Bien démarrer
Inscrivez-vous et créez une clé API
Pour une méthode plus directe, créez une clé API en accédant directement aux Paramètres utilisateur. Copiez immédiatement la clé API nouvellement créée et conservez-la dans un endroit sûr, par exemple dans un gestionnaire de mots de passe.
- Cliquez sur l’icône de votre profil utilisateur dans le coin supérieur droit.
- Sélectionnez Paramètres utilisateur, puis faites défiler jusqu’à la section API Keys.
Installer la bibliothèque wandb et se connecter
wandb localement et vous connecter :
- Ligne de commande
- Python
- Python notebook
-
Définissez la variable d’environnement
WANDB_API_KEYavec votre clé API. -
Installez la bibliothèque
wandbet connectez-vous.
Consigner des métriques
Créer des graphiques
Étape 1 : Importez wandb et initialisez un nouveau run
Étape 2 : Visualiser les graphiques
Graphiques individuels
Tous les graphiques
plot_classifier, qui génèrent plusieurs graphiques pertinents :
Graphiques Matplotlib existants
plotly.
Graphiques pris en charge
Courbe d’apprentissage
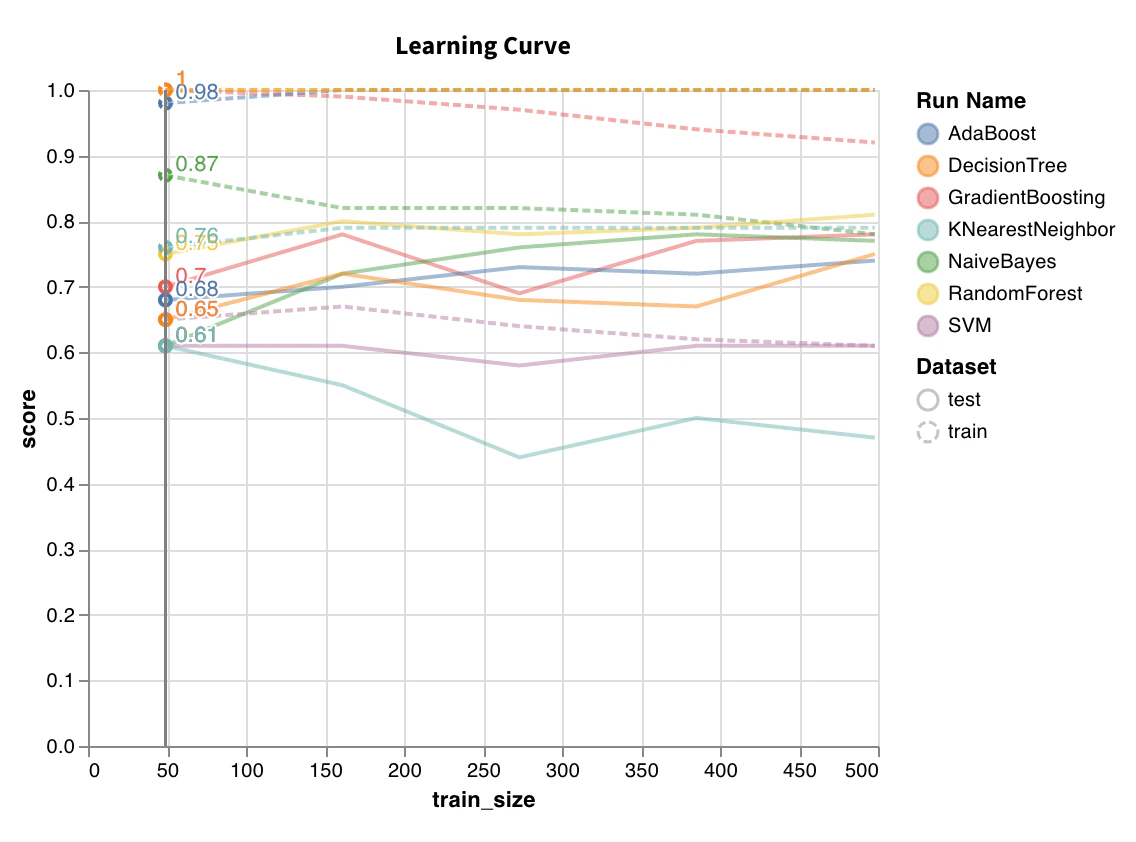
wandb.sklearn.plot_learning_curve(model, X, y)
- model (clf or reg): Prend en entrée un régressseur ou un classifieur ajusté.
- X (arr): Fonctionnalités du jeu de données.
- y (arr): Étiquettes du jeu de données.
