Évaluer des modèles avec Weave
Fonctionnalités clés pour l’évaluation des modèles
- Évaluateurs et juges : Métriques d’évaluation prédéfinies et personnalisées pour l’exactitude, la pertinence, la cohérence, etc.
- Jeux de données d’évaluation : Ensembles de test structurés avec des valeurs de référence pour une évaluation systématique
- Gestion des versions des modèles : Suivez et comparez différentes versions de vos modèles
- Tracing détaillé : Déboguez le comportement du modèle à l’aide de traces d’entrée/sortie complètes
- Suivi des coûts : Surveillez les coûts d’API et l’utilisation des tokens sur l’ensemble des évaluations
Premiers pas : évaluer un modèle à partir du W&B Registry
Intégrer les évaluations Weave à W&B Models
- Charger des modèles depuis le registre : téléchargez des modèles affinés stockés dans le registre de W&B Models
- Créer des pipelines d’évaluation : créez des évaluations complètes avec des évaluateurs personnalisés
- Consigner les résultats dans W&B : associez les métriques d’évaluation aux runs de vos modèles
- Versionner les modèles évalués : enregistrez les modèles améliorés dans le registre
Fonctionnalités avancées de Weave
Évaluateurs et juges personnalisés
Évaluations par lot
Étapes suivantes
Évaluer des modèles avec W&B Tables
- Comparer les prédictions des modèles : affichez côte à côte les performances de différents modèles sur le même jeu de test
