- Créer et utiliser un W&B Artifact.
- Utiliser et créer des Registered Models dans W&B Registry.
- Exécuter des tâches d’entraînement sur une infrastructure dédiée à l’aide de W&B Launch.
- Utiliser le client wandb dans les ops et les assets.
wandb_resource: une ressource Dagster utilisée pour s’authentifier auprès de l’API W&B et communiquer avec elle.wandb_artifacts_io_manager: un IO Manager Dagster utilisé pour consommer des W&B Artifacts.
Avant de commencer
- Clé API W&B.
- entité W&B (utilisateur ou équipe) : une entité est un nom d’utilisateur ou un nom d’équipe auquel vous envoyez des Runs et des Artifacts W&B. Assurez-vous de créer votre compte ou votre entité d’équipe dans l’interface de l’application W&B avant d’enregistrer des runs. Si vous ne spécifiez pas d’entité, le run sera envoyé à votre entité par défaut, qui correspond généralement à votre nom d’utilisateur. Modifiez votre entité par défaut dans vos paramètres, sous Valeurs par défaut du projet.
- projet W&B : le nom du projet dans lequel les Runs W&B sont stockés.
Configurer votre clé API
- Connectez-vous à W&B. Remarque : si vous utilisez W&B Server, demandez à votre administrateur le nom d’hôte de l’instance.
- Créez une clé API dans les Paramètres utilisateur. Pour un environnement de production, nous vous recommandons d’utiliser un compte de service comme propriétaire de cette clé.
- Définissez une variable d’environnement pour cette clé API :
export WANDB_API_KEY=YOUR_KEY.
wandb_config. Vous pouvez transmettre des valeurs wandb_config différentes à différentes ops/assets si vous souhaitez utiliser un autre projet W&B. Pour plus d’informations sur les clés que vous pouvez transmettre, voir la section Configuration ci-dessous.
- Configuration pour @job
- Configuration pour @repository avec des assets
Exemple : configuration pour
@jobConfiguration
wandb_resource: ressource Dagster utilisée pour communiquer avec l’API W&B. Elle s’authentifie automatiquement à l’aide de la clé API fournie. Propriétés :api_key: (str, requis) : une clé API W&B nécessaire pour communiquer avec l’API W&B.host: (str, facultatif) : le serveur hôte de l’API que vous souhaitez utiliser. Requis uniquement si vous utilisez W&B Server. Par défaut, l’hôte Public Cloudhttps://api.wandb.aiest utilisé.
wandb_artifacts_io_manager: IO Manager Dagster permettant de consommer des W&B Artifacts. Propriétés :base_dir: (int, facultatif) Répertoire de base utilisé pour le stockage local et la mise en cache. Les W&B Artifacts et les journaux des Runs W&B seront écrits dans ce répertoire et lus depuis celui-ci. Par défaut, le répertoireDAGSTER_HOMEest utilisé.cache_duration_in_minutes: (int, facultatif) permet de définir la durée pendant laquelle les W&B Artifacts et les journaux des Runs W&B doivent être conservés dans le stockage local. Seuls les fichiers et répertoires qui n’ont pas été ouverts pendant cette durée sont supprimés du cache. La purge du cache a lieu à la fin de l’exécution de l’IO Manager. Vous pouvez définir cette valeur sur 0 si vous souhaitez désactiver complètement la mise en cache. La mise en cache accélère l’exécution lorsqu’un Artifact est réutilisé entre des jobs exécutés sur la même machine. La valeur par défaut est de 30 jours.run_id: (str, facultatif) : un ID unique pour ce run, utilisé pour la reprise. Il doit être unique dans le projet, et si vous supprimez un run, vous ne pouvez pas réutiliser cet ID. Utilisez le champ name pour un nom descriptif court, ou config pour enregistrer des hyperparamètres à comparer entre les runs. L’ID ne peut pas contenir les caractères spéciaux suivants :/\#?%:..Vous devez définir le Run ID lorsque vous effectuez un suivi des expériences dans Dagster afin de permettre à l’IO Manager de reprendre le run. Par défaut, il est défini sur le Dagster Run ID, par exemple7e4df022-1bf2-44b5-a383-bb852df4077e.run_name: (str, facultatif) Un nom d’affichage court pour ce run afin de vous aider à l’identifier dans l’UI. Par défaut, il s’agit d’une chaîne au format suivant :dagster-run-[8 premiers caractères du Dagster Run ID]. Par exemple,dagster-run-7e4df022.run_tags: (list[str], facultatif) : une liste de chaînes qui alimentera la liste des tags de ce run dans l’UI. Les tags sont utiles pour regrouper des runs ou appliquer des étiquettes temporaires commebaselineouproduction. Il est facile d’ajouter et de supprimer des tags dans l’UI, ou de filtrer pour n’afficher que les runs ayant un tag spécifique. Tout W&B Run utilisé par l’intégration aura le tagdagster_wandb.
Utiliser les W&B Artifacts
@op ou @asset Dagster de créer et de consommer des W&B Artifacts de manière native. Voici un exemple simple d’un @asset qui produit un W&B Artifact de type jeu de données contenant une liste Python.
@op, @asset et @multi_asset avec une configuration de métadonnées pour écrire des Artifacts. De même, vous pouvez également consommer des W&B Artifacts même s’ils ont été créés en dehors de Dagster.