ROC
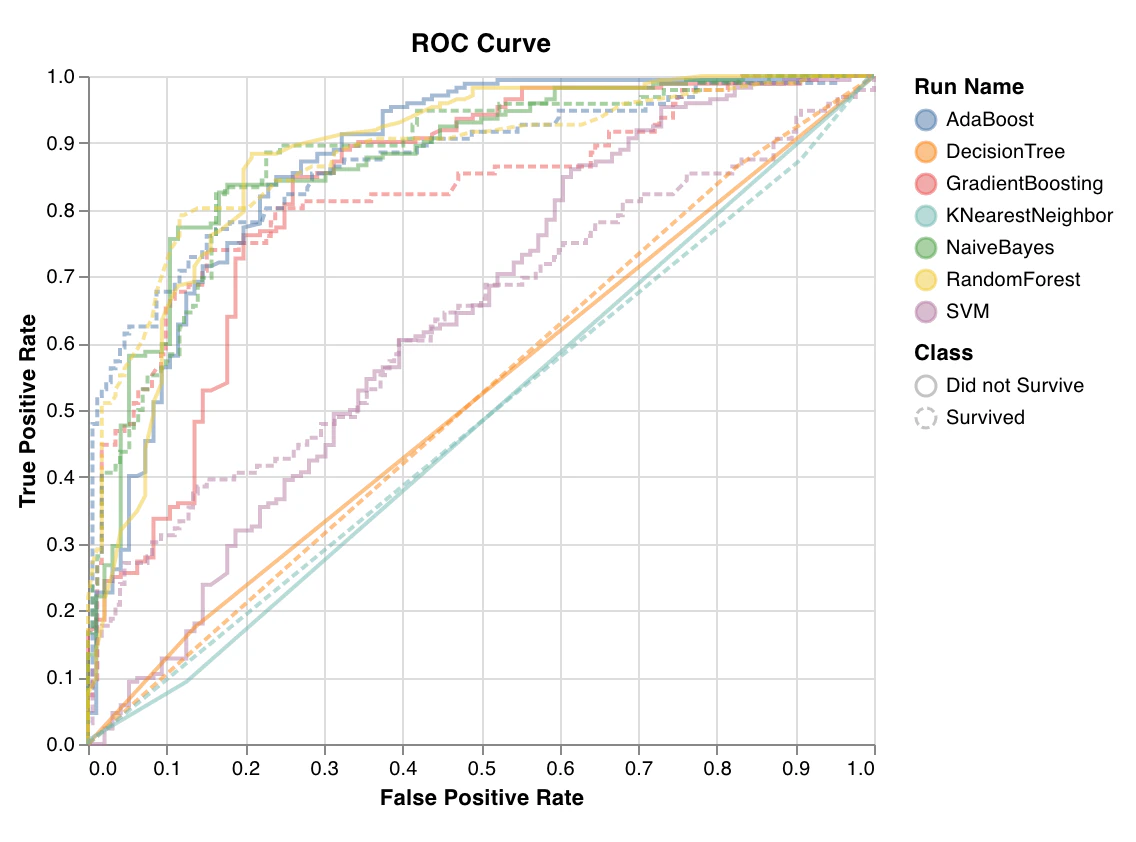
wandb.sklearn.plot_roc(y_true, y_probas, labels)
- y_true (arr): Étiquettes de l’ensemble de test.
- y_probas (arr): Probabilités prédites pour l’ensemble de test.
- labels (list): Libellés des classes pour la variable cible (y).
Proportions des classes
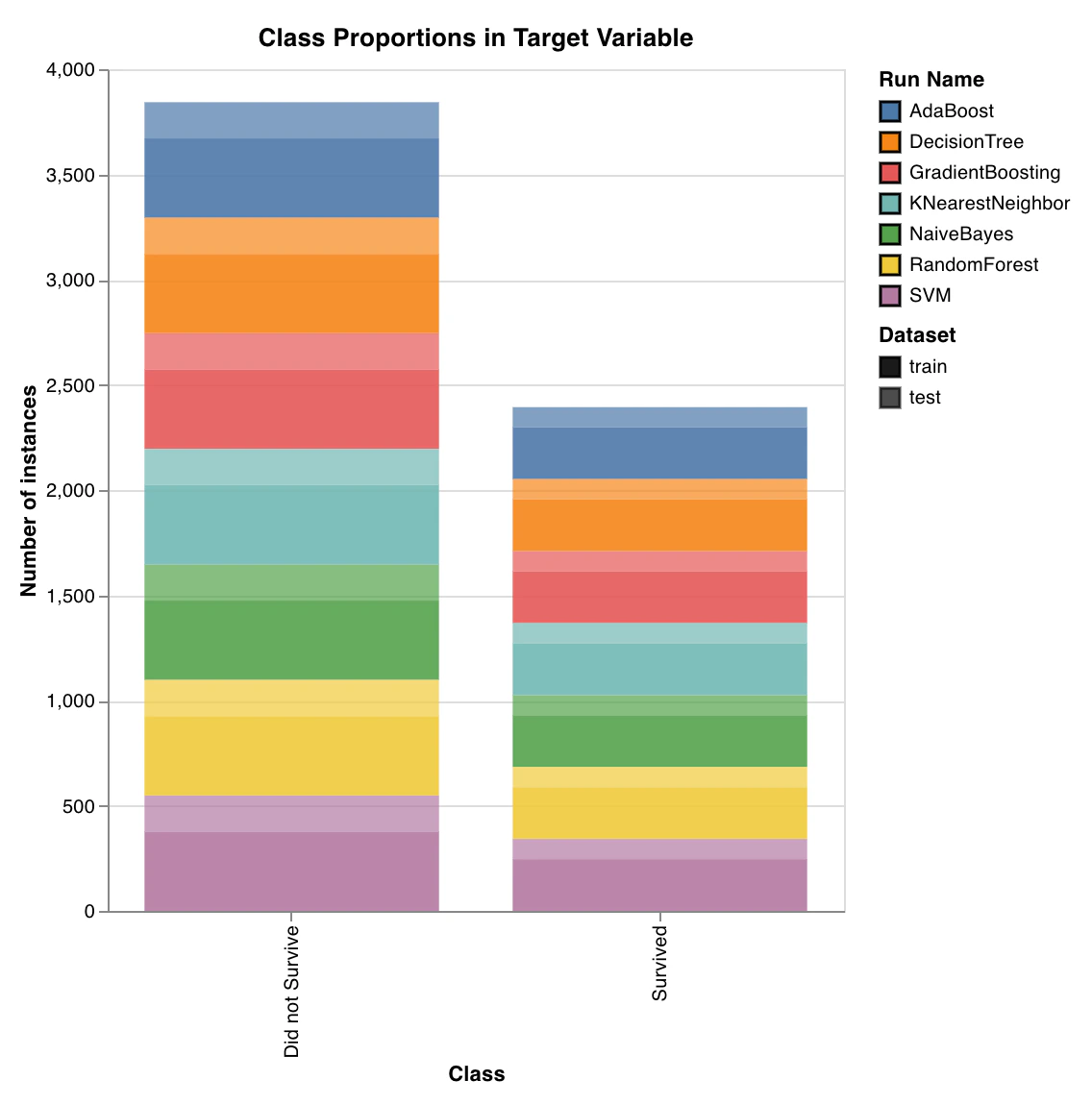
wandb.sklearn.plot_class_proportions(y_train, y_test, ['dog', 'cat', 'owl'])
- y_train (arr): Étiquettes de l’ensemble d’entraînement.