- Suivre l’évolution des prédictions : observez comment les prédictions changent au fil des époques d’entraînement ou des versions du modèle
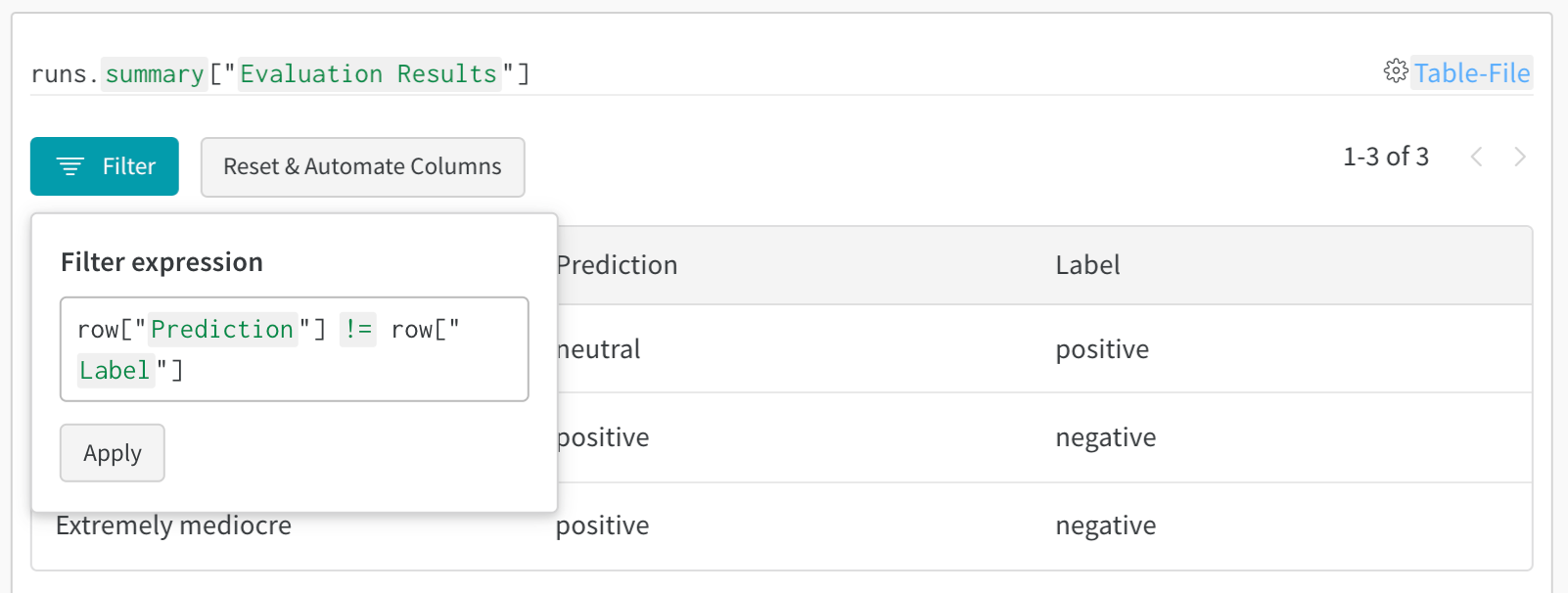
- Analyser les erreurs : filtrez et lancez des requêtes pour trouver les exemples fréquemment mal classés et les schémas d’erreur
- Visualiser des médias enrichis : affichez des images, de l’Audio, du texte et d’autres types de médias à côté des prédictions et des métriques
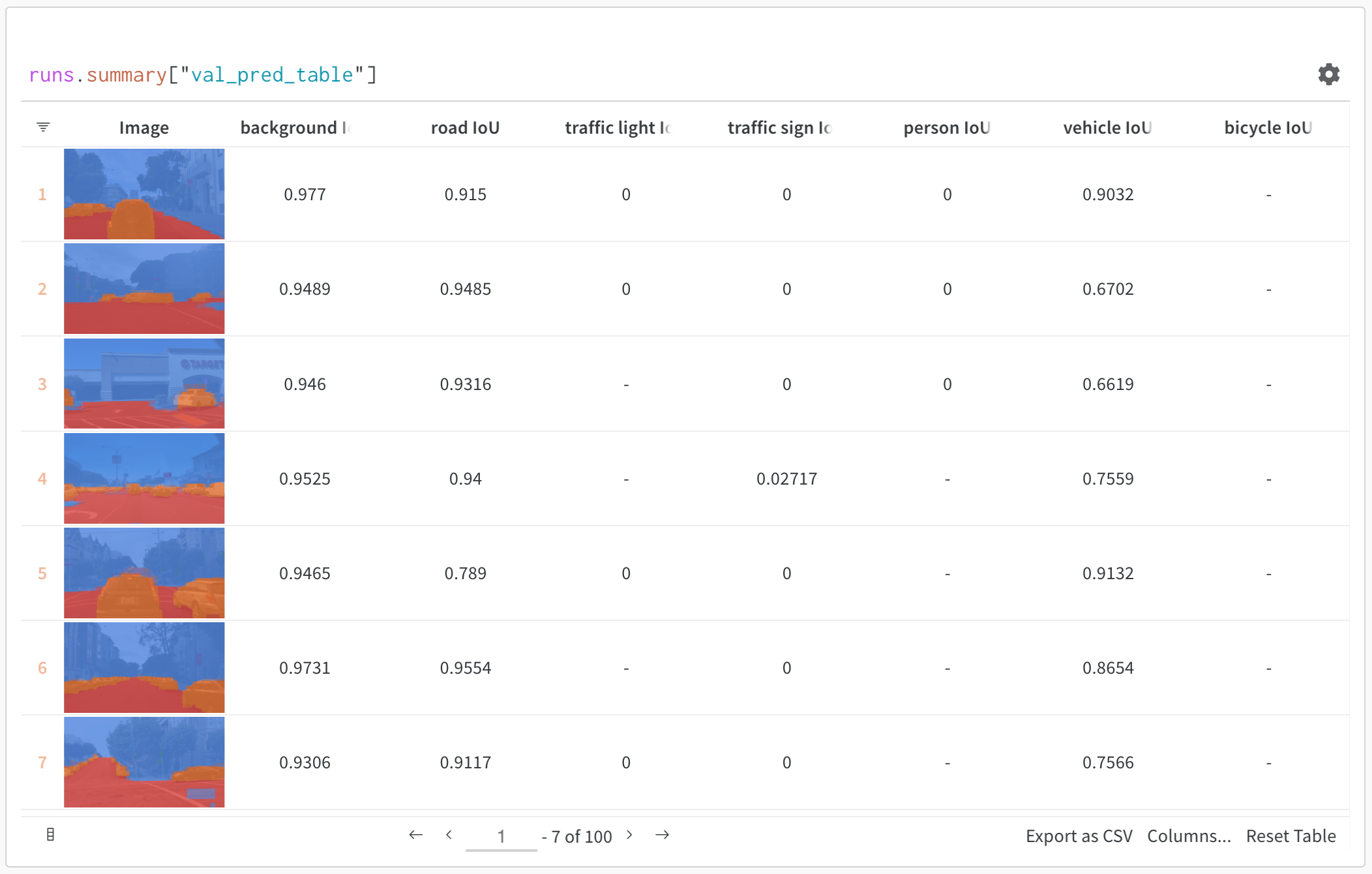
Exemple de base : journaliser les résultats d’évaluation
Flux de travail avancés avec les tableaux
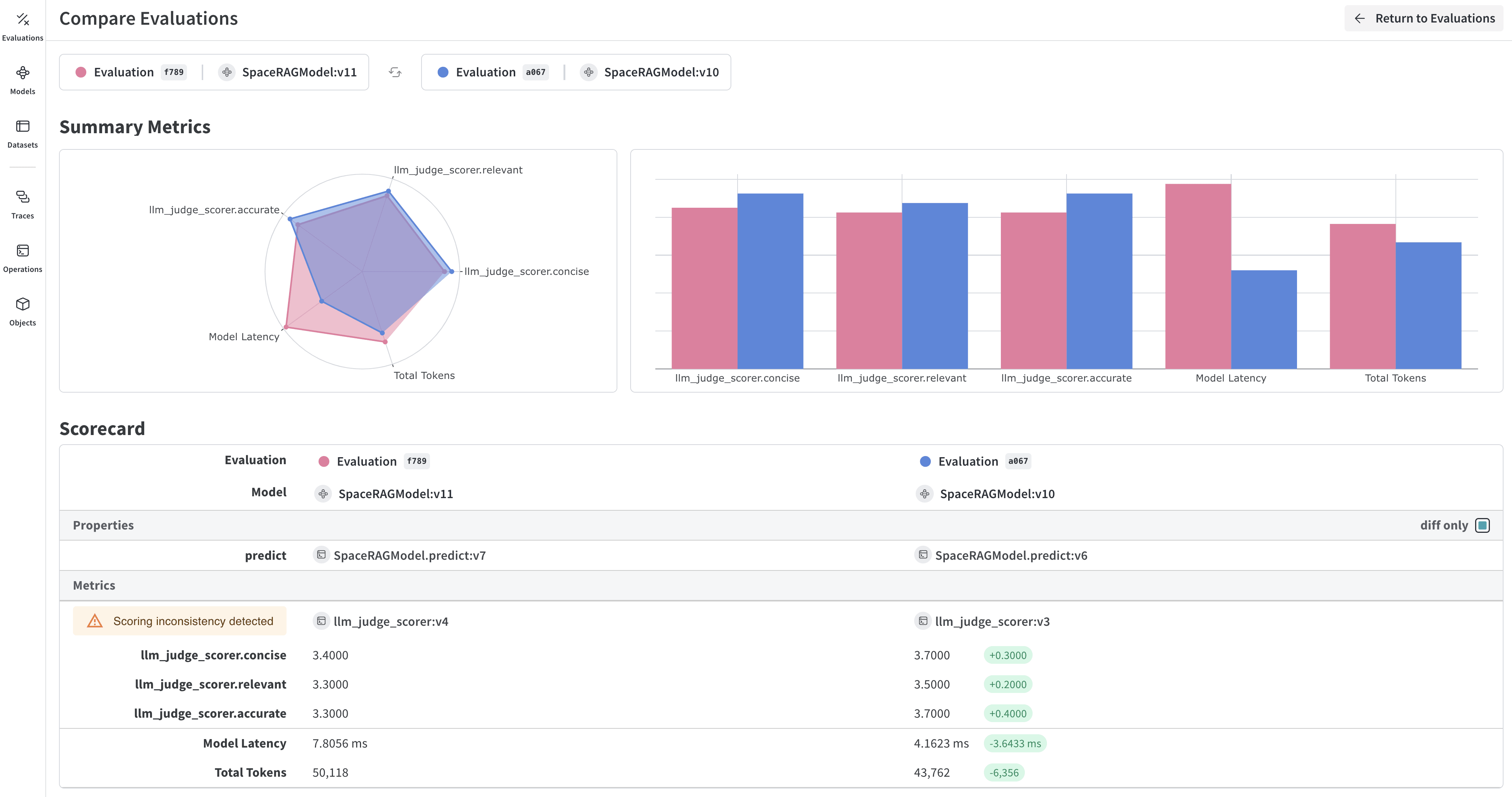