Écrire des W&B Artifacts
- Objets Python (int, dict, list…)
- Objets W&B (Table, Image, Graph…)
- Objets W&B Artifact
@asset) :
- Objets Python
- Objet W&B
- W&B Artifact
Tout ce qui peut être sérialisé avec le module pickle est sérialisé avec pickle et ajouté à un Artifact créé par l’intégration. Le contenu est désérialisé lorsque vous lisez cet Artifact dans Dagster (voir Lire les artifacts pour plus de détails).W&B prend en charge plusieurs modules de sérialisation basés sur Pickle (pickle, dill, cloudpickle, joblib). Vous pouvez également utiliser des formats de sérialisation plus avancés comme ONNX ou PMML. Pour en savoir plus, consultez la section Serialization.
Configuration
@op, @asset et @multi_asset. Ce dictionnaire doit être transmis dans les arguments du décorateur en tant que métadonnées. Cette configuration est requise pour contrôler les lectures et écritures de l’IO Manager de W&B Artifacts.
Pour @op, il se trouve dans les métadonnées de sortie via l’argument de métadonnées Out.
Pour @asset, il se trouve dans l’argument metadata de l’asset.
Pour @multi_asset, il se trouve dans les métadonnées de chaque sortie via les arguments de métadonnées AssetOut.
Les exemples de code ci-dessous montrent comment configurer un dictionnaire pour des calculs @op, @asset et @multi_asset :
- Exemple pour @op
- Exemple pour @asset
- Exemple pour @multi_asset
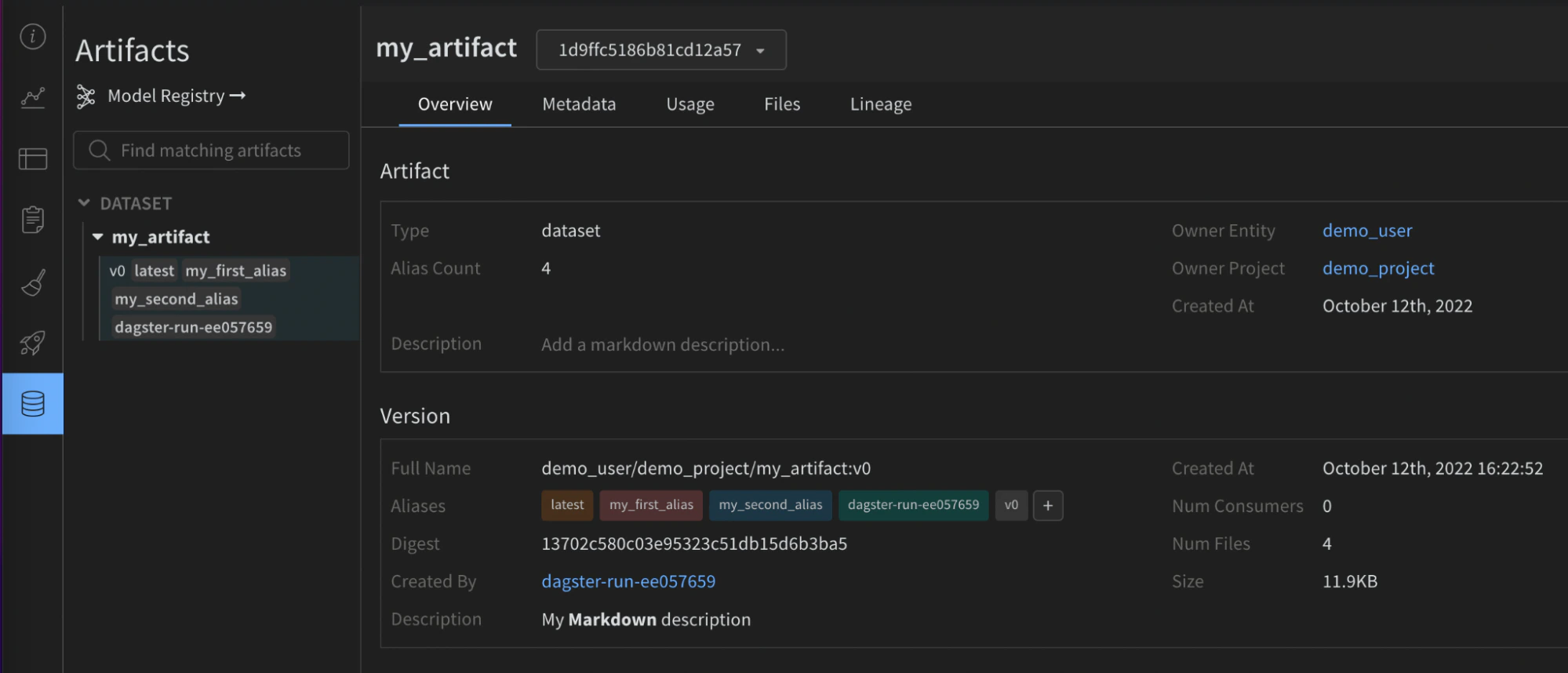
Exemple pour
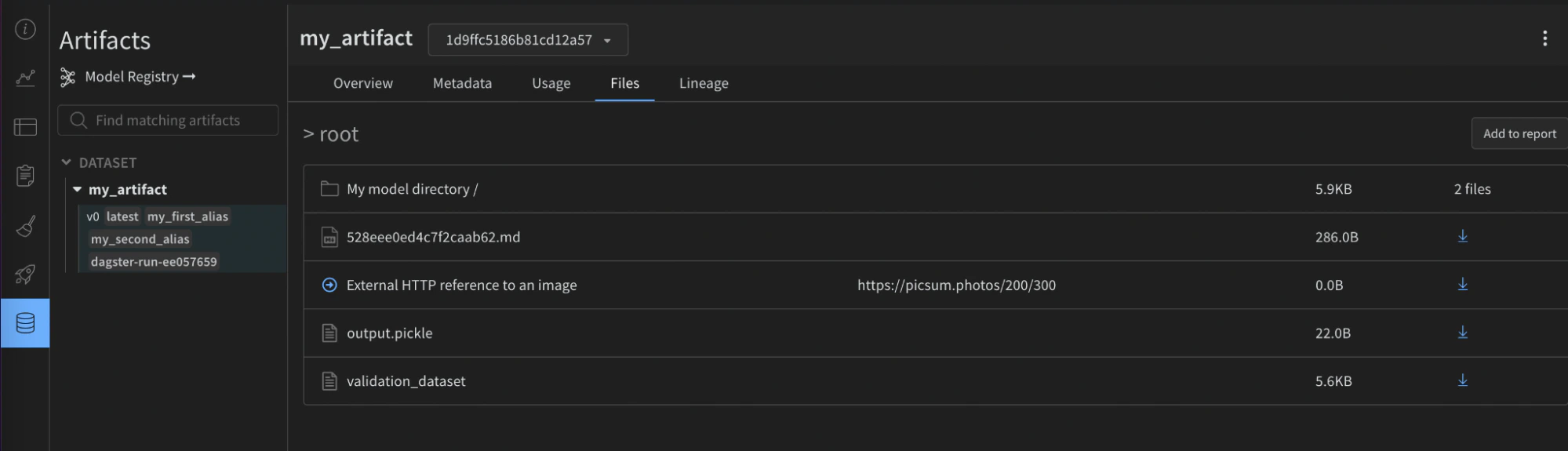
@op :name: (str) nom lisible par l’humain pour cet artifact, ce qui vous permet d’identifier cet artifact dans l’UI ou d’y faire référence dans les appelsuse_artifact. Les noms peuvent contenir des lettres, des chiffres, des underscores, des traits d’union et