- y_test (arr): Étiquettes de l’ensemble de test.
- labels (list): Étiquettes nommées de la variable cible (y).
Courbe précision-rappel
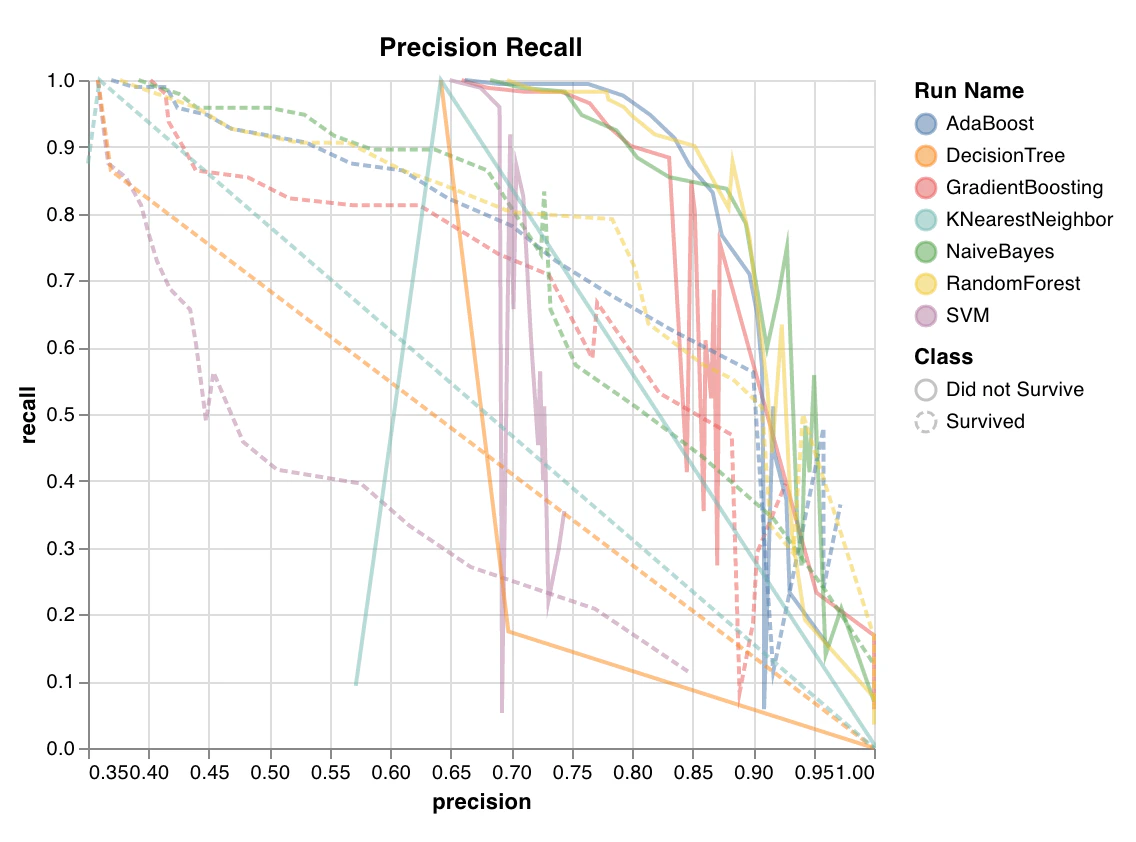
wandb.sklearn.plot_precision_recall(y_true, y_probas, labels)
- y_true (arr): Étiquettes de l’ensemble de test.
- y_probas (arr): Probabilités prédites sur l’ensemble de test.
- labels (list): Noms des étiquettes pour la variable cible (y).
