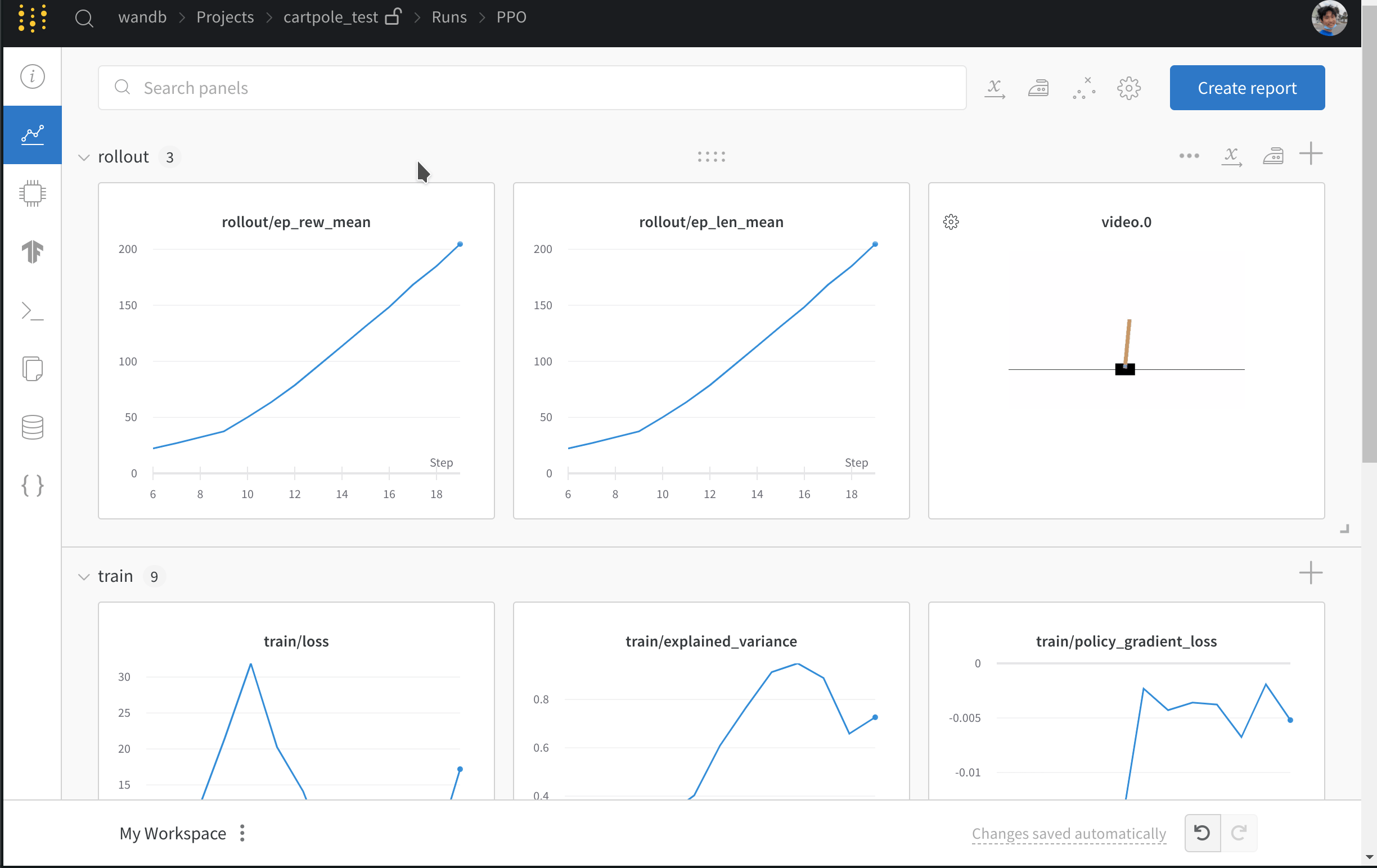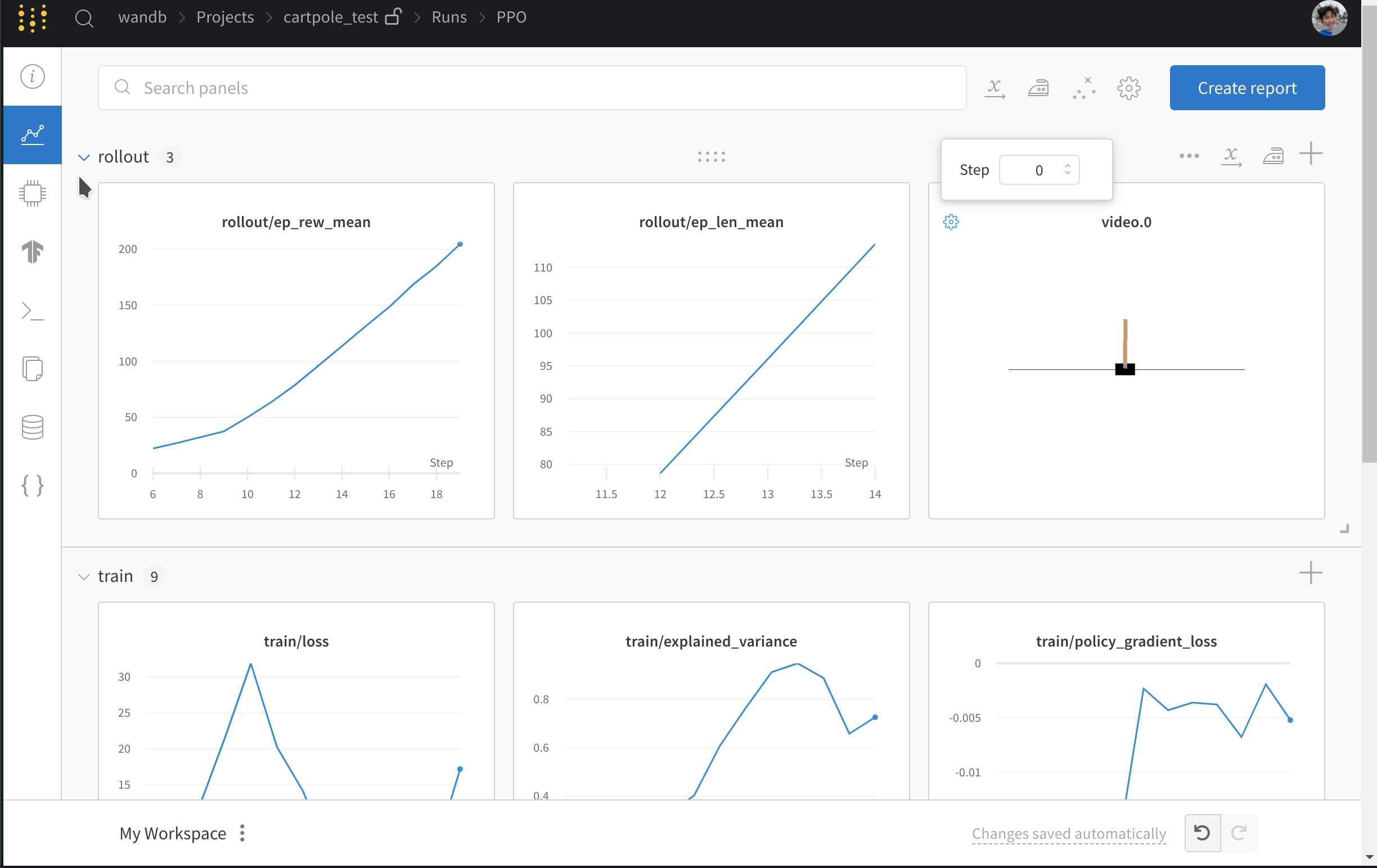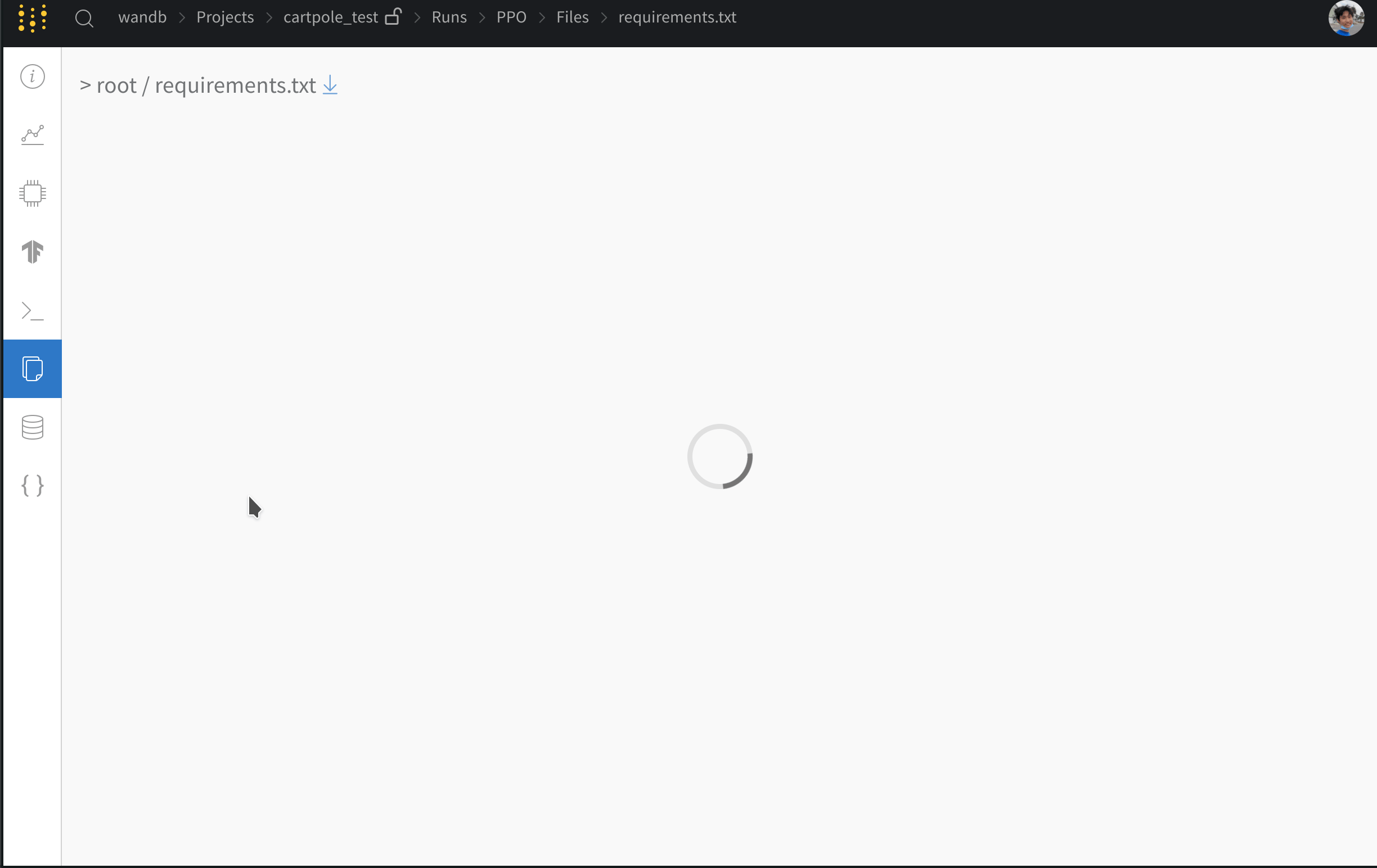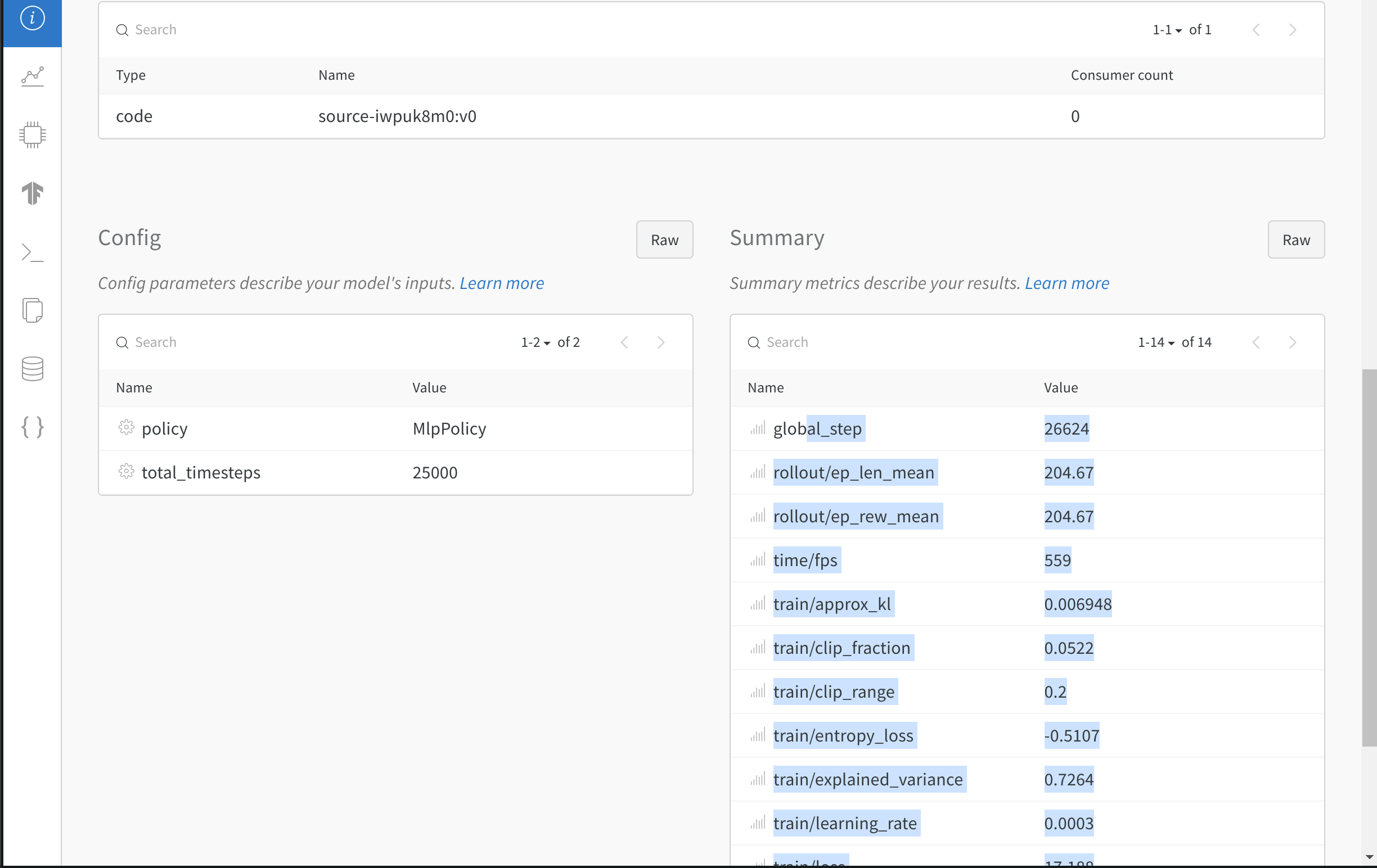
- Enregistre des métriques telles que les pertes et les retours d’épisode.
- Téléverse des vidéos d’agents en train de jouer.
- Enregistre le modèle entraîné.
- Journalise les hyperparamètres du modèle.
- Journalise les histogrammes de gradients du modèle.
Journalisez vos expériences SB3
Arguments de WandbCallback
| Argument | Utilisation |
|---|---|
verbose | Niveau de verbosité de la sortie de sb3 |
model_save_path | Chemin vers le dossier où le modèle sera enregistré. La valeur par défaut est None, donc le modèle n’est pas enregistré |
model_save_freq | Fréquence d’enregistrement du modèle |
gradient_save_freq | Fréquence d’enregistrement des gradients. La valeur par défaut est 0, donc les gradients ne sont pas enregistrés |