des points. Le nom doit être unique à l’échelle d’un projet. Requis pour@op.type: (str) type de l’artifact, utilisé pour organiser et différencier les artifacts. Les types courants incluent les jeux de données ou les modèles, mais vous pouvez utiliser n’importe quelle chaîne contenant des lettres, des chiffres, des underscores, des traits d’union et des points. Requis lorsque la sortie n’est pas déjà un Artifact.description: (str) Texte libre qui décrit l’artifact. La description est interprétée en markdown dans l’UI, c’est donc un bon endroit pour ajouter des tableaux, des liens, etc.aliases: (list[str]) Un tableau contenant un ou plusieurs alias que vous souhaitez appliquer à l’Artifact. L’intégration ajoutera également le tag “latest” à cette liste, qu’il soit défini ou non. C’est un moyen efficace de gérer les versions des modèles et des jeux de données.add_dirs: (list[dict[str, Any]]): Un tableau contenant la configuration de chaque répertoire local à inclure dans l’Artifact.add_files: (list[dict[str, Any]]): Un tableau contenant la configuration de chaque fichier local à inclure dans l’Artifact.add_references: (list[dict[str, Any]]): Un tableau contenant la configuration de chaque référence externe à inclure dans l’Artifact.serialization_module: (dict) Configuration du module de sérialisation à utiliser. Se référer à la section Serialization pour plus d’informations.name: (str) Nom du module de sérialisation. Valeurs acceptées :pickle,dill,cloudpickle,joblib. Le module doit être disponible localement.parameters: (dict[str, Any]) Arguments facultatifs transmis à la fonction de sérialisation. Elle accepte les mêmes paramètres que la méthodedumpde ce module. Par exemple,{"compress": 3, "protocol": 4}.