Importance des fonctionnalités
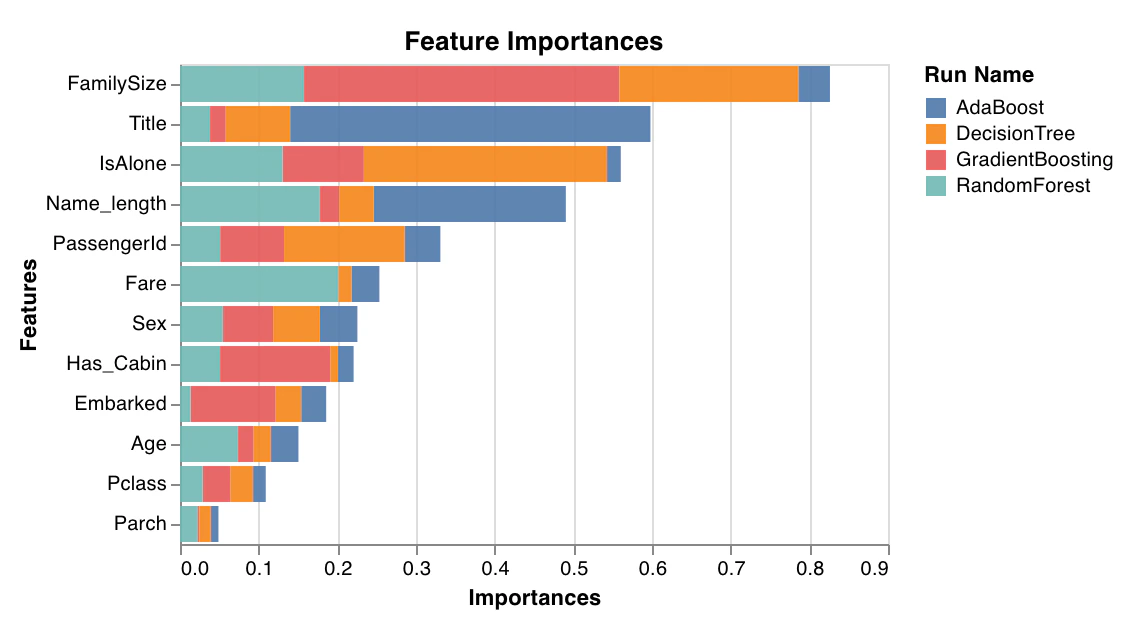
feature_importances_, comme les arbres.
wandb.sklearn.plot_feature_importances(model, ['width', 'height, 'length'])
- model (clf): Prend en entrée un classifieur ajusté.
- feature_names (list): Noms des fonctionnalités. Rend les graphiques plus lisibles en remplaçant les indices des fonctionnalités par les noms correspondants.
Courbe de calibration
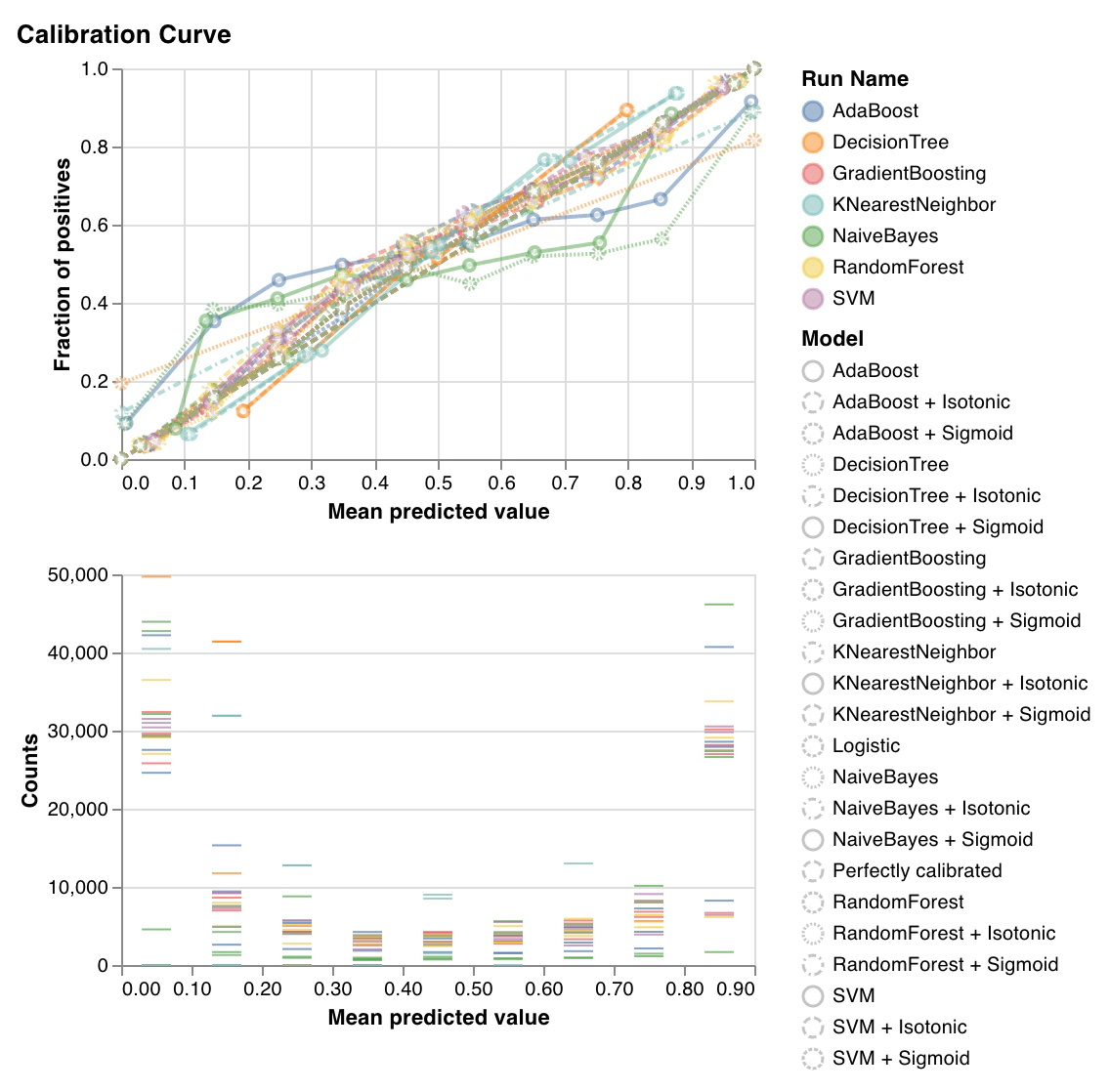
wandb.sklearn.plot_calibration_curve(clf, X, y, 'RandomForestClassifier')
- model (clf) : Prend en entrée un classifieur ajusté.
