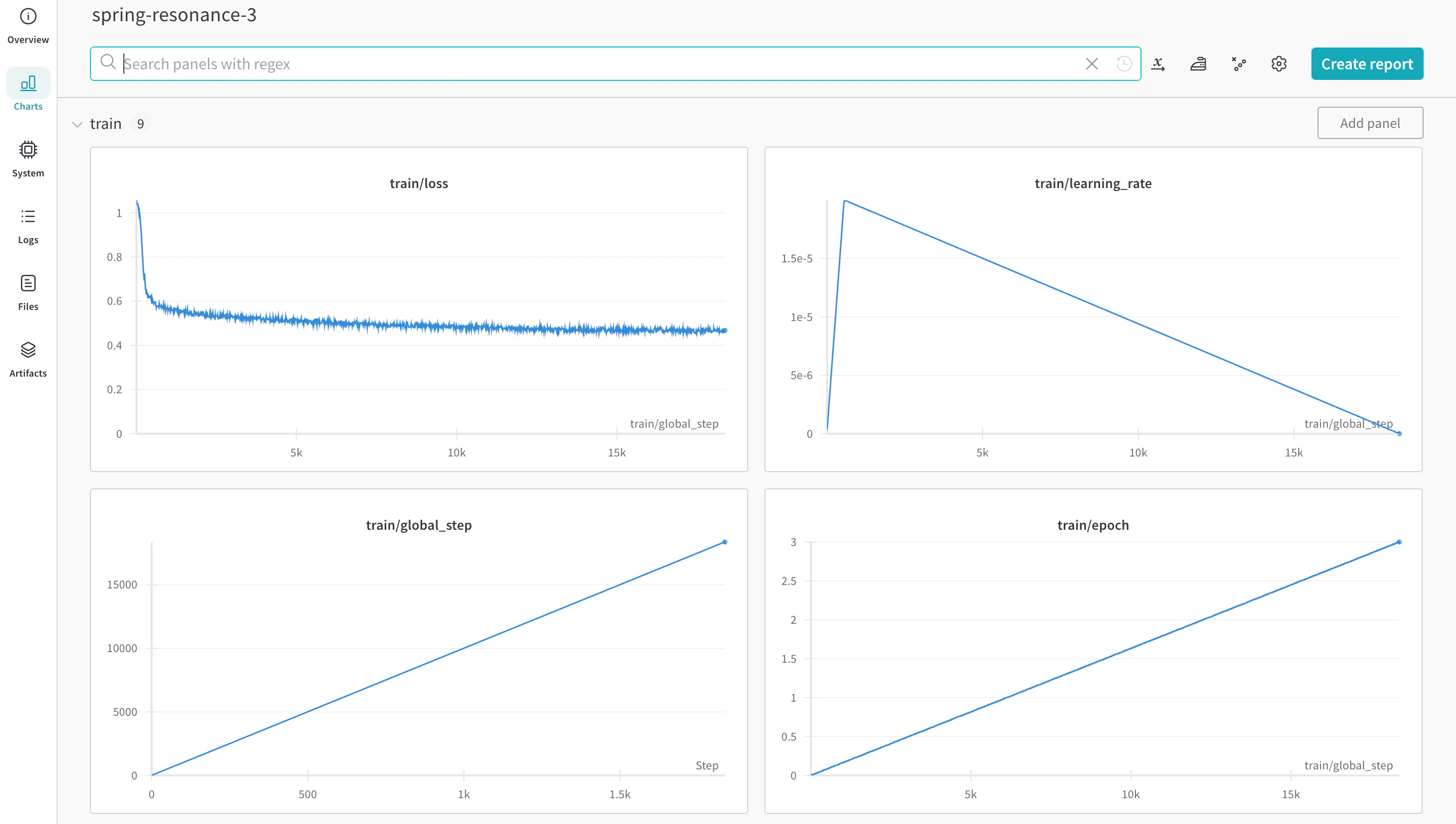
autotrain advanced を使用してトレーニングを開始できます。--log 引数を使用するか、--log wandb を使用して結果を W&B Run にログできます。
- コマンドライン
- ノートブック