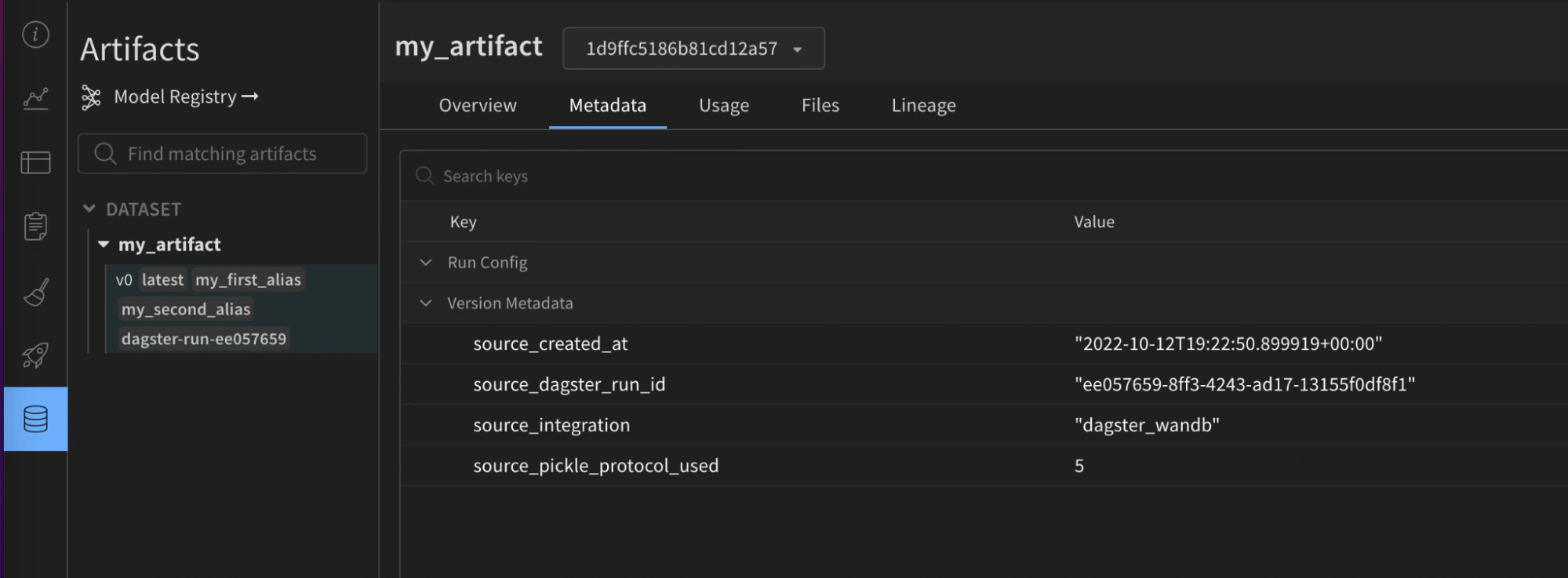
- Côté W&B : le nom et la version de l’intégration source, la version de Python utilisée, la version du protocole pickle, entre autres.
- Côté Dagster :
- ID du run Dagster
- Run W&B : ID, nom, chemin, URL
- W&B Artifact : ID, nom, type, version, taille, URL
- Entité W&B
- Projet W&B
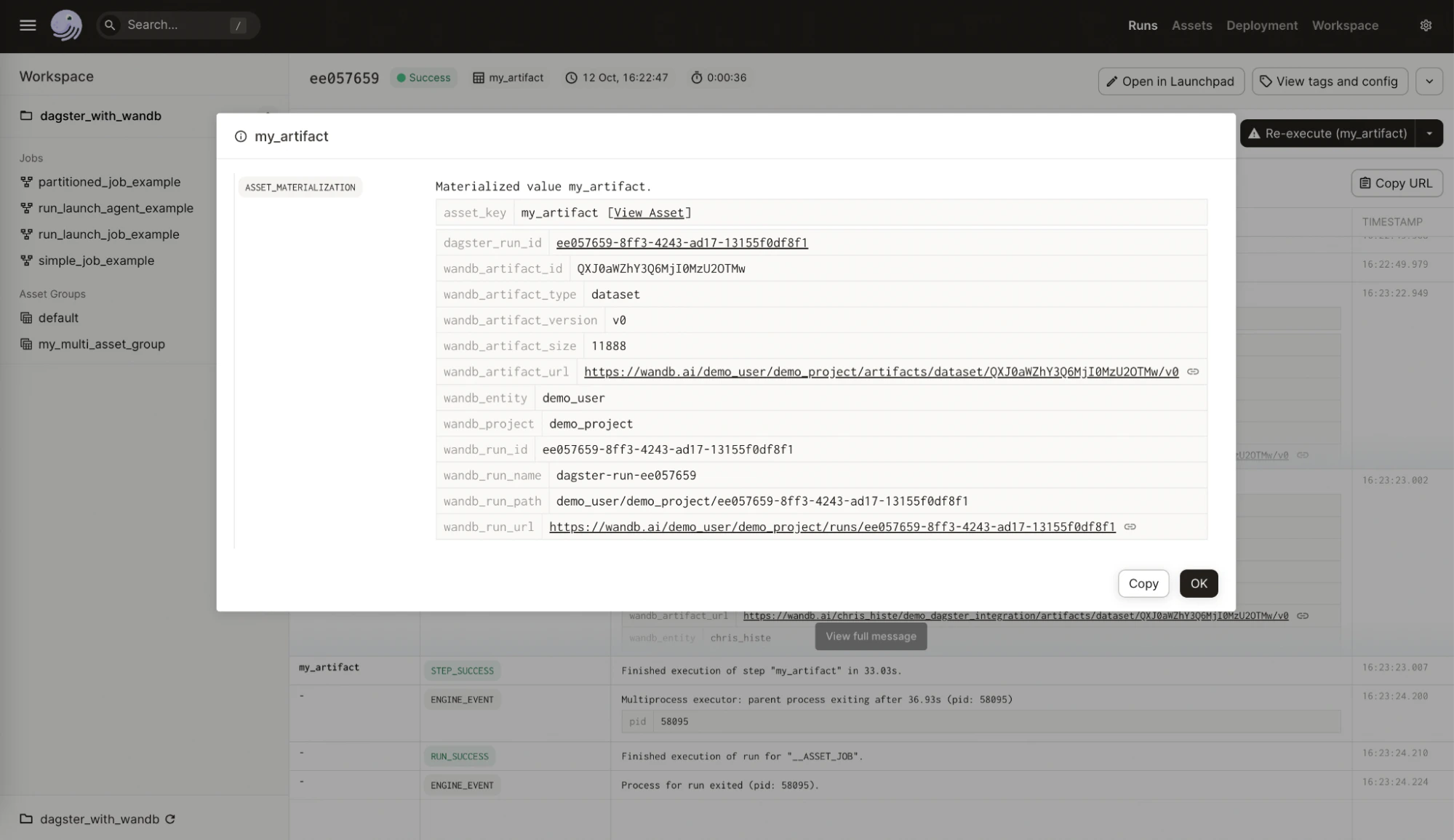
Si vous utilisez un vérificateur de types statique comme mypy, importez l’objet de définition du type de configuration comme suit :
Utiliser les partitions
L’intégration prend nativement en charge les partitions Dagster. Voici un exemple de partitionnement avecDailyPartitionsDefinition.