- X (arr) : Fonctionnalités de l’ensemble d’entraînement.
- y (arr) : Étiquettes de l’ensemble d’entraînement.
- model_name (str) : Nom du modèle. Valeur par défaut : ‘Classifier’
Matrice de confusion
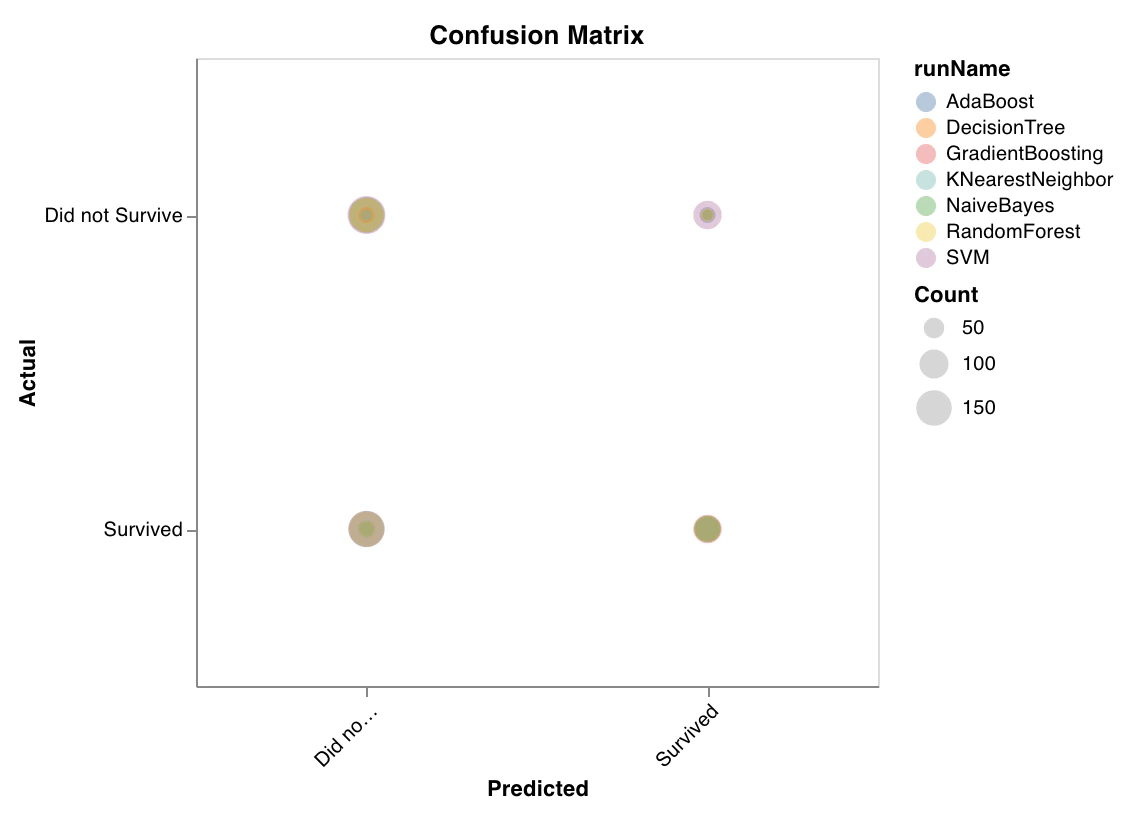
wandb.sklearn.plot_confusion_matrix(y_true, y_pred, labels)
- y_true (arr): Étiquettes de l’ensemble de test.
- y_pred (arr): Étiquettes prédites de l’ensemble de test.
- labels (list): Étiquettes nommées de la variable cible (y).