Comparer plusieurs modèles
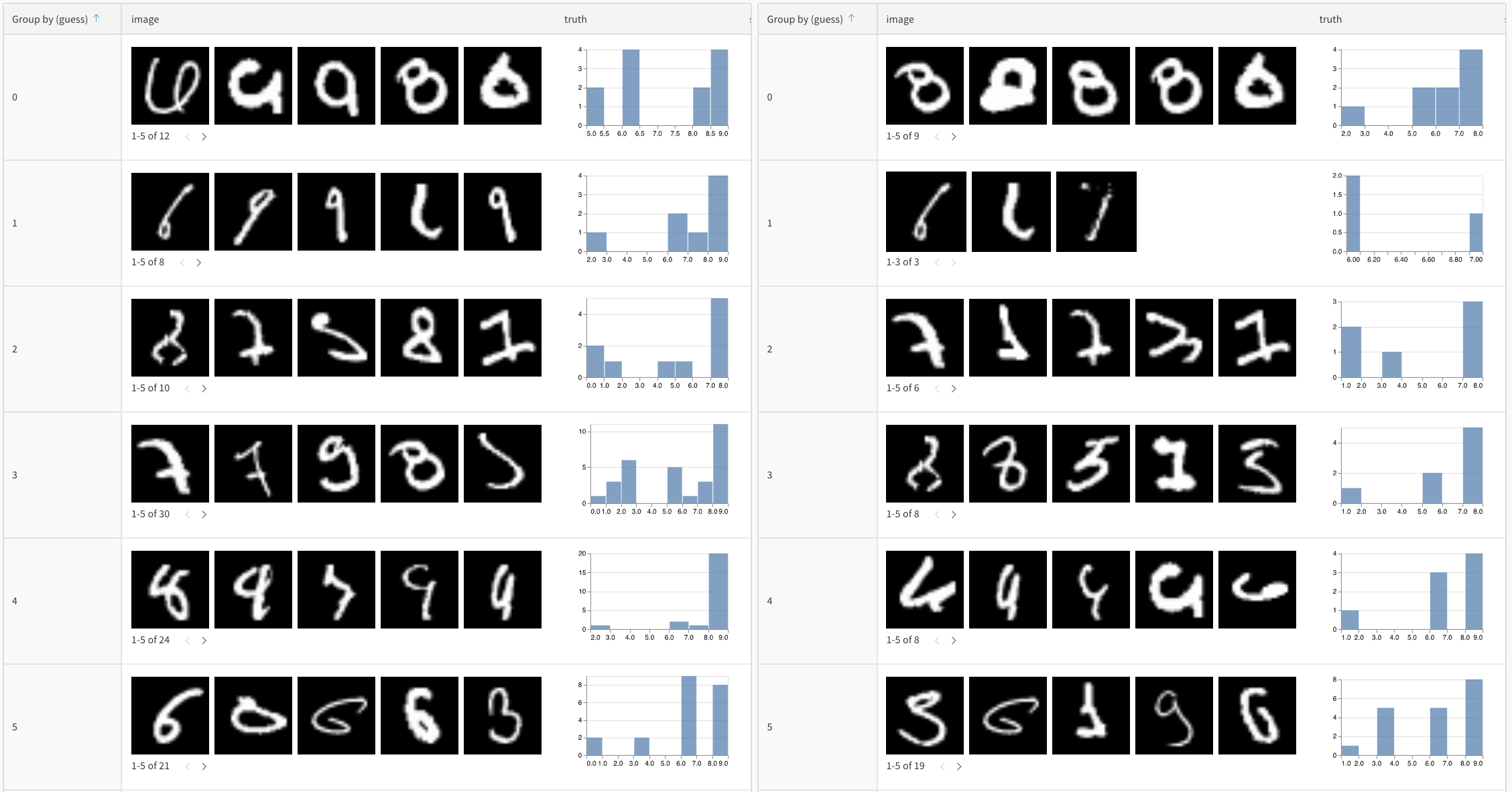
Suivre les prédictions au fil du temps
Analyse interactive dans l’interface W&B
- Filtrer les résultats : cliquez sur les en-têtes de colonne pour filtrer selon la précision des prédictions, les seuils de confiance ou des classes spécifiques
- Comparer des tables : sélectionnez plusieurs versions de table pour afficher des comparaisons côte à côte
- Interroger les données : utilisez la barre de requête pour trouver des motifs précis (par exemple,
"correct" = false AND "confidence" > 0.8) - Grouper et agréger : regroupez par classe prédite pour voir les métriques de précision par classe