my_daily_partitioned_asset.2023-01-01, my_daily_partitioned_asset.2023-01-02 ou my_daily_partitioned_asset.2023-01-03. Les assets partitionnés sur plusieurs dimensions affichent chaque dimension dans un format délimité par des points. Par exemple, my_asset.car.blue.
L’intégration ne permet pas de matérialiser plusieurs partitions au sein d’un même run. Vous devrez effectuer plusieurs runs pour matérialiser vos assets. Vous pouvez le faire dans Dagit lorsque vous matérialisez vos assets.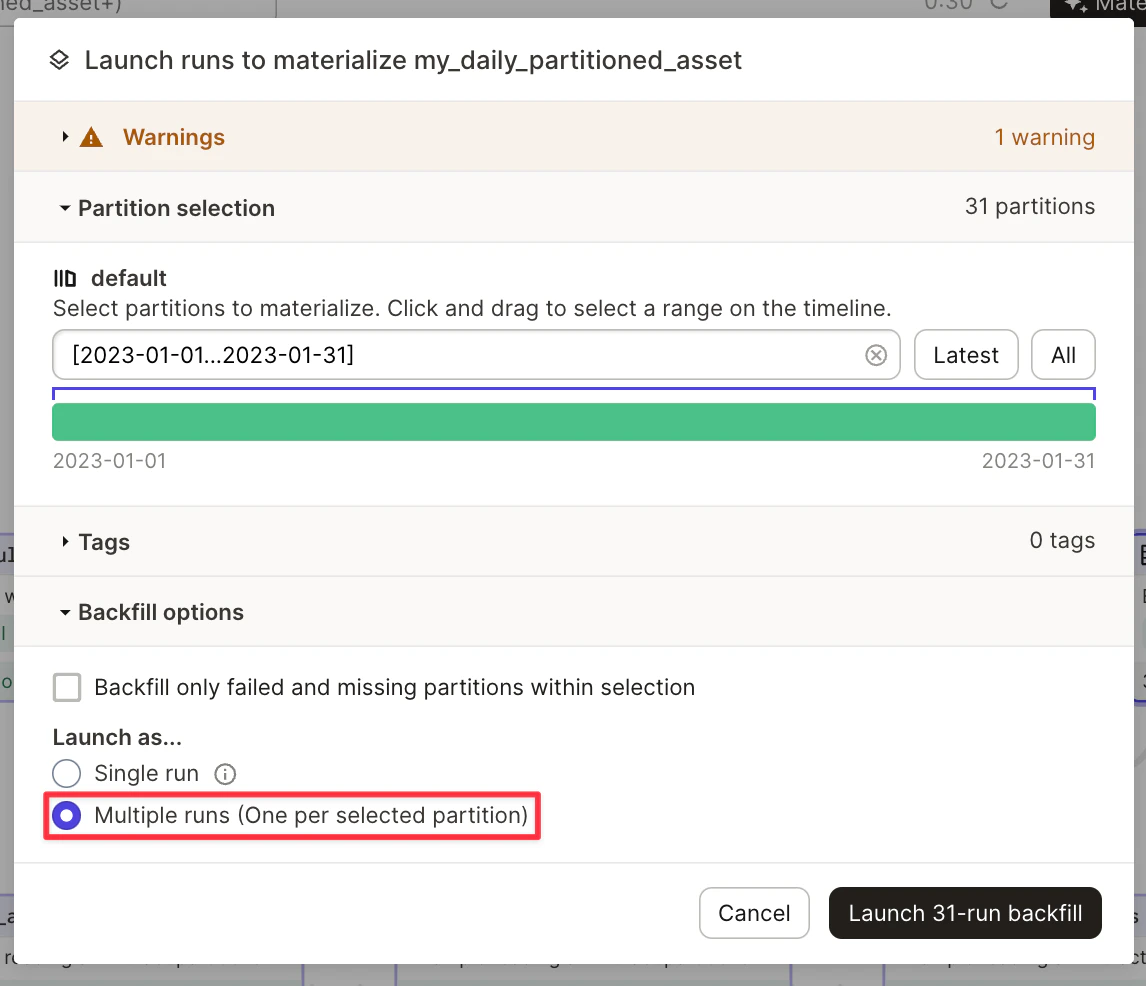
Utilisation avancée
- job partitionné
- asset partitionné simple
- asset partitionné multi-dimensionnel
- Utilisation avancée du partitionnement
Lire W&B Artifacts
wandb_artifact_configuration peut être défini sur un @op ou un @asset. La seule différence est que la configuration doit être définie sur l’entrée plutôt que sur la sortie.