Métriques de synthèse
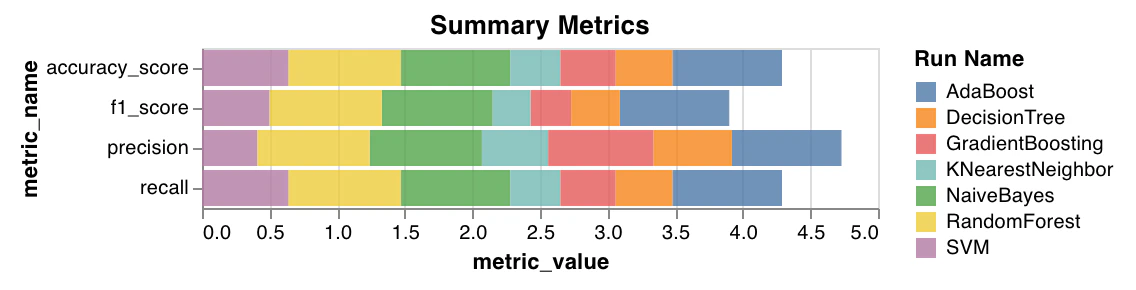
- Calcule des métriques de synthèse pour la classification, comme
mse,maeet le scorer2. - Calcule des métriques de synthèse pour la régression, comme
f1, accuracy, la précision et le rappel.
wandb.sklearn.plot_summary_metrics(model, X_train, y_train, X_test, y_test)
- model (clf or reg): Prend en entrée un régresseur ou un classifieur ajusté.
- X (arr): Fonctionnalités de l’ensemble d’entraînement.
- y (arr): Étiquettes de l’ensemble d’entraînement.
- X_test (arr): Fonctionnalités de l’ensemble de test.
- y_test (arr): Étiquettes de l’ensemble de test.
Graphique en coude
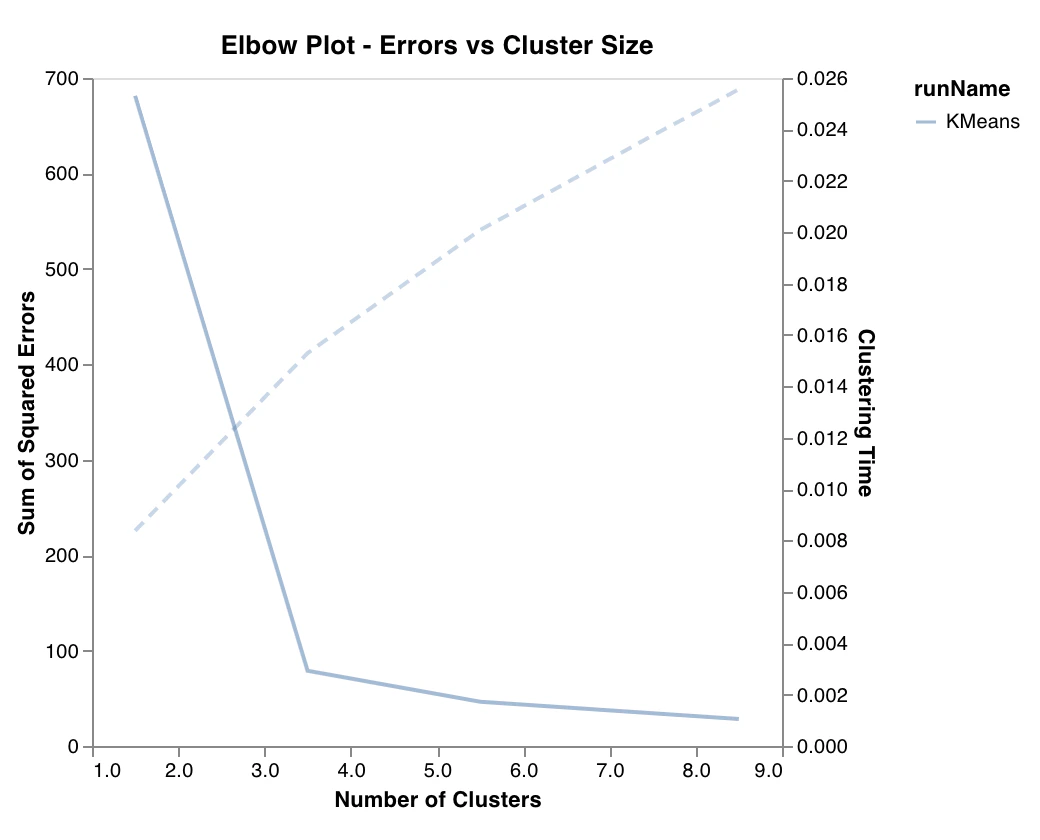
wandb.sklearn.plot_elbow_curve(model, X_train)
- model (clusterer): Accepte un clusterer ajusté.
- X (arr): Fonctionnalités de l’ensemble d’entraînement.
Graphique de silhouette
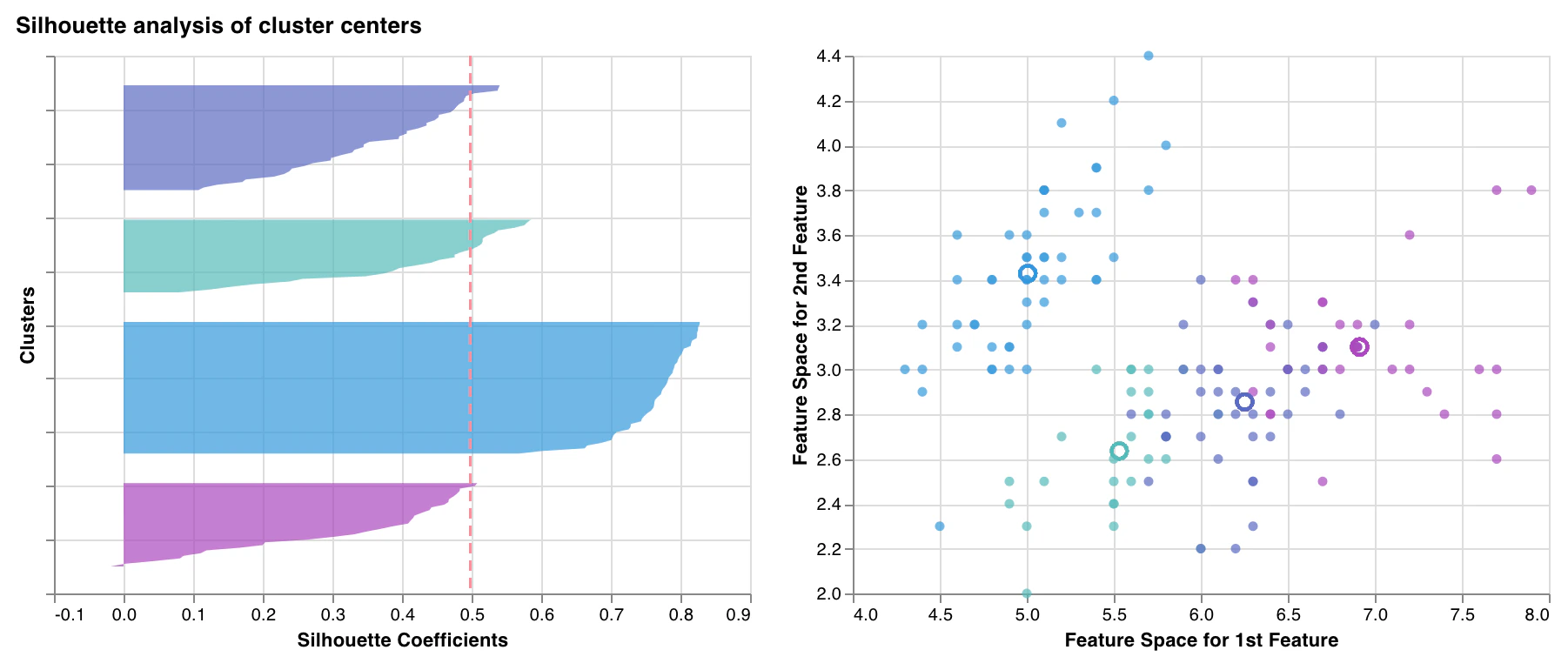
wandb.sklearn.plot_silhouette(model, X_train, ['spam', 'not spam'])
- model (clusterer) : Prend en entrée un algorithme de clustering ajusté.
- X (arr) : Fonctionnalités de l’ensemble d’entraînement.
- cluster_labels (list) : Noms des étiquettes de cluster. Rend les graphiques plus faciles à lire en remplaçant les indices de cluster par les noms correspondants.
Graphique des valeurs aberrantes potentielles
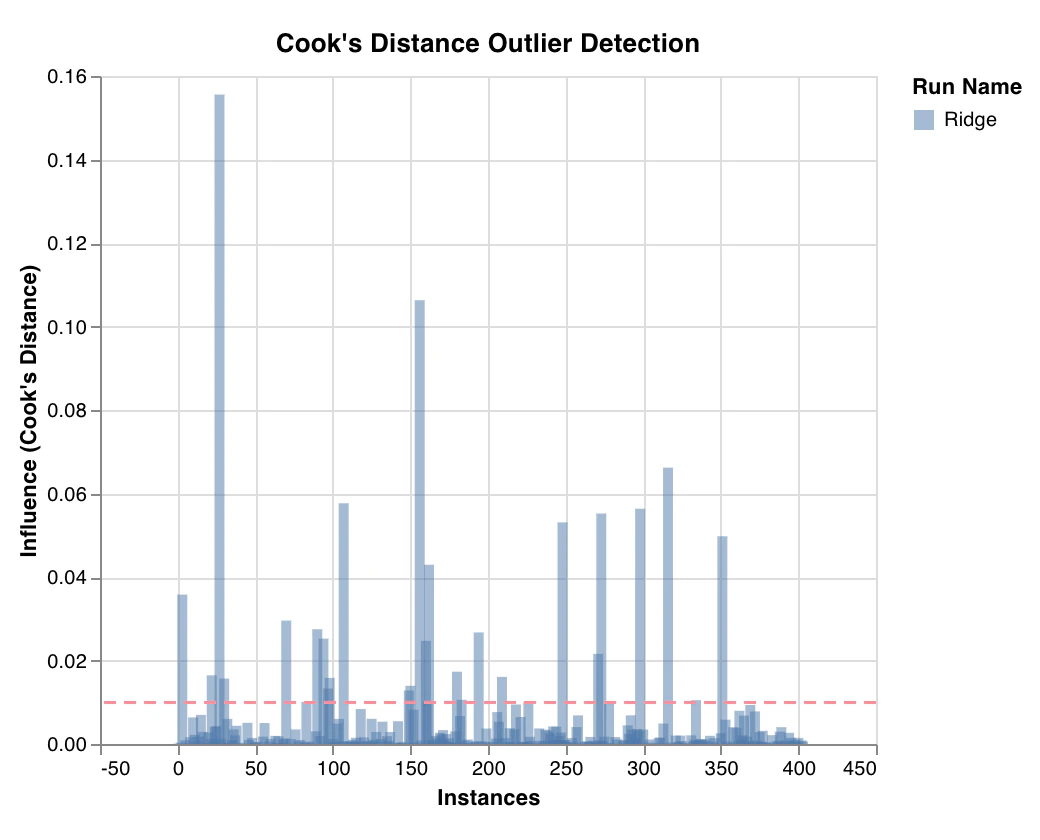
wandb.sklearn.plot_outlier_candidates(model, X, y)
- model (regressor): Accepte un classificateur ajusté.