Pour @op, elle se trouve dans les métadonnées d’entrée via l’argument de métadonnées In. Vous devez
indiquer explicitement le nom de l’Artifact.
Pour @asset, elle se trouve dans les métadonnées d’entrée via l’argument de métadonnées Asset In. Vous ne devez pas transmettre de nom d’Artifact, car le nom de l’asset parent doit correspondre.
Si vous souhaitez créer une dépendance sur un Artifact créé en dehors de l’intégration, vous devrez utiliser SourceAsset. Il lira toujours la dernière version de cet asset.
Les exemples suivants montrent comment lire un Artifact à partir de différents ops.
- Depuis un @op
- Créé par un autre @asset
- Artifact créé en dehors de Dagster
Lecture d’un artifact à partir d’un
@opConfiguration
- Pour obtenir un objet nommé contenu dans un Artifact, utilisez
get:
- Pour obtenir le chemin local d’un fichier téléchargé présent dans un Artifact, utilisez get_path :
- Pour obtenir l’objet Artifact dans son intégralité (avec le contenu téléchargé localement) :
get: (str) Obtient l’objet W&B correspondant au nom relatif de l’artifact.get_path: (str) Obtient le chemin du fichier correspondant au nom relatif de l’artifact.
Configuration de la sérialisation
yield génèrent une erreur si vous essayez de les sérialiser avec pickle.
Nous prenons également en charge d’autres modules de sérialisation basés sur Pickle (dill, cloudpickle, joblib). Vous pouvez aussi utiliser des méthodes de sérialisation plus avancées comme ONNX ou PMML, en renvoyant une chaîne sérialisée ou en créant directement un Artifact. Le choix le plus adapté dépend de votre cas d’usage ; veuillez vous référer à la documentation disponible sur ce sujet.
Modules de sérialisation basés sur pickle
serialization_module dans wandb_artifact_configuration. Assurez-vous que le module est disponible sur la machine exécutant Dagster.
L’intégration saura automatiquement quel module de sérialisation utiliser lorsque vous lirez cet Artifact.
Les modules actuellement pris en charge sont pickle, dill, cloudpickle et joblib.
Voici un exemple simplifié dans lequel nous créons un « modèle » sérialisé avec joblib, puis l’utilisons pour l’inférence.
Formats de sérialisation avancés (ONNX, PMML)
- Convertissez votre modèle dans le format sélectionné, puis renvoyez sa représentation sous forme de chaîne comme s’il s’agissait d’un objet Python ordinaire. L’intégration sérialisera cette chaîne avec pickle. Vous pourrez ensuite reconstruire votre modèle à partir de cette chaîne.
- Créez un nouveau fichier local contenant votre modèle sérialisé, puis créez un Artifact personnalisé avec ce fichier à l’aide de la configuration add_file.
Utilisation des partitions
- Lire toutes les partitions
- Lire des partitions spécifiques
Cet exemple lit toutes les partitions de l’
@asset amont, fournies sous forme de dictionnaire. Dans ce dictionnaire, la clé et la valeur correspondent respectivement à la clé de partition et au contenu de l’Artifact.metadata détermine comment W&B interagit avec les différentes partitions d’artifact dans votre projet.
L’objet metadata contient une clé nommée wandb_artifact_configuration, qui contient elle-même un objet imbriqué partitions.
L’objet partitions associe le nom de chaque partition à sa configuration. La configuration de chaque partition peut préciser comment récupérer ses données. Ces configurations peuvent contenir différentes clés, à savoir get, version et alias, selon les exigences de chaque partition.
Clés de configuration
get: La clégetspécifie le nom de l’objet W&B (Table, Image…) depuis lequel récupérer les données.version: La cléversionest utilisée lorsque vous souhaitez récupérer une version spécifique de l’Artifact.alias: La cléaliasvous permet d’obtenir l’Artifact via son alias.
"*" désigne toutes les partitions non configurées. Il fournit une configuration par défaut pour les partitions qui ne sont pas explicitement mentionnées dans l’objet partitions.
Par exemple,
default_table_name.
Configuration spécifique de partition
Vous pouvez remplacer la configuration générique pour certaines partitions en fournissant leur propre configuration à l’aide de leur clé.
Par exemple,
yellow, les données seront récupérées depuis la table nommée custom_table_name, en remplaçant la configuration générique.
Gestion des versions et des alias
À des fins de gestion des versions et des alias, vous pouvez spécifier des clés version et alias spécifiques dans votre configuration.
Pour les versions,
orange en version v0.
Pour les alias,
default_table_name de la partition Artifact avec l’alias special_alias (désigné par blue dans la configuration).
Utilisation avancée
Pour consulter des cas d’utilisation avancée de l’intégration, se référer aux exemples de code complets suivants :- Exemple d’utilisation avancée pour les assets
- Exemple de job partitionné
- Associer un modèle au registre de modèles
Utiliser W&B Launch
- Exécuter un ou plusieurs agents Launch dans votre instance Dagster.
- Exécuter des jobs Launch locaux dans votre instance Dagster.
- Exécuter des jobs Launch à distance, sur site ou dans le cloud.
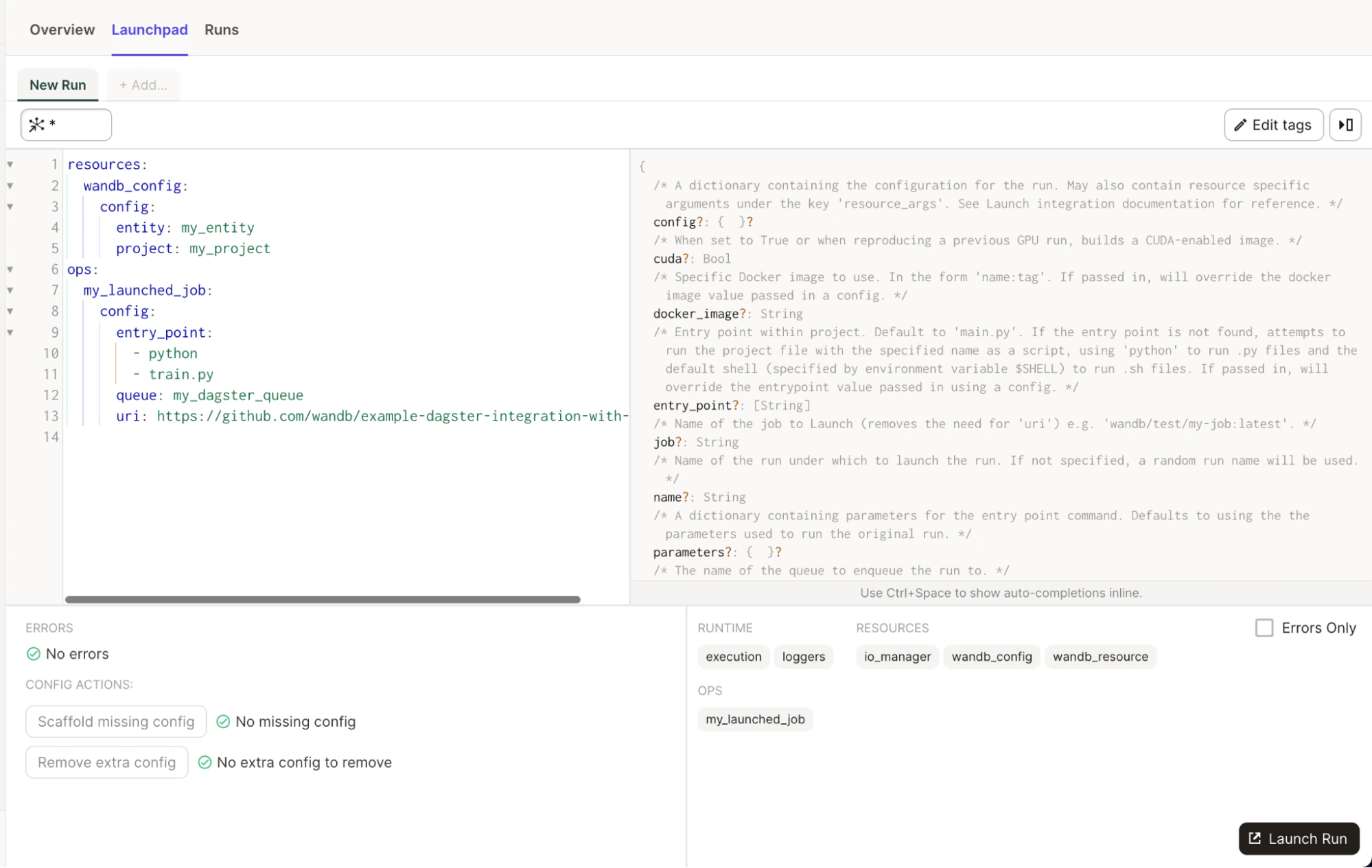
agent Launch
@op importable appelé run_launch_agent. Il démarre un agent Launch et l’exécute comme un processus de longue durée jusqu’à ce qu’il soit arrêté manuellement.
Les agents sont des processus qui interrogent les files d’attente de Launch et exécutent les jobs dans l’ordre (ou les transmettent à des services externes pour exécution).
Référez-vous à la page Launch.
Vous pouvez également consulter des descriptions utiles pour toutes les propriétés dans Launchpad.
Jobs Launch
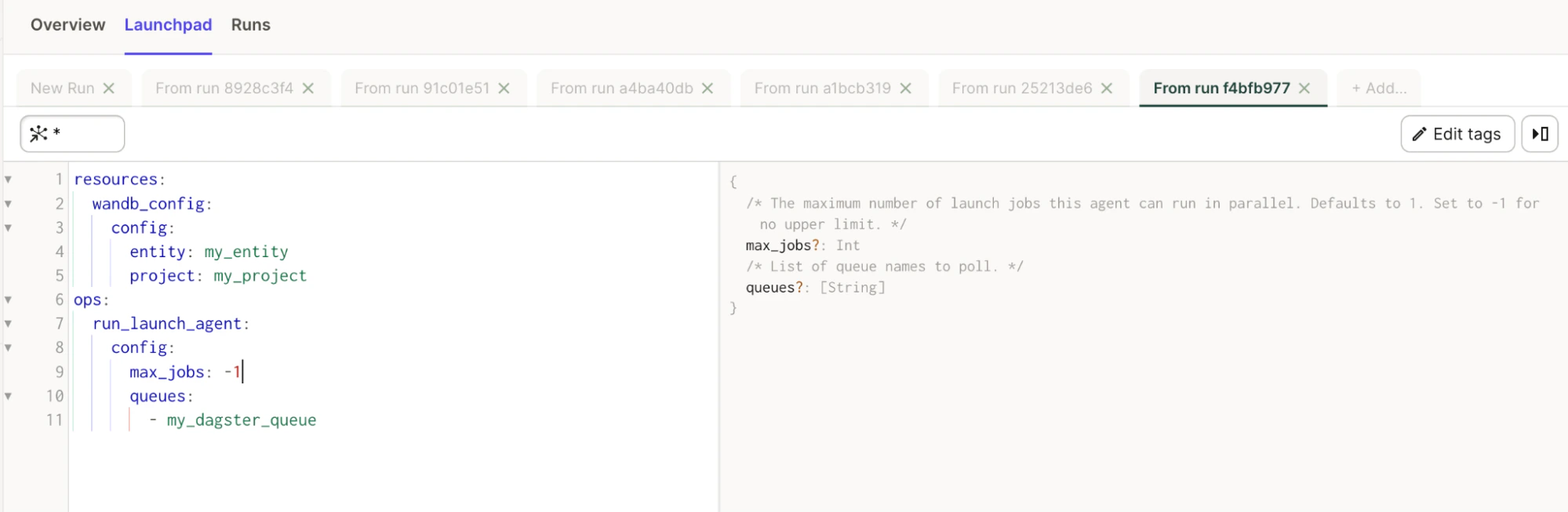
@op importable appelé run_launch_job. Il exécute votre job Launch.