- X (arr): Fonctionnalités de l’ensemble d’entraînement.
- y (arr): Étiquettes de l’ensemble d’entraînement.
Graphique des résidus
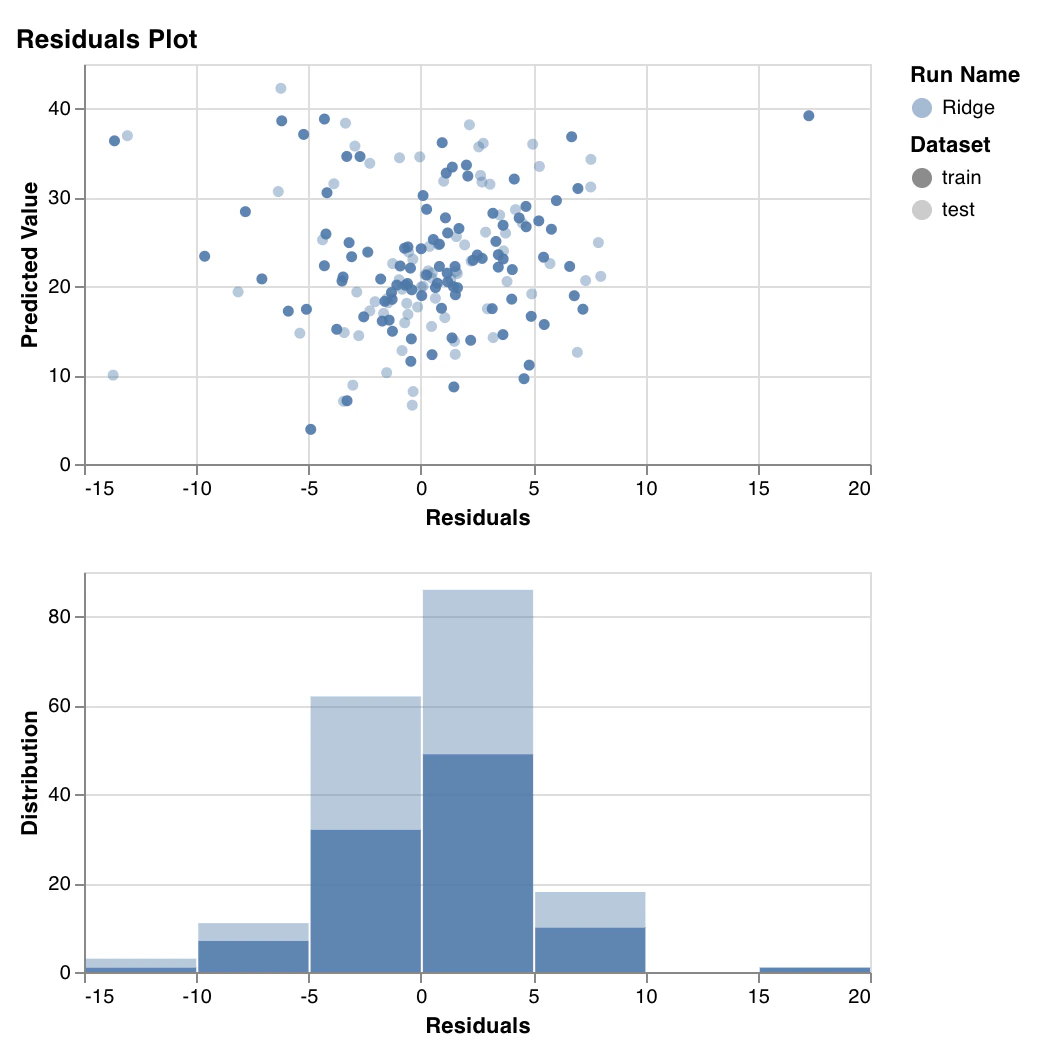
wandb.sklearn.plot_residuals(model, X, y)
- model (regressor): Prend un régresseur ajusté.
- X (arr): Fonctionnalités de l’ensemble d’entraînement.
- y (arr): Étiquettes de l’ensemble d’entraînement. Si vous avez des questions, nous serons ravis d’y répondre dans notre communauté Slack.
Exemple
- Exécuter sur Colab : un notebook simple pour bien démarrer.