Pour être exécuté, un job Launch doit être assigné à une file d’attente. Vous pouvez créer une file d’attente ou utiliser celle par défaut. Assurez-vous qu’un agent actif écoute cette file d’attente. Vous pouvez exécuter un agent dans votre instance Dagster, mais vous pouvez aussi envisager d’utiliser un agent déployable sur Kubernetes.
Consultez la page Launch.
Vous pouvez également consulter dans Launchpad des descriptions utiles pour toutes les propriétés.
Bonnes pratiques
-
Utilisez l’IO Manager pour lire et écrire des Artifacts.
Évitez d’utiliser directement
Artifact.download()ouRun.log_artifact(). Ces méthodes sont prises en charge par l’intégration. Renvoyez plutôt les données que vous souhaitez stocker dans l’Artifact et laissez l’intégration faire le reste. Cette approche offre une meilleure traçabilité pour l’Artifact. - Ne créez vous-même un objet Artifact que pour des cas d’usage complexes. Les objets Python et les objets W&B doivent être renvoyés depuis vos ops/assets. L’intégration se charge d’assembler l’Artifact. Pour les cas d’usage complexes, vous pouvez créer un Artifact directement dans un job Dagster. Nous vous recommandons de transmettre un objet Artifact à l’intégration pour enrichir les métadonnées, par exemple avec le nom et la version de l’intégration source, la version de Python utilisée, la version du protocole pickle, etc.
-
Ajoutez des fichiers, des répertoires et des références externes à vos Artifacts via les métadonnées.
Utilisez l’objet d’intégration
wandb_artifact_configurationpour ajouter des fichiers, des répertoires ou des références externes (Amazon S3, GCS, HTTP…). Voir l’exemple avancé dans la section de configuration de l’Artifact pour plus d’informations. - Utilisez un @asset plutôt qu’un @op lorsqu’un Artifact est produit. Les Artifacts sont des assets. Il est recommandé d’utiliser un asset lorsque Dagster gère cet asset. Cela offre une meilleure observabilité dans le catalogue d’assets de Dagit.
- Utilisez un SourceAsset pour consommer un Artifact créé en dehors de Dagster. Cela vous permet de tirer parti de l’intégration pour lire des Artifacts créés hors de Dagster. Sinon, vous ne pouvez utiliser que les Artifacts créés par l’intégration.
- Utilisez W&B Launch pour orchestrer l’entraînement sur des ressources de calcul dédiées pour les grands modèles. Vous pouvez entraîner de petits modèles dans votre cluster Dagster, et exécuter Dagster dans un cluster Kubernetes avec des nœuds GPU. Nous vous recommandons d’utiliser W&B Launch pour l’entraînement de grands modèles. Cela évite de surcharger votre instance et donne accès à des ressources de calcul plus adaptées.
- Lors du suivi des expériences dans Dagster, définissez votre ID de run W&B sur la valeur de votre ID de run Dagster. Nous vous recommandons de faire les deux : rendre le Run reprenable et définir l’ID de run W&B sur l’ID de run Dagster ou sur la chaîne de votre choix. En suivant cette recommandation, vous vous assurez que vos métriques W&B et vos Artifacts W&B sont stockés dans le même Run W&B lorsque vous entraînez des modèles dans Dagster.
- Ne collectez que les données dont vous avez besoin avec get ou get_path pour les W&B Artifacts volumineux. Par défaut, l’intégration télécharge l’intégralité d’un Artifact. Si vous utilisez des artifacts très volumineux, vous pouvez ne collecter que les fichiers ou objets spécifiques dont vous avez besoin. Cela améliorera la vitesse et l’utilisation des ressources.
- Pour les objets Python, adaptez le module de pickling à votre cas d’utilisation. Par défaut, l’intégration W&B utilise le module standard pickle. Mais certains objets ne sont pas compatibles avec celui-ci. Par exemple, les fonctions qui utilisent yield génèrent une erreur si vous essayez de les sérialiser avec pickle. W&B prend en charge d’autres modules de sérialisation basés sur Pickle (dill, cloudpickle, joblib).